Introduction
Rust
资料
0. book
- Rust book 官方教程
- Rust 死灵书 官方Rust死灵书,主要是如何何撰写和使用 unsafe Rust
- Rust标准库 标准库
- Rustlings 小练习, 用来夯实对知识和概念的理解
- This week in Rust
- Rust 语言开源杂志 每月一期, 囊括了大量优秀的 Rust 文章
- Beginner’s Series to: Rust 微软推出的一系列Rust培训
- Comprehensive Rust google 出品
- The Rustonomicon unsafe rust
- Jon Gjengset 大佬youtube, 他的视频面向中高级 Rust 用户, 适合学习完本课程后再去观看
- cheat rs Rust Language Cheat Sheet
- Rust for Rustaceans Rust for Rustaceans
- Rust Atomics and Locks
1. 工具
-
代码安全
- cargo-tarpaulin 代码覆盖率
- clippy 代码检查
- cargo-audit
Cargo.lock安全审核 - cargo-flamegraph 在跟踪代码中的性能热点时给了我们巨大的帮助.
- cargo-geiger 帮助我们快速评估外部依赖, 以解决可能的安全性 (或正确性) 问题.
- cargo tree (最近集成进了 cargo) 显示了一个依赖树, 它在许多方面都很有用, 但主要用于找出最小化依赖项的途径
- cargo-udeps 可以识别未使用的依赖项, 并尽可能减少我们的构建时间
- cargo-deny 检查依赖
-
调试工具
-
编译
- cargo-watch 即时编译
- sccache sccache is ccache with cloud storage, Shared Compilation Cache
-
平台编译打包
- cross 零设置的跨平台 交叉编译和交叉测试
- cargo-deb 打包成.deb
- cargo-generate-rpm 打包成rpm
- cargo-aur 打包成 Arch Linux User Repository
2. crate
mini-sized-rustHow to minimize Rust binary sizepassword-hashedPassword hashing functions / KDFstracingApplication level tracing for Rust.pestThe Elegant ParsernomRust parser combinator frameworkpolarsFast multi-threaded, hybrid-streaming DataFrame library in Rust | Python | Node.jsr2d2A generic connection pool for Rust
3. 建议
3.1 密码建议
- 如果
Argon2id可用, 那么使用Argon2id(需要目标机器至少有 15MB 内存) . - 如果
Argon2id不可用, 那么使用bcrypt(算法至少迭代 10 次) . - 最后再考虑
scrypt/PBKDF2.
内存模型
类型的布局是其大小 (size) 、对齐方式 (align) 及其字段的相对偏移量. 对于枚举, 如何布局和解释判别式也是类型布局的一部分. 对于 Sized 的数据类型, 可以在编译时知道内存布局, 可以通过 size_of 和 align_of 获得其 size 和 align.
The layout of a type is its size, alignment, and the relative offsets of its fields.
For enums, how the discriminant is laid out and interpreted is also part of type layout.
Type layout can be changed with each compilation.
Note: 本文内存模型不考虑优化,是广文上的模型,实际中 Rust会对一些数据类型做优化.
1. 整型
| Type | size(bytes) | align(bytes) |
|---|---|---|
u8 | 1 | 1 |
i8 | 1 | 1 |
u16 | 2 | 2 |
i16 | 2 | 2 |
u32 | 4 | 4 |
i32 | 4 | 4 |
i64 | 8 | 8 |
u64 | 8 | 8 |
i128 | 16 | 16 |
u128 | 16 | 16 |
2. 浮点型
The IEEE 754-2008 “binary32” and “binary64” floating-point types are f32 and f64, respectively.
| Type | size(bytes) | align(bytes) |
|---|---|---|
f32 | 4 | 4 |
f64 | 8 | 8 |
3. usized & isized
| Type | size(bytes)/ 32位系统 | size(bytes)/ 64位系统 |
|---|---|---|
usize | 4 | 8 |
isize | 4 | 8 |
4. str
4.1 char 类型
char表示:一个 32 位(4 Bytes)长度字符, Unicode 标量值 Unicode Scalar Value 范围为 0x0000 - 0xD7FF 或者是 0xE000 - 0x10FFFF.
4.2 str 类型
str 与 [u8] 一样表示一个 u8 的 slice. Rust 中标准库中对 str 有个假设:符合 UTF-8 编码. 内存布局与 [u8] 相同.
5. & 和&[T] 引用
5.1 &
#![allow(unused)]
fn main() {
let a: i32 = 25;
let b: &i32 = &a;
let c: &&i32 = &b;
stack
| a | | b | │ c │
+––––+––––+––––+––––+––––+
│ 25 │ │ * │ │ * │
+––^–+––––+–│^–+––––+–│––+
│ │|________|
│________│
}5.2 &[T] slice 引用
slice 的使用必须要通过指针, &[T] 是一个胖指针, 保存指向数据的地址和元素个数. slice 的内存布局与其指向的 array 部分相同.
#![allow(unused)]
fn main() {
// array &[T]
let a:[i32;3] = [55,66,77];
let b:&[i32] = &a[..2]
stack [–––– a ––––| |––– b ––|
+––––+––––+––––+–––+––––+––––+
│ 55 │ 66 │ 77 │ | * | 2 |
+––––+––––+––––+–––+––––+––––+
| | / /
–––––––––––<––––––––/ /
/ length
buffer point
}#![allow(unused)]
fn main() {
// Vec<T> &[T]
let a:Vec<i32> = vec![55,66,77];
let b:&[i32] = &a[..2]
stack [––– a ––| |––– b ––|
+–––+–––+–––+ +––––+––––+
│ • │ 3 │ 4 │ | * | 2 |
+–│–+–––+–––+ +–│––+––––+
│ │
heap │ │
+–V––+––––+––––+ │
│ 55 │ 66 │ 77 │ │
+––––+––––+––––+ │
| │ │
–––––––––––<––––––––/
}6. &str,str 和 String 的区别
6.1 String
#![allow(unused)]
fn main() {
String: let s: String = String::from("hello");
buffer point
/ capacity
/ / length
stack / / /
+–––+–––+–––+
│ • │ 8 │ 5 │
+–│–+–––+–––+
│
heap │
+–V–+–––+–––+–––+–––+–––+–––+–––+
│ h │ e │ l │ l │ o │ │ │ │
+–––+–––+–––+–––+–––+–––+–––+–––+
[––––––– length ––––]
[–-–––––––– capacity –––––––––––]
}6.2 str和&str
#![allow(unused)]
fn main() {
&str: let s: &str = "hello";
buffer point
/ length
stack / /
+–––+–––+
│ • │ 5 │ &str
+–│–+–––+
│
read-only │
memory │
[–│–––––– str ––––––]
+–V–+–––+–––+–––+–––+
│ h │ e │ l │ l │ o │
+–––+–––+–––+–––+–––+
}7. tuple
#![allow(unused)]
fn main() {
let a: (char, u8, i32) = ('a', 7, 356)
stack
[–––––––––––––– 12 Bytes –––––––––––––––––––|
+–––––––––––––+–––––+–––––––––+–––––––––––––+
│ 'a' │ 7 │ padding │ 356 │
+–––––––––––––+–––––+–––––––––+–––––––––––––+
|–– 4 Bytes ––| 4 Bytes |–– 4 Bytes ––|
}8. struct
结构体是带命名的复合类型, rust有三种结构体类型: struct, StructExprStruct,StructExprUnit
8.1 struct 含有字段的结构体
#![allow(unused)]
fn main() {
struct Data {
nums: Vec<u8>,
a: u8,
}
stack [––– nums ––|– a –]
+–––+–––+–––+–––––+
│ • │ 8 │ 5 │ 10 |
+–│–+–––+–––+–––––+
│
heap │
+–V–+–––+–––+–––+–––+–––+–––+–––+
│ 0 │ 0 │ 0 │ 0 │ 0 │ │ │ │
+–––+–––+–––+–––+–––+–––+–––+–––+
}8.2 StructExprTuple 元组结构体
#![allow(unused)]
fn main() {
struct Data(i32, i32, i32);
stack [––– Data ––|
+–––+–––+–––+
│ 1 │ 2 │ 3 │
+–––+–––+–––+
}8.3 StructExprUnit 单元结构体
单元结构体没有任何数据,所以Rust编译器甚至不会为它分配任何内存.
#![allow(unused)]
fn main() {
struct Data;
}9. enum
9.1 C风格枚举
#![allow(unused)]
fn main() {
// 占一个字节
enum HTTPStatus {
Ok;
NotFound,
}
HTTPStatus::Ok
stack
+–––+
│ 0 │
+–––+
HTTPStatus::NotFound
stack
+–––+
│ 1 │
+–––+
}9.2 C风格指定值枚举
#![allow(unused)]
fn main() {
// 占两个字节
enum HTTPStatus {
Ok = 200;
NotFound = 404,
}
HTTPStatus::Ok
stack
+–––––+
│ 200 │
+–––––+
HTTPStatus::NotFound
stack
+–––––+
│ 404 │
+–––––+
}9.3 变体枚举
#![allow(unused)]
fn main() {
enum Data {
Empty;
Number(i32),
Array(Vec<i32>),
}
stack
Data::Empty
+–––––+––––––––––––––––––––––––––––––––––––––––––––––+
│ 0 │ padding │
+–––––+––––––––––––––––––––––––––––––––––––––––––––––+
| mark|
Data::Number
+–––––+–––––––––+–––––––––––+––––––––––––––––––––––––+
│ 1 │ padding │ 0 │ padding │
+–––––+–––––––––+–––––––––––+––––––––––––––––––––––––+
| mark| |–– i32 –––|
|–– value ––|
Data::Array(Vec<i32>)
[––––––––––––––––––––– 32 Bytes –––––––––––––––––––––|
+–––––+–––––––––+–––––––––––+––––––––––––+–––––––––––+
│ 2 │ padding │ none │ 0 │ 0 │
+–––––+–––––––––+–––––––––––+––––––––––––+–––––––––––+
| mark| |––––––––––––– Vec<i32> ––––––––––––|
|– pointer –|– capacity –|– length –|
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
enum Data {
Empty;
Number(i32),
Array(Box<Vec<i32>>),
}
stack
Data::Empty
+–––––+–––––––––––––––––––––+
│ 0 │ padding │
+–––––+–––––––––––––––––––––+
| mark|
Data::Number
+–––––+–––––––––+–––––––––––+
│ 1 │ padding │ 0 │
+–––––+–––––––––+–––––––––––+
| mark| |–– i32 –––|
|–– value ––|
Data::Array(Vec<i32>)
[––––––– 16 Bytes ––––––––––|
+–––––+–––––––––+–––––––––––+
│ 2 │ padding │ * │
+–––––+–––––––––+––│––––––––+
| mark| |– │ Box<T>–|
|– │ pointer|
│
heap V
+–––––––––––+––––––––––––+–––––––––––+
│ none │ 0 │ 0 │
+–––––––––––+––––––––––––+–––––––––––+
}9.4 Option<T>
#![allow(unused)]
fn main() {
Option<Box<i32>>
None
+–––––+–––––––––––––––––––––+
│ 0 │ padding │
+–––––+–––––––––––––––––––––+
| mark|
Some(Box<i32>)
+–––––+–––––––––+–––––––––––+
│ 1 │ padding │ * │
+–––––+–––––––––+–––––––––––+
+–––––+–––––––––+––│––––––––+
| mark| |– │ Box<T>–|
|– │ pointer|
│
heap V
+–––––––––––+
│ 0 │
+–––––––––––+
// 因为智能指针的值都不允许为0, 所以实际上上面会进行优化成下面的方式
None
+–––––––––––+
│ 0 │
+–––––––––––+
| mark|
Some(Box<i32>)
+–––––––––––+
│ * │
+–––––––––––+
+––│––––––––+
|– │ Box<T>–|
|– │ pointer|
│
heap V
+–––––––––––+
│ 0 │
+–––––––––––+
}10. array,[T]和Vec<T>
10.1 array
#![allow(unused)]
fn main() {
let a:[i32;3] = [55,66,77];
stack [–––– a ––––|
+––––+––––+––––+
│ 55 │ 66 │ 77 │
+––––+––––+––––+
}10.2 [T]
[T]即slice 是DST 类型, 是类型 T 序列的一种视图. 所以它只能使用&[T]宽指针进行引用,参考[&[T] 引用](# 5. & 和&[T] 引用)
10.3 Vec<T>
#![allow(unused)]
fn main() {
let a:Vec<i32> = vec![55,66,77];
stack [––– a ––|
+–––+–––+–––+
│ • │ 3 │ 4 │
+–│–+–––+–––+
│
heap │
+–V––+––––+––––+
│ 55 │ 66 │ 77 │
+––––+––––+––––+
}11. 智能指针
11.1 Box<T>
Box<T>单所有权,只适用于单线程
#![allow(unused)]
fn main() {
let v: Box<Vec<i32>> = Box::new(vec![55,66,77]);
stack
[ v ]
+–––+
│ * │
+–│–+
|
heap |
+–V–+–––+–––+
│ * │ 3 │ 3 │
+–│–+–––+–––+
│
│
+–V––+––––+––––+
│ 55 │ 66 │ 77 |
+––––+––––+––––+
}11.2 Rc<T>
Rc<T> 多所有权,只适用于单线程,且只可用于不可变借用.
#![allow(unused)]
fn main() {
let v: Rc<Vec<i32>> = Rc::new(vec![55,66,77]);
let v2 = v.clone()
stack
[ v ] [ v2 ]
+–––+ +–––+
│ * │ * │
+–│–+ +–│–+
|___________|
heap |
+–V–+–––+–––+–––+
│ 2 │ * │ 3 │ 3 |
+–––+–│–+–––+–––+
/ │
ref count<– / │
+–V––+––––+––––+
│ 55 │ 66 │ 77 |
+––––+––––+––––+
}11.3 Arc<T>
Arc<T> 数据模型同Rc<T>但可使用于多线程, 多所有权,只可用于不可变借用.
Arc<T> 与Rc<T>区别在于,引用计数是原子计数
#![allow(unused)]
fn main() {
stack
[ptr |meta]
+–––-+–––+
│ * │ │
+–│-–+--–│
|
heap |
+–V–+–––+–––+
│ │ │ T │
+–––+--–+–––+
/ │
ref count <–/ V
weak ref count
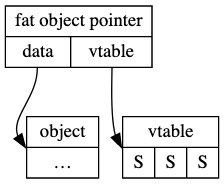
}12. trait object
官方定义:
A trait object is an opaque value of another type that implements a set of traits.
The set of traits is made up of an object safe base trait plus any number of auto traits.
trait 是 DST 类型 ,对trait的引用称之为 trait object, trait object是个胖指针, 包含两个普通指针分别为 data和 vtable.
13. Dynamically Sized Types(DST) 动态类型
一般来说大多数类型, 可以在编译阶段确定大小和对齐属性, Sized trait 就是保证了这种特性.
非 size (?Sized) 及 DST 类型.
- DST 类型有 slice 和 trait object.
- DST 类型必须通过指针来使用,需要注意:
- DST 可以作为泛型参数, 但是需要注意泛型参数默认是
Sized, 如果是 DST 类型需要特别的指定为?Sized.
14. 空类型 (Empty Types)
#![allow(unused)]
fn main() {
enum Void {}
}空类型的一个主要应用场景是在类型层面声明不可到达性. 假如, 一个 API 一般需要返回一个 Result, 但是在特殊情况下它是绝对不会运行失败的. 这种情况下将返回值设为 Result<T, Void>, API 的调用者就可以信心十足地使用 unwrap, 因为不可能产生一个 Void 类型的值, 所以返回值不可能是一个 Err.
15. function
#![allow(unused)]
fn main() {
stack
[ f |
+–––+
│ * │
+–│–+
|
machine code of function
}16. closure
闭包相当于一个捕获变量的结构体, 实现了 FnOnce 或 FnMut 或 Fn.
17. Reference
18. 生命周期
所有权机制
- 一个值只能被一个变量所拥有, 这个变量被称为所有者(Each value in Rust has a variable that’s called its owner).
- 一个值同一时刻只能有一个所有者(There can only be one owner at a time), 也就是说不能有两个变量拥有相同的值. 所以对应刚才说的变量赋值、参数传递、函数返回等行为, 旧的所有者会把值的所有权转移给新的所有者, 以便保证单一所有者的约束.
- 当所有者离开作用域, 其拥有的值被丢弃(When the owner goes out of scope, the value will be dropped), 内存得到释放.
1. Copy trait
- 原生类型, 包括函数、不可变引用和裸指针实现了 Copy;
- 数组和元组, 如果其内部的数据结构实现了 Copy, 那么它们也实现了 Copy;
- 可变引用没有实现 Copy;
- 非固定大小的数据结构, 没有实现 Copy
2. Copy语义和Move语义
是否实现 Copy Trait 区分 Copy语义和 Move 语义
Copy语义按位复制Copy语义对应值类型Move语义对应引⽤类型.
所有权机制: 保证内存安全和性能 所有权转移. 每个值都有⼀个所有者.
fn main() {
// Box没有实现copy trait
let a = Box::new(5);
let b = a;
println!("{:?}", a); // a move to b, compile error
}2.1 Struct, Enum
Struct成员均实现Copy trait, 但rust并不会默认为struct实现copy
#[derive(Debug)]
struct A {
// 成员虽然是copy语义, 但rust并不会默认为struct实现copy
a: i32,
b: i32
}
// 显示指定struct实现copy trait
#[derive(Debug, Copy, Clone)]
struct B {
a: i32,
b: i32
}
fn main() {
let a = A{a: 1, b: 2};
let b = a;
println!("{:?}", a); // a move to b, compile error
}Struct需要显式实现Copy trait,使用Copy宏.
// 显式指定struct实现copy trait
#[derive(Debug, Copy, Clone)]
struct A {
a: i32,
b: i32
}
fn main() {
let a = A{a: 1, b: 2};
let b = a;
println!("{:?}", a); // a copy to b
}Struct成员含有未实现Copy trait, 那么Copy宏显式指定将导致编译失败
#![allow(unused)]
fn main() {
#[derive(Debug, Copy, Clone)]
struct A {
a: i32,
// 当成员有未实现Copy trait的成员,即使手动指定也会编译失败
b: Box<i32>
}
fn main() {
let a = A{a: 1, b: Box::new(5)};
let b = a;
println!("{:?}", a); // a move to b, compile error
}
}2.2 Tuple, Option, Array
语言默认的,成员实现则其实现Copy trait
2.2.1 Tuple
#![allow(unused)]
fn main() {
fn main() {
let a = (String::from("a"), String::from("b"))
let b = a;
println!("{:?}", a); // a move to b, compile error
let c = (1, 2, 3)
let d = c;
println!("{:?}", c); // c copy to d
}
}2.2.2 Arrary
fn main() {
let v = [1, 2, 3];
foo(v); // copy
assert_eq!([1, 2, 3], v)
}
fn foo(mut v: [i32; 3]) -> [i32; 3] {
v[0] = 3;
assert_eq!([3, 2, 3], v);
v
}
fn main() {
let mut v = [1, 2, 3];
foo(&mut v); // borrow
assert_eq!([3, 2, 3], v)
}
fn foo(v: &mut [i32; 3]) {
v[0] = 3;
}
3. 借用规则
- 借⽤的⽣命周期不能⻓于出借⽅. –> 防⽌出现悬垂指针.
- 可变借⽤不能有别名. –> 独占, 可变借⽤不能共享, 只能独占, 只能有⼀个.
- 不可变借⽤可以多个共享. –> 共享不可变
- 不可变借用和可变借用不可同时存在(作用域内).
4. 解引用操作会获取所有权
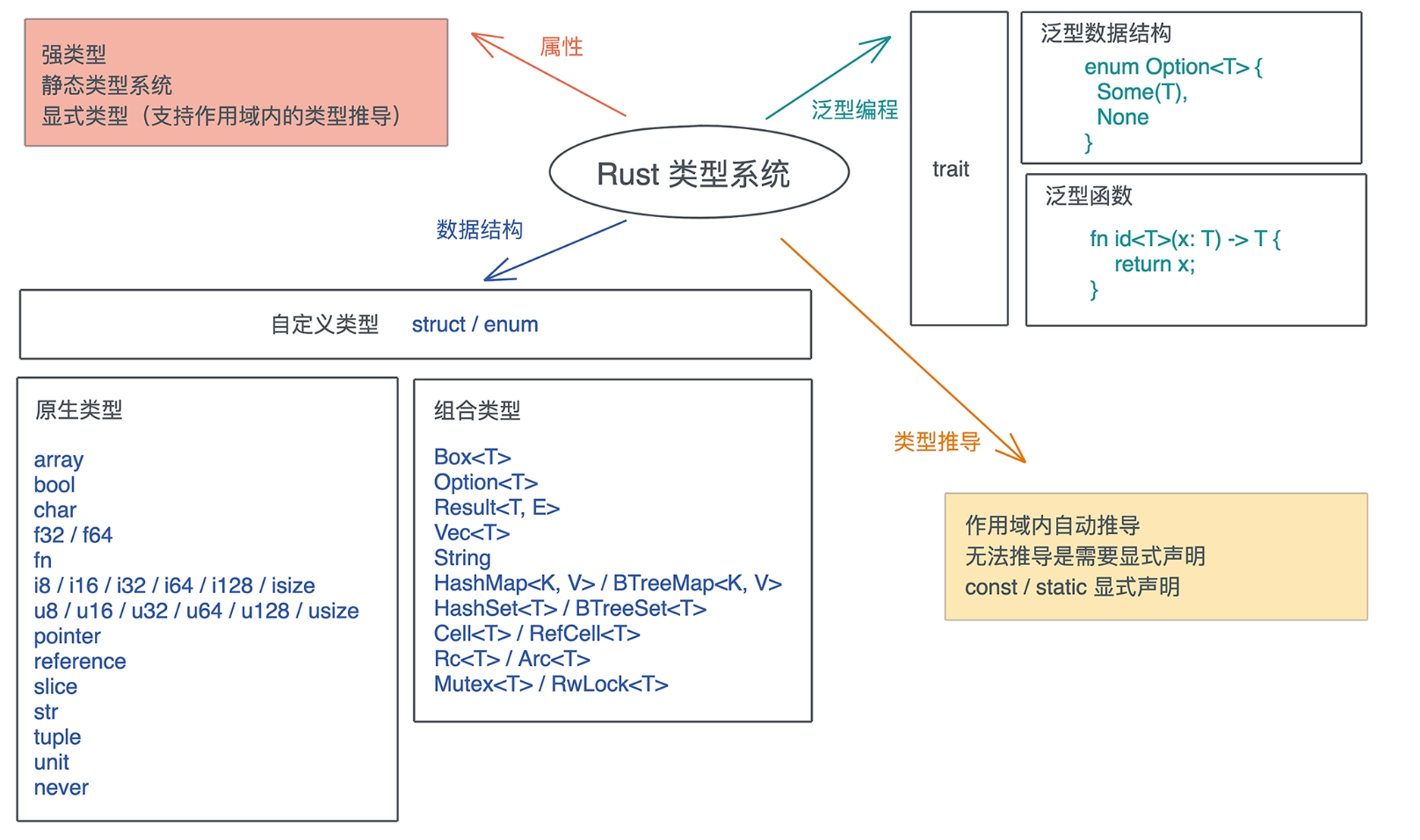
类型系统
1. 概述
- 类型大小, 类型在内存中对⻬、布局
- 类型推导
- 泛型
Trait- 类型转换
- 多态
Rust是一⻔显式静态强类型的类型安全语言
- 显式: 是因为它的类型推导在某些时候需要显示指定
- 静态: 表明它在编译期进行类型检查
- 强类型: 表明它不允许类型自动隐式转换,不同类型无法进行计算
- 类型安全: 表明它保证运行时的内存安全, 只能按照被允许的方法, 访问它被授权访问的内存
2 类型大小
2.1 可确定大小类型
use std::mem;
fn main() {
println!("{}", mem::size_of::<bool>());
println!("{}", mem::size_of::<u8>());
println!("{}", mem::size_of::<i8>());
println!("{}", mem::size_of::<u16>());
println!("{}", mem::size_of::<i16>());
println!("{}", mem::size_of::<u32>());
println!("{}", mem::size_of::<i32>());
println!("{}", mem::size_of::<f32>());
println!("{}", mem::size_of::<f64>());
println!("{}", mem::size_of::<char>());
println!("{}", mem::size_of::<()>());
}2.2 动态大小类型
fn main() {
let str = "hello world";
let prt = str.as_ptr();
let len = str.len();
println!("{:p}", prt);
println!("{:?}", len);
}
2.3 零值类型
零值类型: 类型的特别是可以提高性能或实现某些trait而不关心其数据
use std::mem;
// 零大小类型, 不分配内存空间.
enum Void {} // 空枚举
struct Foo; // 单元结构体
struct Bar {
foo: Foo,
qux: (), // 单元类型
bax: [u8; 0], // 空数组
}
fn main() {
println!("{}", mem::size_of::<()>());
println!("{}", mem::size_of::<Void>());
println!("{}", mem::size_of::<Foo>());
println!("{}", mem::size_of::<Bar>());
println!("{}", mem::size_of::<[(); 10]>());
}
3. 类型推导
3.1 自动推导
// Rust大部份情况下可以根据上下文明推导类型
fn main() {
let a = 1; // 没有标注类型.
let b = 2; // 没有标注类型.
sum(a, b); // Rust 自动推导了a和b的类型.
let elem = 5u8;
let mut vec = Vec::new();
vec.push(elem);
}
fn sum(a: u32, b: i32) -> u32 {
a + (b as u32)
}3.2 手动标注
// 引入 turbofish 操作符 ::<>
fn main() {
let x = "1";
println!("{:?}", x.parse::<u32>().unwrap());
}
4. 泛型
单态化 零成本抽象的一种实现,
其实在 Rust 里, 生命周期标注也是泛型的一部分, 一个生命周期 'a 代表任意的生命周期, 和 T 代表任意类型是一样的
5. Trait
Rust的trait提供了零成本抽象能力, 它定义了类型使用这个接口的行为
在 trait 中, 方法可以有缺省的实现.
在定义方法的时候, 频繁看到两个特殊的关键字:Self 和 self.
Self代表当前的类型, 比如File类型实现了Write, 那么实现过程中使用到的Self就指代File.self在用作方法的第一个参数时, 实际上是self: Self的简写, 所以&self是self: &Self, 而&mut self是self: &mut Self.
trait 的“继承“
在 Rust 中, 一个 trait 可以“继承”另一个 trait 的关联类型和关联函数. 比如 trait B: A , 是说任何类型 T, 如果实现了 trait B, 它也必须实现 trait A, 换句话说, trait B 在定义时可以使用 trait A 中的关联类型和方法
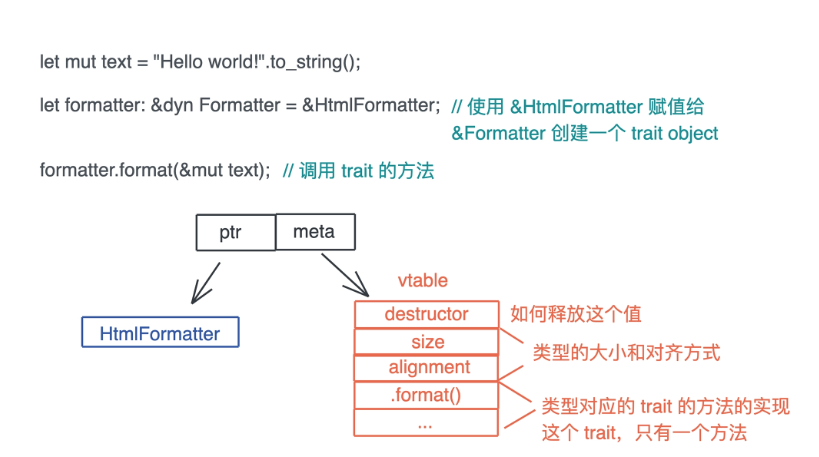
Trait 如何定义和使用

Trait Object 实现原理
6. 类型转换
无歧义完全限定语法
trait A {
fn test(&self, i: i32) {
println!("from trait A: {:?}", i)
}
}
trait B {
fn test(&self, i: i32) {
println!("from trait B: {:?}", i)
}
}
struct S(i32);
impl A for S {}
impl B for S {}
fn main() {
let s = S(1);
A::test(&s, 2);
<S as A>::test(&s, 2);
B::test(&s, 2);
<S as B>::test(&s, 2);
}
7. 多态
静态类型系统, 多态可以通过参数多态(parametric polymorphism)、特设多态(adhoc polymorphism)和子类型多态(subtype polymorphism)实现.
- 参数多态是指, 代码操作的类型是一个满足某些约束的参数, 而非具体的类型.
Rust通过泛型支持. - 特设多态是指同一种行为有多个不同实现的多态. 比如加法, 可以 1+1, 也可以是 “abc” + “cde”、matrix1 + matrix2、甚至 matrix1 + vector1. 在面向对象编程语言中, 特设多态一般指函数的重载.
Rust通过trait支持. - 子类型多态是指, 在运行时, 子类型可以被当成父类型使用.
Rust通过trait object支持.
在 Rust 中, 参数多态通过泛型来支持、特设多态通过 trait 来支持、子类型多态可以用 trait object 来支持,
7.1 参数多态
它包括泛型数据结构和泛型函数
-
泛型数据结构:
Rust对数据结构的泛型, 或者说参数化类型, 有着完整的支持. 例:Option<T> -
泛型函数: 在声明一个函数的时候, 我们还可以不指定具体的参数或返回值的类型, 而是由泛型参数来代替
7.2 特设多态
包括运算符重载, 是指同一种行为有很多不同的实现
7.3 子类型多态
子类型当成父类型使用, 通过 trait object 来支持,
无畏并发
Concurrent: 程序的不同部分之间独立的运行, 同时处理很多事情的能力.Parallel: 程序的不同部分同时运行, 同时执行很多事情的手段.
1. Sync和Send trait
#![allow(unused)]
fn main() {
pub unsafe auto trait Send {}
pub unsafe auto trait Sync {}
}这两个trait(std::marker::Sync和std::marker::Send)都是 unsafe auto trait, auto 意味着编译器会在合适的场合, 自动为数据结构添加它们的实现, 而 unsafe 代表实现的这个 trait 可能会违背 Rust 的内存安全准则, 如果开发者手工实现这两个 trait, 要自己为它们的安全性负责.
Send/Sync 是 Rust 并发安全的基础:
-
Send: 允许线程间转移所有权,Rc<T>没有实现Send,它只用于单线程的情景.- 任何完全由
Send类型组成的类型也被标记为Send - 除了原始指针之外,几乎所有的基础类型都是实现了
Send
- 任何完全由
-
Sync: 允许从多线程访问.- 实现了
Sync的类型可以安全的被多个线程引用 - 如果
T是Sync,那&T就是Send, 引用可以被安全的送往另一个线程.
- 实现了
-
手动来实现
Send和Sync是很难保证安全的,需要很谨慎的使用unsafe代码.-
如果一个类型
T实现了Send trait, 意味着T可以安全地从一个线程移动到另一个线程, 也就是说所有权可以在线程间移动. -
如果一个类型
T实现了Sync trait, 则意味着&T可以安全地在多个线程中共享. 一个类型T满足Sync trait, 当且仅当&T满足Send trait.
-
对于 Send/Sync 在线程安全中的作用, 可以这么看, 如果一个类型 T: Send, 那么 T 在某个线程中的独占访问是线程安全的;如果一个类型 T: Sync, 那么 T 在线程间的只读共享是安全的.
对于我们自己定义的数据结构, 如果其内部的所有域都实现了 Send / Sync, 那么这个数据结构会被自动添加 Send / Sync.
标准库中, 不支持 Send / Sync 的数据结构主要有:
- 裸指针
*const T/*mut T. 它们是不安全的, 所以既不是Send也不是Sync. UnsafeCell不支持Sync. 也就是说, 任何使用了Cell或者RefCell的数据结构不支持Sync.- 引用计数
Rc不支持Send也不支持Sync. 所以Rc无法跨线程.
2. 并发常见工作模式
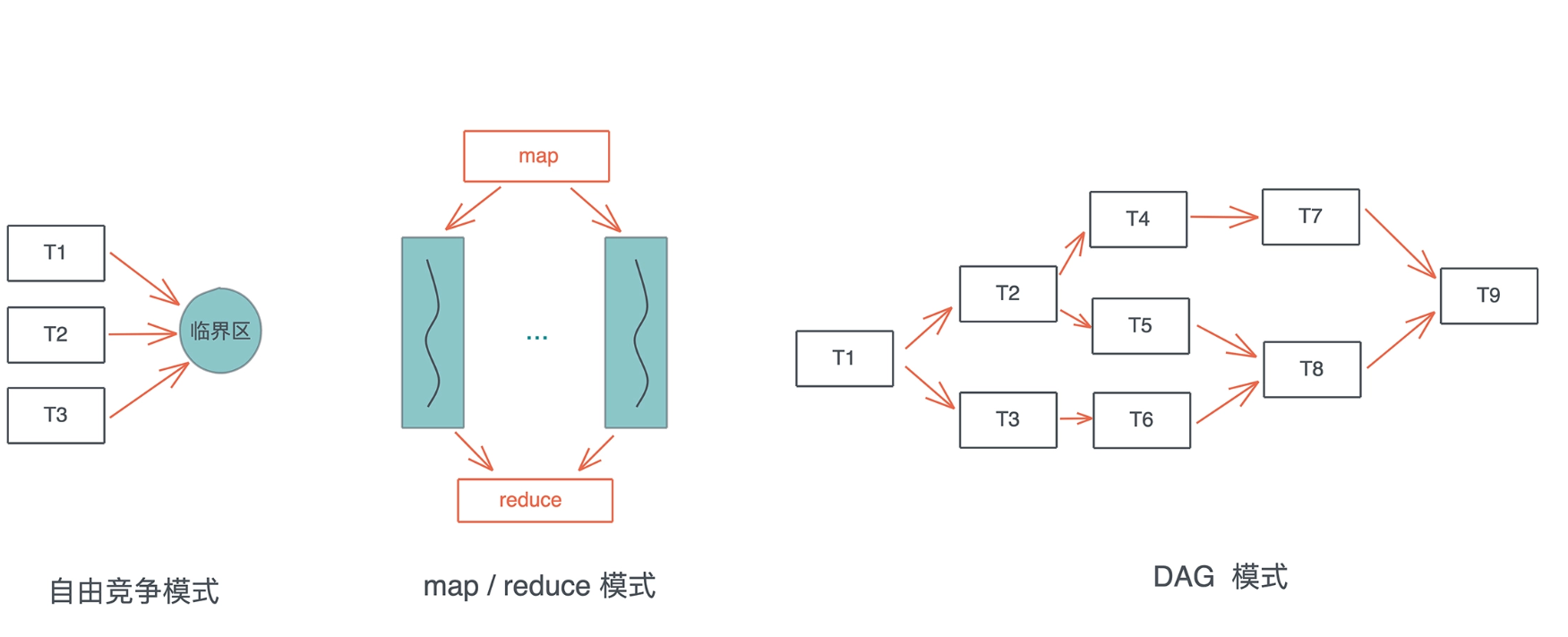
- 自由竞争模式下, 多个并发任务会竞争同一个临界区的访问权
- map/reduce 模式, 把工作打散, 按照相同的处理完成后, 再按照一定的顺序将结果组织起来
- DAG 模式, 把工作切成不相交的、有依赖关系的子任务, 然后按依赖关系并发执行.
3. Atomic
Atomic是所有并发原语的基础, 它为并发任务的同步奠定了坚实的基础.可以通过一条指令读取某个内存地址, 判断其值是否等于某个前置值, 如果相等, 将其修改为新的值. 这就是 Compare-and-swap 操作, 简称CAS
#![allow(unused)]
fn main() {
pub fn compare_exchange(
&self,
current: bool,
new: bool,
success: Ordering,
failure: Ordering
) -> Result<bool, bool>
pub enum Ordering {
Relaxed,
Release,
Acquire,
AcqRel,
SeqCst,
}
}可以看到 compare_exchange函数有两个和Ordering的奇怪参数, Ordering是一个 enum.
Relaxed: 最宽松的规则, 它对编译器和CPU不做任何限制, 可以乱序执行.Release, 当我们写入数据时, 那么- 对于当前线程, 任何读取或写入操作都不能被乱序排在这个 store 之后.
- 对于其它线程, 任何使用了
Acquire来读取这个atomic的数据, 那么它们看到的是修改后的结果.
Acquire, 当我们读取数据时, 那么- 对于当前线程, 任何读取或者写入操作都不能被乱序排在这个读取之前.
- 对于其它线程, 如果使用了
Release来修改数据, 那么, 修改的值对当前线程可见.
AcqRel是Acquire和Release的结合, 同时拥有Acquire和Release的保证. 这个一般用在fetch_xxx上, 比如你要对一个atomic自增1, 你希望这个操作之前和之后的读取或写入操作不会被乱序, 并且操作的结果对其它线程可见.SeqCst是最严格的Ordering,除了AcqRel的保证外,它还保证所有线程看到的所有SeqCst操作的顺序是一致的.
#![allow(unused)]
fn main() {
while self
.locked
.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed)
.is_err()
{
// 性能优化: compare_exchange 需要独占访问, 当拿不到锁时, 我们
// 先不停检测 locked 的状态, 直到其 unlocked 后, 再尝试拿锁
while self.locked.load(Ordering::Relaxed) == true {}
}
}注意, 我们在
while loop里, 又嵌入了一个loop. 这是因为CAS是个代价比较高的操作, 它需要获得对应内存的独占访问 (exclusive access) , 我们希望失败的时候只是简单读取 atomic 的状态, 只有符合条件的时候再去做独占访问, 进行CAS. 所以, 看上去多做了一层循环, 实际代码的效率更高.
4. Mutex
SpinLock, 顾名思义,就是线程通过CPU 空转(spin, 就像前面的 while loop)忙等 (busy wait) , 来等待某个临界区可用的一种锁. 这种通过 SpinLock做互斥的实现方式有使用场景的限制: 如果受保护的临界区太大, 那么整体的性能会急剧下降, CPU 忙等, 浪费资源还不干实事, 不适合作为一种通用的处理方法.
通用的解决方案是: 当多个线程竞争同一个 Mutex 时, 获得锁的线程得到临界区的访问, 其它线程被挂起, 放入该 Mutex 上的一个等待队列里. 当获得锁的线程完成工作, 退出临界区时, Mutex 会给等待队列发一个信号, 把队列中第一个线程唤醒, 于是这个线程可以进行后续的访问. 整个过程如下:
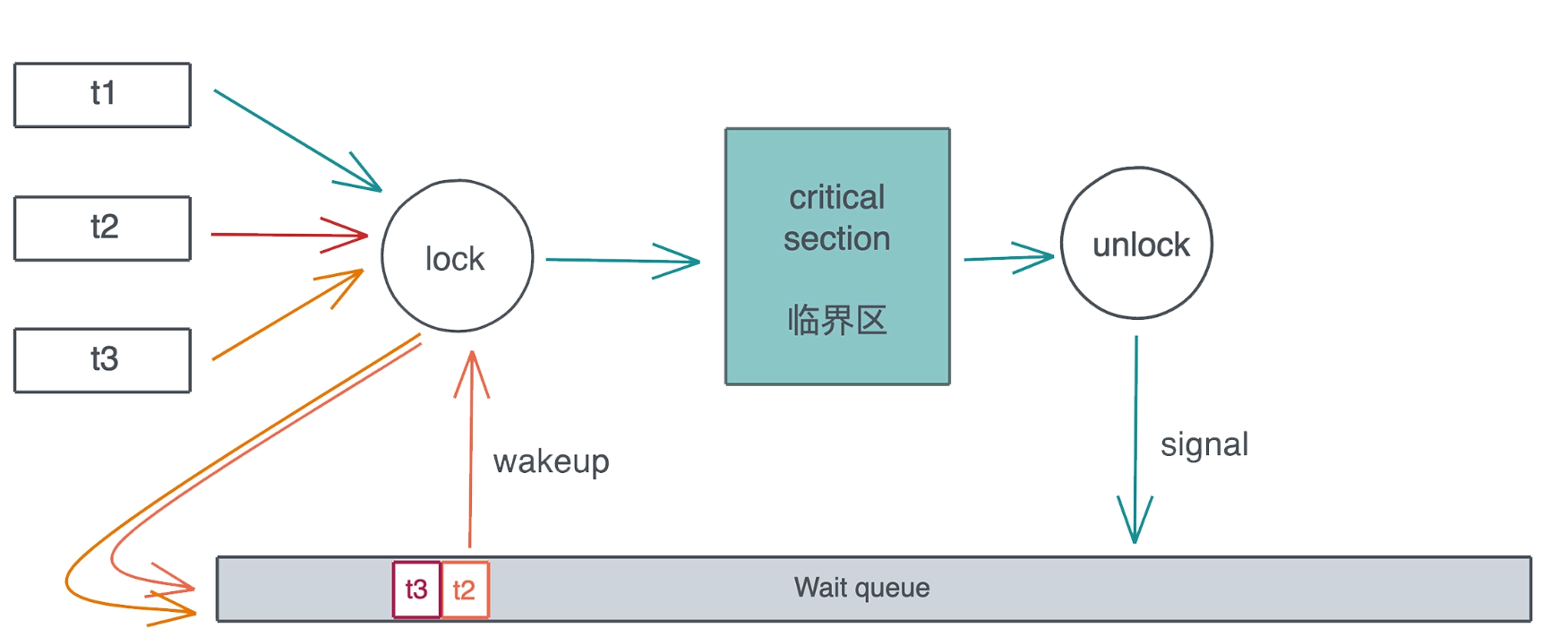
当然, 这样实现会带来公平性的问题: 如果新来的线程恰巧在 spin 过程中拿到了锁, 而当前等待队列中还有其它线程在等待锁, 那么等待的线程只能继续等待下去, 这不符合 FIFO, 不适合那些需要严格按先来后到排队的使用场景. 为此, parking_lot 提供了 fair mutex.
5. Condvar
操作系统还提供了 Condvar. Condvar 有两种状态:
- 等待 (wait) : 线程在队列中等待, 直到满足某个条件.
- 通知 (notify) : 当
condvar的条件满足时, 当前线程通知其他等待的线程可以被唤醒. 通知可以是单个通知, 也可以是多个通知, 甚至广播 (通知所有人).
6. Channel
Channel 把锁封装在了队列写入和读取的小块区域内, 然后把读者和写者完全分离, 使得读者读取数据和写者写入数据, 对开发者而言, 除了潜在的上下文切换外, 完全和锁无关, 就像访问一个本地队列一样. 所以, 对于大部分并发问题, 我们都可以用 Channel 或者类似的思想来处理 (比如 actor model).
Rust提供了以下四种Channel:
-
oneshot: 这可能是最简单的Channel, 写者就只发一次数据, 而读者也只读一次. 这种一次性的、多个线程间的同步可以用oneshot channel完成. 由于oneshot特殊的用途, 实现的时候可以直接用atomic swap来完成 -
rendezvous: 很多时候, 我们只需要通过Channel来控制线程间的同步, 并不需要发送数据.rendezvous channel是channel size为 0 的一种特殊情况. -
bounded:bounded channel有一个队列, 但队列有上限. 一旦队列被写满了, 写者也需要被挂起等待. 当阻塞发生后, 读者一旦读取数据,channel内部就会使用Condvar的notify_one通知写者, 唤醒某个写者使其能够继续写入. -
unbounded:queue没有上限, 如果写满了, 就自动扩容. 我们知道,Rust的很多数据结构如Vec、VecDeque都是自动扩容的.unbounded和bounded相比, 除了不阻塞写者, 其它实现都很类似.
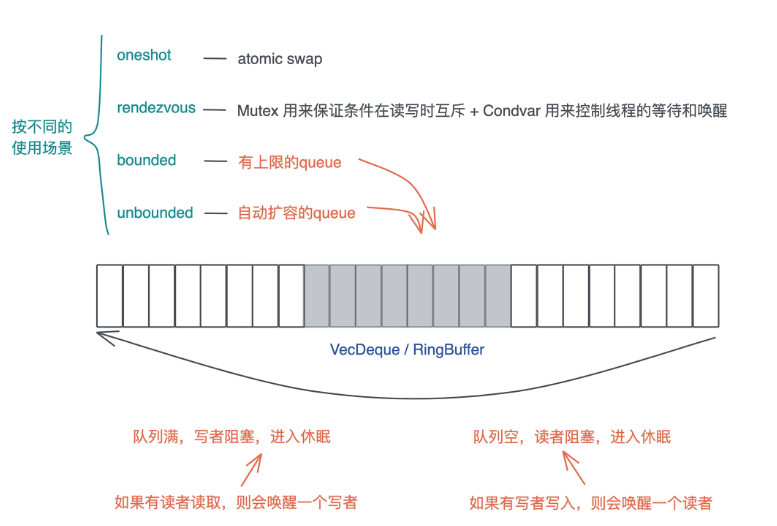
根据 Channel 读者和写者的数量, Channel 又可以分为:
SPSC: Single-Producer Single-Consumer, 单生产者, 单消费者. 最简单, 可以不依赖于Mutex, 只用atomics就可以实现.SPMC: Single-Producer Multi-Consumer, 单生产者, 多消费者. 需要在消费者这侧读取时加锁.MPSC: Multi-Producer Single-Consumer, 多生产者, 单消费者. 需要在生产者这侧写入时加锁.MPMC: Multi-Producer Multi-Consumer. 多生产者, 多消费者. 需要在生产者写入或者消费者读取时加锁.
7. Actor
actor model, actor 是一种有栈协程. 每个 actor, 有自己的一个独立的、轻量级的调用栈, 以及一个用来接受消息的消息队列 (mailbox 或者 message queue) , 外界跟 actor 打交道的唯一手段就是, 给它发送消息.
9. 参考
- Robe Pike 的演讲 concurrency is not parallelism
- Jon Gjengset 的视频: Crust of Rust: Atomics and Memory Ordering
- Rust 的 spin-rs crate 提供了
Spinlock的实现 - atcix actor 实现
- bastion actor 实现
- concurrent hash map: dashmap , left-right
宏 macro
宏在 Rust 里指的是一组相关特性的集合称谓:
- 使用
macro_rules!构建的声明宏 (declarative macro) - 3 种过程宏
- 自定义
#[derive]宏, 用于struct 或enum, 可以为其指定随derive属性添加的代码 - 类似属性的宏, 在任何条目上添加自定义属性
- 类似函数的宏, 看起来像函数调用, 对其指定为参数的 token 进行操作
- 自定义
1. 宏与函数的差别
-
宏是用来编写可以生成其它代码的代码, 即所谓的 元编程(metaprogramming)
-
函数在定义签名时, 必须声明参数的个数和类型,
-
宏可处理可变的参数
-
编译器会在解释代码前展开宏
-
宏的定义比函数复杂得多, 难以阅读,理解, 维护
-
在某个文件调用宏时, 必须提前定义宏或将宏引入当前作用哉
-
函数可以在任何位置定义,并在任何位置使用
2. macro_rules!声明宏
#![allow(unused)]
fn main() {
#[macro_export]
macro_rules! vec {
( $( $x: expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
}
}
// 此处有一个单边模式 ( $( $x: expr ),* ), 后跟 => 和模式相关的代码块. 如果模式匹配, 代码将被执行. 更复杂的宏会有多个单边模式.
// $x: expr 匹配任何rust的表达式,并命名为x
// $( $x: expr ),* 表示匹配*号前0个或1个表达式
}3. 过程宏
这种形式更像函数
- 接收并操作输入的Rust代码
- 生成另外一些Rust代码结果
三种过程宏:
- 自定义派生
- 属性宏
- 函数宏
Note: 创建过程宏时, 宏定义必须单独放在它们自己的包中, 并使用特殊的包类型
闭包(closure): FnOnce, FnMut, Fn
1. 闭包定义
闭包是将函数, 或者说代码和其环境一起存储的一种数据结构. 闭包引用的上下文中的自由变量, 会被捕获到闭包的结构中, 成为闭包类型的一部分
在 Rust 里, 闭包可以用 |args| { code } 来表述, 除了用引用来捕获自由变量之外, 还有另外一个方法使用 move 关键字 move |args| { code }
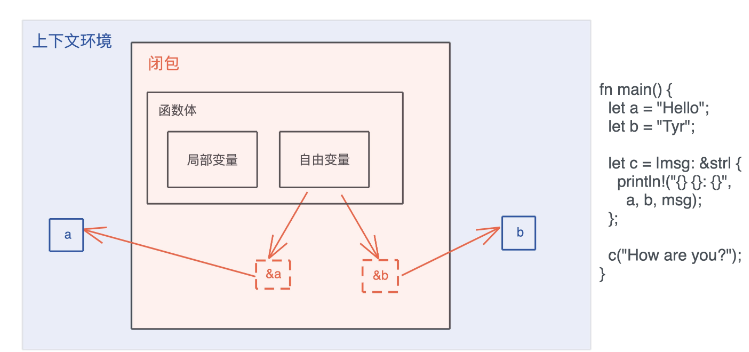
图中闭包 c 捕获了上下文中的 a 和 b, 并通过引用来使用这两个自由变量:
2. 闭包的本质
-
闭包是一种匿名类型, 一旦声明, 就会产生一个新的类型, 但这个类型无法被其它地方使用. 这个类型就像一个结构体, 会包含所有捕获的变量.
-
闭包的大小跟参数、局部变量都无关, 只跟捕获的变量有关.
-
闭包是存储在栈上, 并且除了捕获的数据外, 闭包本身不包含任何额外函数指针指向闭包的代码
-
闭包变量的所有权:
- 如果不使用
move转移所有权, 闭包会引用上下文中的变量, 这个引用受借用规则的约束, 所以只要编译通过, 那么闭包对变量的引用就不会超过变量的生命周期, 没有内存安全问题. - 如果使用
move转移所有权, 上下文中的变量在转移后就无法访问, 闭包完全接管这些变量, 它们的生命周期和闭包一致, 所以也不会有内存安全问题.
- 如果不使用
3. 闭包类型
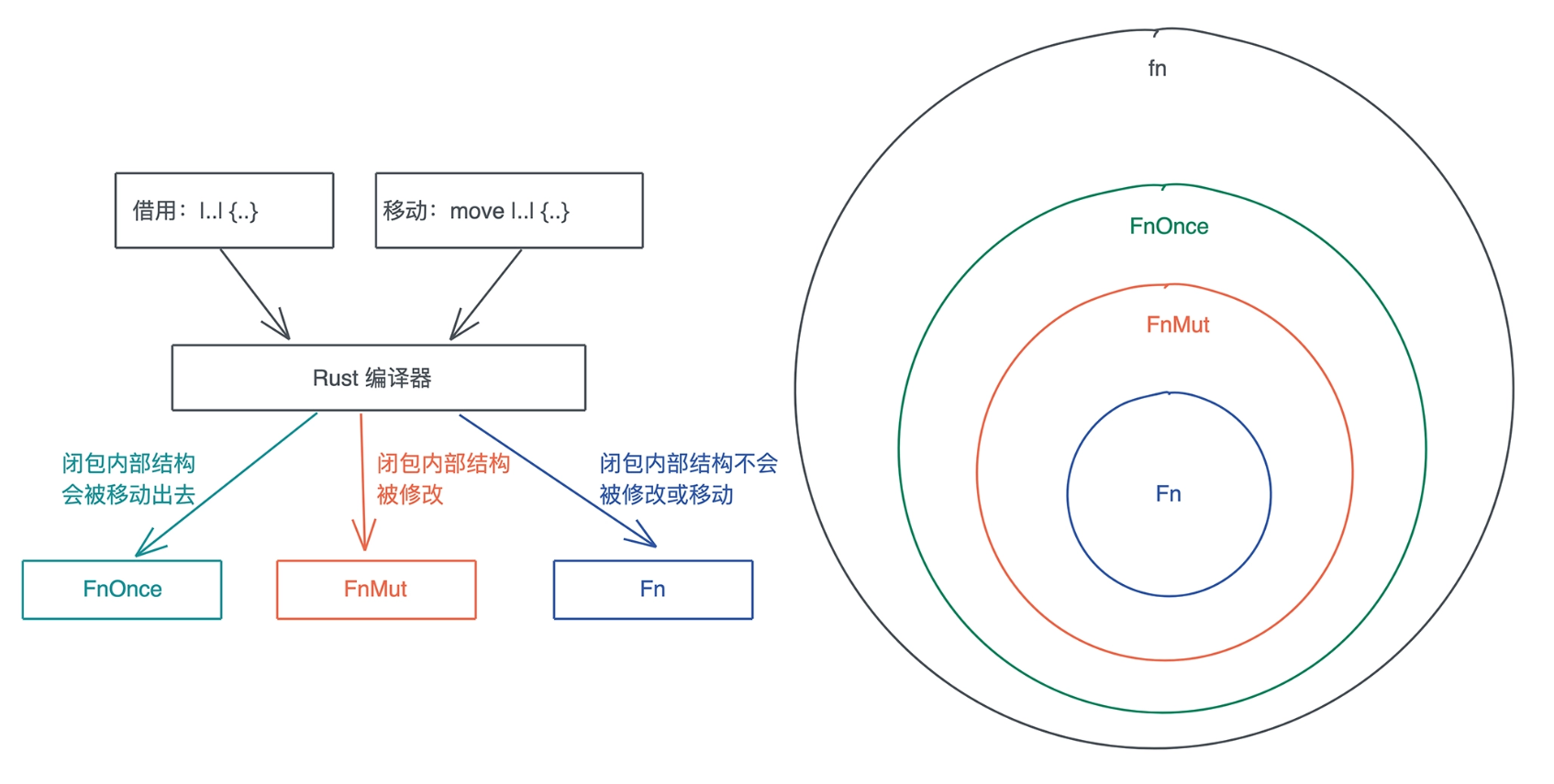
FnOnce / FnMut / Fn 这三种闭包类型有什么区别.
3.1 FnOnce
#![allow(unused)]
fn main() {
pub trait FnOnce<Args> {
type Output;
extern "rust-call" fn call_once(self, args: Args) -> Self::Output;
}
}FnOnce有一个关联类型, 这是闭包的返回值类型, 还有一个方法 call_once, 注意call_once第一个参数是self,它会转移self的所有权到call_once函数中.
这也是为什么FnOnce被称为 Once: 它只能被调用一次, 再次调用, 编译器将报变量已被 move 的所有权错误.
FnOnce 的参数, 是一个叫 Args 的泛型参数, 它并没有任何约束.
fn main() {
let name = String::from("Tyr");
// 这个闭包啥也不干, 只是把捕获的参数返回去
// 这是一个FnOnce闭包
let c = move |greeting: String| (greeting, name);
let result = c("hello".to_string());
println!("result: {:?}", result);
// 无法再次调用
let result = c("hi".to_string());
}3.2 FnMut
#![allow(unused)]
fn main() {
pub trait FnMut<Args>: FnOnce<Args> {
extern "rust-call" fn call_mut(&mut self, args: Args) -> Self::Output;
}
}FnMut“继承”了FnOnce, 所以FnMut也拥有Output这个关联类型和call_once这个方法. 此外, 它还有一个call_mut()方法. 注意call_mut()传入&mut self, 它不移动self, 所以FnMut可以被多次调用.FnMut“继承”了FnOnce, 所以, 一个FnMut闭包, 可以被传给一个需要FnOnce的上下文, 此时调用闭包相当于调用了call_once().
fn main() {
let mut name = String::from("hello");
// 捕获 &mut name
let mut c = || {
name.push_str(" Tyr");
println!("c: {}", name);
};
call_mut(&mut c);
call_once(c);
}
// 在作为参数时, FnMut 也要显式地使用 mut, 或者 &mut
fn call_mut(c: &mut impl FnMut()) {
c();
}
// 为啥 call_once 不需要 mut?
fn call_once(c: impl FnOnce()) {
c();
}3.3 Fn
#![allow(unused)]
fn main() {
pub trait Fn<Args>: FnMut<Args> {
extern "rust-call" fn call(&self, args: Args) -> Self::Output;
}
}Fn“继承”了 FnMut. 这也就意味着任何需要 FnOnce 或者 FnMut 的场合, 都可以传入满足 Fn 的闭包
fn main() {
let v = vec![0u8; 1024];
// Fn, 不移动所有权
let mut c = |x: u64| v.len() as u64 * x;
// Fn, 移动所有权
// let mut c = move |x: u64| v.len() as u64 * x;
println!("direct call: {}", c(2));
println!("call: {}", call(3, &c));
println!("call_mut: {}", call_mut(4, &mut c));
println!("call_once: {}", call_once(5, c));
}
fn call(arg: u64, c: &impl Fn(u64) -> u64) -> u64 {
c(arg)
}
fn call_mut(arg: u64, c: &mut impl FnMut(u64) -> u64) -> u64 {
c(arg)
}
fn call_once(arg: u64, c: impl FnOnce(u64) -> u64) -> u64 {
c(arg)
}3.4 闭包使用场景
-
作为参数
-
作为函数返回值
-
为它实现某个
trait- 使其能表现出其他行为, 而不仅仅作为函数被调用. 比如有些接口既可以传入一个结构体, 又可以传入一个函数或者闭包.
#![allow(unused)] fn main() { pub trait Interceptor { /// Intercept a request before it is sent, optionally cancelling it. fn call(&mut self, request: crate::Request<()>) -> Result<crate::Request<()>, Status>; } impl<F> Interceptor for F where F: FnMut(crate::Request<()>) -> Result<crate::Request<()>, Status>, { fn call(&mut self, request: crate::Request<()>) -> Result<crate::Request<()>, Status> { self(request) } } }
Interceptor有一个call方法, 它可以让 gRPC Request 被发送出去之前被修改, 一般是添加各种头, 比如Authorization头.
4.总结
Rust 闭包的效率非常高. 首先闭包捕获的变量, 都储存在栈上, 没有堆内存分配. 其次因为闭包在创建时会隐式地创建自己的类型, 每个闭包都是一个新的类型. 通过闭包自己唯一的类型, Rust 不需要额外的函数指针来运行闭包, 所以闭包的调用效率和函数调用几乎一致.
错误处理
1. Option 和 Result
Option 是一个 enum, 它可以承载有值 / 无值这种最简单的错误类型.
其定义如下:
#![allow(unused)]
fn main() {
pub enum Option<T> {
None,
Some(T),
}Result 是一个更加复杂的 enum, 当函数出错时, 可以返回 Err(E), 否则 Ok(T).
其定义如下:
#![allow(unused)]
fn main() {
#[must_use = "this `Result` may be an `Err` variant, which should be handled"]
pub enum Result<T, E> {
Ok(T),
Err(E),
}
}2. ? 操作符
好在 Rust 除了有强大的类型系统外, 还具备元编程的能力, 所以在 Rust 代码中, 如果你只想传播错误, 不想就地处理, 可以用 ? 操作符.
? 操作符内部被展开成类似下面的代码:
#![allow(unused)]
fn main() {
match result {
Ok(v) => v,
Err(e) => return Err(e.into())
}
}在不同的错误类型之间是无法直接使用的, 注意上面的 e.into(), 需要实现 From trait 在二者之间建立起转换的桥梁
3. 函数式错误处理
Rust 还为 Option 和 Result 提供了大量的辅助函数, 如 map / map_err / and_then, 你可以很方便地处理数据结构中部分情况. 如下图所示:
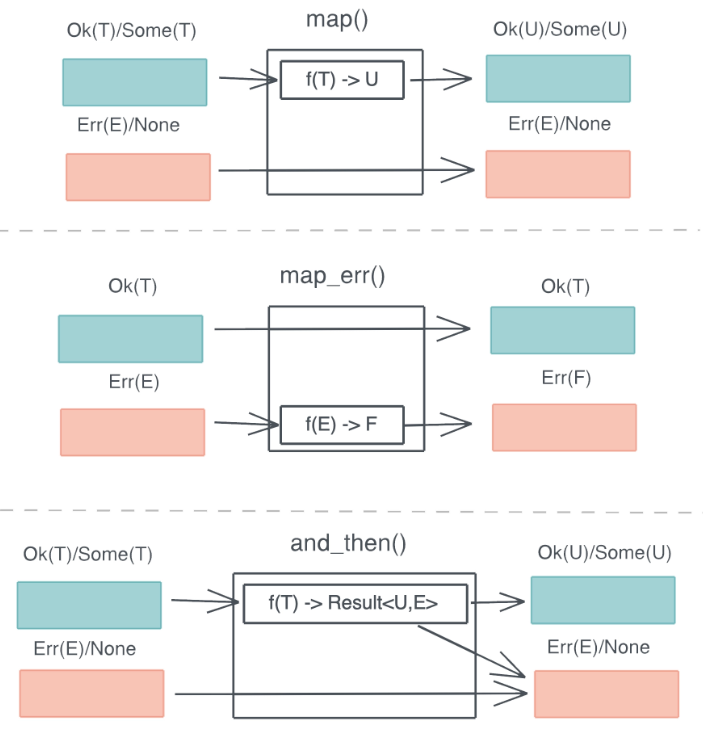
通过这些函数, 你可以很方便地对错误处理引入Railroad oriented programming 范式
4. panic! 和 catch_unwind
panic! 是不可恢复或者不想恢复的错误, 我们希望在此刻, 程序终止运行并得到崩溃信息.
Rust 标准库下提供了 catch_unwind() , 把调用栈回溯到 catch_unwind 这一刻你就可以把 Rust 代码整个封装在 catch_unwind() 函数所需要传入的闭包中. 这样, 一旦任何代码中, 包括第三方 crates 的代码, 含有能够导致 panic! 的代码, 都会被捕获, 并被转换为一个 Result.
5. Error trait 和 错误的转换
为了规范这个代表错误的数据类型的行为, Rust 定义了 Error trait:
#![allow(unused)]
fn main() {
pub trait Error: Debug + Display {
fn source(&self) -> Option<&(dyn Error + 'static)> { ... }
fn backtrace(&self) -> Option<&Backtrace> { ... }
fn description(&self) -> &str { ... }
fn cause(&self) -> Option<&dyn Error> { ... }
}
}我们可以使用 thiserror和 anyhow 来简化这个步骤. thiserror 提供了一个派生宏(derive macro)来简化错误类型的定义.
智能指针
在 Rust 中, 凡是需要做资源回收的数据结构, 且实现了 Deref/DerefMut/Drop, 都是智能指针.
#![allow(unused)]
fn main() {
pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
pub trait DerefMut: Deref {
fn deref_mut(&mut self) -> &mut Self::Target;
}
pub trait Drop {
fn drop(&mut self);
}
}1. String 和 &str
智能指针一定是一个胖指针, 但胖指针不一定是一个智能指针, 比如 &str 就只是一个胖指针, 它有指向堆内存字符串的指针, 同时还有关于字符串长度的元数据.
智能指针 String 和 &str 的区别:
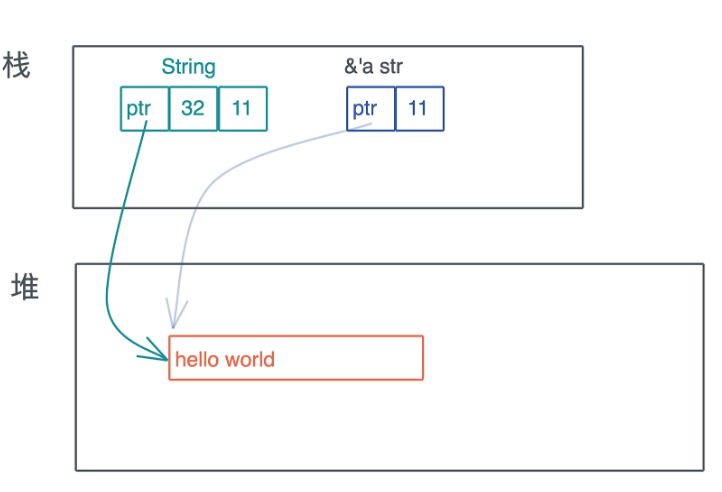
但 String 对堆上的值有所有权, 而 &str 是没有所有权的, 这是 Rust 中智能指针和普通胖指针的区别.
String 是用结构体定义的.
#![allow(unused)]
fn main() {
pub struct String {
vec: Vec<u8>,
}
}和普通的结构体不同的是, String 实现了 Deref 和 DerefMut, 这使得它在解引用的时候, 会得到 &str
#![allow(unused)]
fn main() {
impl ops::Deref for String {
type Target = str;
fn deref(&self) -> &str {
unsafe { str::from_utf8_unchecked(&self.vec) }
}
}
impl ops::DerefMut for String {
fn deref_mut(&mut self) -> &mut str {
unsafe { str::from_utf8_unchecked_mut(&mut *self.vec) }
}
}
}由于在堆上分配了数据, String 还需要为其分配的资源做相应的回收. 而 String 内部使用了 Vec, 所以它可以依赖 Vec 的能力来释放堆内存.
#![allow(unused)]
fn main() {
unsafe impl<#[may_dangle] T, A: Allocator> Drop for Vec<T, A> {
fn drop(&mut self) {
unsafe {
// use drop for [T]
// use a raw slice to refer to the elements of the vector as weakest necessary type;
// could avoid questions of validity in certain cases
ptr::drop_in_place(ptr::slice_from_raw_parts_mut(self.as_mut_ptr(), self.len))
}
// RawVec handles deallocation
}
}
}2. Box<T>
Box<T> 的定义里, 内部就是一个 Unique<T> 用于致敬 C++, Unique<T> 是一个私有的数据结构, 我们不能直接使用, 它包裹了一个 *const T 指针, 并唯一拥有这个指针.
#![allow(unused)]
fn main() {
pub struct Unique<T: ?Sized> {
pointer: *const T,
// NOTE: this marker has no consequences for variance, but is necessary
// for dropck to understand that we logically own a `T`.
//
// For details, see:
// https://github.com/rust-lang/rfcs/blob/master/text/0769-sound-generic-drop.md#phantom-data
_marker: PhantomData<T>,
}
pub struct Box<T: ?Sized,A: Allocator = Global>(Unique<T>, A)
}3. Cow<'a, B>
Cow 是 Rust 下用于提供写时克隆 (Clone-on-Write) 的一个智能指针, 它跟虚拟内存管理的写时复制 (Copy-on-write) 有异曲同工之妙: **包裹一个只读借用, 但如果调用者需要所有权或者需要修改内容, 那么它会 clone 借用的数据. **
#![allow(unused)]
fn main() {
pub enum Cow<'a, B>
where B: 'a + ToOwned + ?Sized {
Borrowed(&'a B), // 对类型 B 的只读引用
Owned(<B as ToOwned>::Owned), // 包含对类型 B 的拥有所有权的数据
}
}这里引入了两个 trait, 首先是ToOwned, 在ToOwner trait 定义的时候, 又引入了 Borrow trait, 它们都是 std::borrow 下的 trait.
#![allow(unused)]
fn main() {
pub trait ToOwned {
type Owned: Borrow<Self>;
#[must_use = "cloning is often expensive and is not expected to have side effects"]
fn to_owned(&self) -> Self::Owned;
fn clone_into(&self, target: &mut Self::Owned) { ... }
}
pub trait Borrow<Borrowed> where Borrowed: ?Sized {
fn borrow(&self) -> &Borrowed;
}
}首先 Owned: Borrow<Self> 是一个带有关联类型的 trait, 这里的 Owned 关联类型, 需要使用者定义, 并且这里的Owned 不能是任意类型, 它必须满足 Borrow<T> trait. 例如 str对 ToOwner trait 的实现:
#![allow(unused)]
fn main() {
impl ToOwned for str {
type Owned = String;
#[inline]
fn to_owned(&self) -> String {
unsafe { String::from_utf8_unchecked(self.as_bytes().to_owned()) }
}
fn clone_into(&self, target: &mut String) {
let mut b = mem::take(target).into_bytes();
self.as_bytes().clone_into(&mut b);
*target = unsafe { String::from_utf8_unchecked(b) }
}
}
}可以看到关联类型 Owned 被定义为 String, 而根据要求, String 必须定义 Borrow, 那这里 Borrow 里的泛型变量 T 是谁呢?
ToOwned 要求是 Borrow, 而此刻实现 ToOwned 的主体是 str, 所以 Borrow 是 Borrow<str>, 也就是说 String 要实现 Borrow<str>, 我们看文档, 它的确实现了这个 trait:
#![allow(unused)]
fn main() {
impl Borrow<str> for String {
#[inline]
fn borrow(&self) -> &str {
&self[..]
}
}
}Cow说它是智能指针, 那它自然需要实现 Deref trait:
#![allow(unused)]
fn main() {
impl<B: ?Sized + ToOwned> Deref for Cow<'_, B> {
type Target = B;
fn deref(&self) -> &B {
match *self {
Borrowed(borrowed) => borrowed,
Owned(ref owned) => owned.borrow(),
}
}
}
}这种根据 enum 的不同状态来进行统一分发的方法是第三种分发手段, 可以使用泛型参数做静态分发和使用 trait object 做动态分发.
4. MutexGuard<T>
MutexGuard<T> 是一类很有意思的智能指针: 它不但通过 Deref 提供良好的用户体验, 还通过 Drop trait 来确保, 使用到的内存以外的资源在退出时进行释放.
MutexGuard这个结构是在调用 Mutex::lock 时生成的:
#![allow(unused)]
fn main() {
pub fn lock(&self) -> LockResult<MutexGuard<'_, T>> {
unsafe {
self.inner.raw_lock();
MutexGuard::new(self)
}
}
}MutexGuard 的定义以及它的 Deref 和 Drop 的实现,
#![allow(unused)]
fn main() {
// 这里用 must_use, 当你得到了却不使用 MutexGuard 时会报警
#[must_use = "if unused the Mutex will immediately unlock"]
pub struct MutexGuard<'a, T: ?Sized + 'a> {
lock: &'a Mutex<T>,
poison: poison::Guard,
}
impl<T: ?Sized> Deref for MutexGuard<'_, T> {
type Target = T;
fn deref(&self) -> &T {
unsafe { &*self.lock.data.get() }
}
}
impl<T: ?Sized> DerefMut for MutexGuard<'_, T> {
fn deref_mut(&mut self) -> &mut T {
unsafe { &mut *self.lock.data.get() }
}
}
impl<T: ?Sized> Drop for MutexGuard<'_, T> {
#[inline]
fn drop(&mut self) {
unsafe {
self.lock.poison.done(&self.poison);
self.lock.inner.raw_unlock();
}
}
}
}MuxteGuard 不允许Send, 只允许Sync. 就是说, 你可以把 MutexGuard 的引用传给另一个线程使用, 但你无法把 MutexGuard 整个 move 到另一个线程.
标准 trait
1. 内存相关: Clone/Copy/Drop
1.1 Clone trait
#![allow(unused)]
fn main() {
pub trait Clone {
fn clone(&self) -> Self;
fn clone_from(&mut self, source: &Self) {
*self = source.clone()
}
}
}clone_from方法在实例a已经存在, 在clone过程中会分配内存, 那么用a.clone_from(&b)可以避免内存分配, 提高效率.
Clone trait可以通过派生宏直接实现#[derive(Clone)].
1.2 Copy trait
#![allow(unused)]
fn main() {
pub trait Copy: Clone {}
}这个trait没有任何行为, 但它可以用作 trait bound 来进行类型安全检查, 所以叫 标志trait
Copy trait可以通过派生宏直接实现#[derive(Copy)].
1.3 Drop trait
#![allow(unused)]
fn main() {
pub trait Drop {
fn drop(&mut self);
}
}大部分场景无需为数据结构提供 Drop trait, 系统默认会依次对数据结构的每个域做 drop. 但有两种情况你可能需要手工实现 Drop.
- 希望在数据结束生命周期的时候做一些事情, 比如记日志.
- 需要对资源回收的场景. 编译器并不知道你额外使用了哪些资源, 也就无法帮助你
drop它们. 比如说锁资源的释放, 在MutexGuard中实现了Drop来释放锁资源
注意:
Copy trait和Drop trait是互斥的, 两者不能共存, 当你尝试为同一种数据类型实现Copy时, 同时也实现Drop, 编译器就会报错. 这其实很好理解:**Copy是按位做浅拷贝, 那么它会默认拷贝的数据没有需要释放的资源;而Drop恰恰是为了释放额外的资源而生的. **
2. 标记 trait: Sized/Send/Sync/Unpin
2.1 Sized trait
#![allow(unused)]
fn main() {
pub trait Sized { }
}Sized trait 用于标记有具体大小的类型. 在使用泛型参数时, Rust 编译器会自动为泛型参数加上 Sized 约束.
大部分时候, 我们都希望能自动添加这样的约束, 因为这样定义出的泛型结构, 在编译期, 大小是固定的, 可以作为参数传递给函数.
在少数情况下, 需要 T 是可变类型的 那么需要?Sized 来摆脱这个约束.
#![allow(unused)]
fn main() {
// 这样B就可以是[T]或者str类型,大小都不固定.
// 注意 Borrowed(&'a B) 大小是固定的, 因为它是对B的一个引用, 而且引用的大小是固定的.
pub enum Cow<'a, B: ?Sized + 'a> where B: ToOwned,
{
// 借用的数据
Borrowed(&'a B),
// 拥有的数据
Owned(<B as ToOwned>::Owned),
}
}2.2 Send/Sync
#![allow(unused)]
fn main() {
pub unsafe auto trait Send {}
pub unsafe auto trait Sync {}
}这两个 trait 都是 unsafe auto trait, auto 意味着编译器会在合适的场合, 自动为数据结构添加它们的实现, 而 unsafe 代表实现的这个 trait 可能会违背 Rust 的内存安全准则, 如果开发者手工实现这两个 trait , 要自己为它们的安全性负责.
Send/Sync 是 Rust 并发安全的基础:
- 如果一个类型
T实现了Send trait, 意味着T可以安全地从一个线程移动到另一个线程, 也就是说所有权可以在线程间移动. - 如果一个类型
T实现了Sync trait, 则意味着&T可以安全地在多个线程中共享. 一个类型T满足Sync trait, 当且仅当&T满足Send trait.
对于 Send/Sync 在线程安全中的作用, 可以这么看, **如果一个类型 T: Send, 那么 T 在某个线程中的独占访问是线程安全的;如果一个类型 T: Sync, 那么 T 在线程间的只读共享是安全的. **
对于我们自己定义的数据结构, 如果其内部的所有域都实现了 Send / Sync, 那么这个数据结构会被自动添加 Send / Sync.
标准库中, 不支持 Send / Sync 的数据结构主要有:
- 裸指针
*const T/*mut T. 它们是不安全的, 所以既不是Send也不是Sync. UnsafeCell不支持Sync. 也就是说, 任何使用了Cell或者RefCell的数据结构不支持Sync.- 引用计数
Rc不支持Send也不支持Sync. 所以Rc无法跨线程.
2.3 Unpin
todo.
3. 类型转换: From/Into/AsRef/AsMut
3.1 From / Into 和 TryFrom / TryInto
#![allow(unused)]
fn main() {
pub trait From<T> {
fn from(T) -> Self;
}
pub trait Into<T> {
fn into(self) -> T;
}
// 实现 From 会自动实现 Into
impl<T, U> Into<U> for T where U: From<T> {
fn into(self) -> U {
U::from(self)
}
}
// From(Into)是自反的
// 把类型 T 的值转换成类型 T, 会直接返回
impl<T> From<T> for T {
fn from(t: T) -> T {
t
}
}
}From<T> 可以根据上下文做类型推导, 使用场景更多;而且实现了 From<T> 会自动实现 Into<T>, 反之不会. 所以需要的时候, 只要实现 From<T> 即可.
而且From<T>(Into<T>)是自反的, 把类型 T 的值转换成类型 T, 会直接返回, 这样在接口设计时变得灵活, 比如函数接受一个IpAddr为参数, 我们可以使用Into<IpAddr>让更多的类型被这个函数使用.
#![allow(unused)]
fn main() {
use std::net::IpAddr;
fn print(v: impl Into<IpAddr>) {
println!("{:?}", v.into());
}
}合理地使用From<T> / Into<T>, 可以让代码变得简洁, 符合 Rust 可读性强的风格, 更符合开闭原则.
注意, 如果你的数据类型在转换过程中有可能出现错误, 可以使用 TryFrom<T> 和 TryInto<T>, 用法与From<T>/ Into<T> 一样
#![allow(unused)]
fn main() {
pub trait TryFrom<T> {
type Error;
fn try_from(value: T) -> Result<Self, Self::Error>;
}
pub trait TryInto<T> {
type Error;
fn try_into(self) -> Result<T, Self::Error>;
}
}3.2 AsRef / AsMut
AsRef<T> 和 AsMut<T> 就很好理解了, 用于从引用到引用的转换.
在 trait 的定义上, 都允许 T 使用大小可变的类型, 如 str、[u8] 等. AsMut<t> 除了使用可变引用生成可变引用外, 其它都和 AsRef<T> 一样.
注意, 如果你的代码出现 v.as_ref().clone() 这样的语句, 也就是说你要对 v 进行引用转换, 然后又得到了拥有所有权的值, 那么你应该实现 From<T>, 然后做 v.into().
#![allow(unused)]
fn main() {
pub trait AsRef<T> where T: ?Sized {
fn as_ref(&self) -> &T;
}
pub trait AsMut<T> where T: ?Sized {
fn as_mut(&mut self) -> &mut T;
}
}4. Deref / DerefMut
#![allow(unused)]
fn main() {
pub trait Deref {
// 解引用出来的结果类型
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
pub trait DerefMut: Deref {
fn deref_mut(&mut self) -> &mut Self::Target;
}
}
5. Debug / Display / Default
#![allow(unused)]
fn main() {
pub trait Debug {
fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>;
}
pub trait Display {
fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>;
}
pub trait Default {
fn default() -> Self;
}
}Debug 和 Display 两个 trait 的签名一样, 都接受一个 &self 和一个 &mut Formatter.
Debug是为开发者调试打印数据结构所设计的, 可以通过派生宏直接生成.通过{:?}来打印.Display是给用户显示数据结构所设计的, 必须手工实现.通过{}打印.
Default trait 用于为类型提供缺省值. 它也可以通过 derive 宏 #[derive(Default)] 来生成实现, 前提是类型中的每个字段都实现了 Default trait.
总结

类型系统: 泛型
1. 泛型参数的三种使用场景
- 使用泛型参数延迟数据结构的绑定
- 使用泛型参数和
PhantomData, 声明数据结构中不直接使用, 但在实现过程中需要用到的类型. - 使用泛型参数让同一个数据结构对同一个
trait可以有不同的实现
1.1 泛型参数做延迟绑定
#![allow(unused)]
fn main() {
/// Service 数据结构
pub struct Service<Store = MemTable> {
inner: Arc<ServiceInner<Store>>,
}
}它使用了一个泛型参数Store, 并且这个泛型参数有一个缺省值, 在使用时可以不必提供泛型参数, 直接使用缺省值. 这个泛型参数在随后的实现中可以被逐渐约束.
#![allow(unused)]
fn main() {
impl<Store> Service<Store> {
pub fn new(store: Store) -> Self { ... }
}
impl<Store: Storage> Service<Store> {
pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { ... }
}
}1.2 使用泛型参数和幽灵数据 (PhantomData) 提供额外类型
设计一个 User 和 Product 数据结构, 它们都有一个 u64 类型的 id. 然而我希望每个数据结构的 id 只能和同种类型的 id 比较.
#![allow(unused)]
fn main() {
use std::marker::PhantomData;
#[derive(Debug, Default, PartialEq, Eq)]
pub struct Identifier<T> {
inner: u64,
_tag: PhantomData<T>,
}
#[derive(Debug, Default, PartialEq, Eq)]
pub struct User {
id: Identifier<Self>,
}
#[derive(Debug, Default, PartialEq, Eq)]
pub struct Product {
id: Identifier<Self>,
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn id_should_not_be_the_same() {
let user = User::default();
let product = Product::default();
// 两个 id 不能比较, 因为他们属于不同的类型
// assert_ne!(user.id, product.id);
assert_eq!(user.id.inner, product.id.inner);
}
}
}让我们可以用 PhantomData 来持有 Phantom Type. PhantomData 中文一般翻译成幽灵数据, 这名字透着一股让人不敢亲近的邪魅, 但它被**广泛用在处理, 数据结构定义过程中不需要, 但是在实现过程中需要的泛型参数. **
1.3 使用泛型参数来提供多个实现
用泛型数据结构来统一相同的逻辑, 用泛型参数的具体类型来处理变化的逻辑.
我们写代码的首要目标是正确地实现所需要的功能, 在正确性的前提下, 优雅简洁的表达才有意义.
类型系统: trait
参考资料
用于处理借用数据的模块: std::borrow
1 Borrow
#![allow(unused)]
fn main() {
pub trait Borrow<Borrowed>
where
Borrowed: ?Sized,
{
// Required method
fn borrow(&self) -> &Borrowed;
}
}一个用于借用数据的trait.
通过实现Borrow<T>来表达它们可以作为其个类型T借出.并在trait的borrow方法中提供对T的引用.
例如: String实现了Borrow<str>,则可以作为str进行借出, Box<T>实现了Borrow<T>,则可以作为T进行借出
2. BorrowMut
#![allow(unused)]
fn main() {
pub trait BorrowMut<Borrowed>: Borrow<Borrowed>
where
Borrowed: ?Sized,
{
// Required method
fn borrow_mut(&mut self) -> &mut Borrowed;
}
}一个用于可变借用数据的trait.
作为Borrow<T>的补充,该trait允许类型通过提供可变引用来借用底层类型.
3. ToOwned
#![allow(unused)]
fn main() {
pub trait ToOwned {
type Owned: Borrow<Self>;
// Required method
fn to_owned(&self) -> Self::Owned;
// Provided method
fn clone_into(&self, target: &mut Self::Owned) { ... }
}
}Clone在借用数据上的泛化.
Clone一般是&T到T, ToOwned trait 将Clone泛化, 可以从给定类型的任何借用中构造拥有数据.
这里关联类型Owned需要满足Borrow<Self> trait, 此处Self为要实现ToOwned的结构.
看下 str对ToOwned trait 的实现:
#![allow(unused)]
fn main() {
impl ToOwned for str {
type Owned = String
// Required method
fn to_owned(&self) -> Self::Owned { ... }
// Provided method
fn clone_into(&self, target: &mut Self::Owned) { ... }
}
}关联类型Owned被定义为String, 而根据要求,String必须定义Borrow<T>,那这里Borrow里的泛型变量T是谁呢?ToOwned要求是Borrow<Self>,而此刻实现 ToOwned 的主体是 str,所以 Borrow<Self> 是 Borrow<str>, 而String的确实现了Borrow<str>.
4. Cow
#![allow(unused)]
fn main() {
pub enum Cow<'a, B>
where
B: 'a + ToOwned + ?Sized,
{
Borrowed(&'a B),
Owned(<B as ToOwned>::Owned),
}
}Cow用于提供写时克隆(Clone-on-Write)的一个智能指针,包裹一个只读借用,但如果调用者需要所有权或者需要修改内容,那么它会 clone 借用的数据.
Cow实现了Deref trait.
#![allow(unused)]
fn main() {
impl<B: ?Sized + ToOwned> Deref for Cow<'_, B> {
type Target = B;
fn deref(&self) -> &B {
match *self {
Borrowed(borrowed) => borrowed,
Owned(ref owned) => owned.borrow(),
}
}
}
}如何阅读源码
以下是 Rust 文档为例
读Rust代码的基本顺序:
- 从
crate的大纲开始, 先了解目标代码能干什么,怎么用. - 学习核心
trait, 看看它支持哪些功能. - 掌握主要的数据结构, 开始写一些示例代码
- 围绕自己感兴趣的情景深入阅读.
1. 从大纲开始
Rust 几乎所有库的文档都在 docs.rs 下, 比如 Bytes 的文档可以通过 docs.rs/bytes 访问
- trait
- struct
- 函数/方法
和写代码的思考方式非常类似:
- 先从需求的流程中敲定系统的行为, 需要定义什么接口 trait;
- 再考虑系统有什么状态, 定义了哪些数据结构 struct;
- 最后到实现细节, 包括如何为数据结构实现 trait、数据结构自身有什么算法、如何把整个流程串起来等等.
2. 熟悉核心 trait 的行为
所以先看 trait, 我们以 Buf trait 为例. 点进去看文档, 主页面给了这个 trait 的定义和一个使用示例.
左侧导航栏的 “required Methods” 和 “Provided Methods”, 前者是实现这个 trait 需要实现的方法, 后者是缺省方法.
导航栏继续往下拉, 可以看到 bytes 为哪些 “foreign types” 实现了 Buf trait, 以及当前模块有哪些 implementors.
可以学习到高手定义 trait 的一些思路:
- 定义好
trait后, 可以考虑一下标准库的数据结构, 哪些可以实现这个 trait. - 如果未来别人的某个类型
T, 实现了你的trait, 那他的&T、&mut T、Box等衍生类型, 是否能够自动实现这个 trait.
3. 掌握主要的 struct
和 trait 类似的, 在左侧的导航栏, 有一些值得关注的信息:这个数据结构有哪些方法 (Methods) 、实现了哪些 trait (Trait implementations) , 以及 Auto trait / Blanket trait 的实现. 可以看到, Bytes 除了实现了刚才讲过的 Buf trait 外, 还实现了很多标准 trait.
所以: 我们自己的数据结构, 也应该尽可能实现需要的标准 trait, 包括但不限于:AsRef、Borrow、Clone、Debug、Default、Deref、Drop、PartialEq/Eq、From、Hash、IntoIterator (如果是个集合类型) 、PartialOrd/Ord 等
4. 深入研究实现逻辑
actix-web
handler 原理
1.1 剖析
在 actix-web 中,路由设置 handler 的方法 定义如下:
#![allow(unused)]
fn main() {
pub fn to<F, Args>(self, handler: F) -> Self
where
F: Handler<Args>,
Args: FromRequest + 'static,
F::Output: Responder + 'static,
{
self.service = handler_service(handler);
self
}
}参数handler的约束为Handler<Args>, 其定义如下:
#![allow(unused)]
fn main() {
pub trait Handler<Args>: Clone + 'static {
type Output;
type Future: Future<Output = Self::Output>;
fn call(&self, args: Args) -> Self::Future;
}
}这里的Args就代表n个参数.
结合这两个来看, to函数中Handler<Args>的Args需要实现FromRequest trait 就可以作为参数, 而Handler<Args>的关联类型Output需要实现Responder trait.
但是Args是如何实现动态参数的呢, 来看下to函数的handler_service方法:
#![allow(unused)]
fn main() {
pub(crate) fn handler_service<F, Args>(handler: F) -> BoxedHttpServiceFactory
where
F: Handler<Args>,
Args: FromRequest,
F::Output: Responder,
{
boxed::factory(fn_service(move |req: ServiceRequest| {
let handler = handler.clone();
async move {
let (req, mut payload) = req.into_parts();
let res = match Args::from_request(&req, &mut payload).await {
Err(err) => HttpResponse::from_error(err),
Ok(data) => handler
.call(data)
.await
.respond_to(&req)
.map_into_boxed_body(),
};
Ok(ServiceResponse::new(req, res))
}
}))
}
}这里的handler的约束和上而的to区别不大,看下里面的实现,同上面所说Args只需要实现FromRequest就可以拿来做参数, 换句话说, 实现了 FromRequest 你可以在 Handle 方法中的任意参数位置写上你要的参数名和类型.
通过Args::FromRequest提取出参数,就调用handler.call方法执行你的接口, 如何失败则返回FromRequest中定义的Error, 所以你可以随意定义参数提取失败之后返回的内容.
但是问题来了, Args如何实现支持多个参数, 在源码里找到以下定义:
#![allow(unused)]
fn main() {
macro_rules! tuple_from_req {
($fut: ident; $($T: ident),*) => {
/// FromRequest implementation for tuple
#[allow(unused_parens)]
impl<$($T: FromRequest + 'static),+> FromRequest for ($($T,)+)
{
type Error = Error;
type Future = $fut<$($T),+>;
fn from_request(req: &HttpRequest, payload: &mut Payload) -> Self::Future {
$fut {
$(
$T: ExtractFuture::Future {
fut: $T::from_request(req, payload)
},
)+
}
}
}
pin_project! {
pub struct $fut<$($T: FromRequest),+> {
$(
#[pin]
$T: ExtractFuture<$T::Future, $T>,
)+
}
}
impl<$($T: FromRequest),+> Future for $fut<$($T),+>
{
type Output = Result<($($T,)+), Error>;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
let mut this = self.project();
let mut ready = true;
$(
match this.$T.as_mut().project() {
ExtractProj::Future { fut } => match fut.poll(cx) {
Poll::Ready(Ok(output)) => {
let _ = this.$T.as_mut().project_replace(ExtractFuture::Done { output });
},
Poll::Ready(Err(e)) => return Poll::Ready(Err(e.into())),
Poll::Pending => ready = false,
},
ExtractProj::Done { .. } => {},
ExtractProj::Empty => unreachable!("FromRequest polled after finished"),
}
)+
if ready {
Poll::Ready(Ok(
($(
match this.$T.project_replace(ExtractFuture::Empty) {
ExtractReplaceProj::Done { output } => output,
_ => unreachable!("FromRequest polled after finished"),
},
)+)
))
} else {
Poll::Pending
}
}
}
};
}
impl FromRequest for () {
type Error = Infallible;
type Future = Ready<Result<Self, Self::Error>>;
fn from_request(_: &HttpRequest, _: &mut Payload) -> Self::Future {
ok(())
}
}
tuple_from_req! { TupleFromRequest1; A }
tuple_from_req! { TupleFromRequest2; A, B }
tuple_from_req! { TupleFromRequest3; A, B, C }
tuple_from_req! { TupleFromRequest4; A, B, C, D }
tuple_from_req! { TupleFromRequest5; A, B, C, D, E }
tuple_from_req! { TupleFromRequest6; A, B, C, D, E, F }
tuple_from_req! { TupleFromRequest7; A, B, C, D, E, F, G }
tuple_from_req! { TupleFromRequest8; A, B, C, D, E, F, G, H }
tuple_from_req! { TupleFromRequest9; A, B, C, D, E, F, G, H, I }
tuple_from_req! { TupleFromRequest10; A, B, C, D, E, F, G, H, I, J }
tuple_from_req! { TupleFromRequest11; A, B, C, D, E, F, G, H, I, J, K }
tuple_from_req! { TupleFromRequest12; A, B, C, D, E, F, G, H, I, J, K, L }
}这里把Args的一堆 tuple, (),A,A, B…都实现了,所以在 handler_service 里的 Args 实际上是一个 tuple,并在里面逐个调用参数的from_request, 接口的参数限制最多12个, 当超过12个参数时就会报错. 这就回答了上面Args支持多个参数.
这里又出新了一个新的问题, 参数解析出来了, 但是 handler.call(data)如何支持多个参数, 看实现, Handler<Args> 给fn各种长度参数fn() -> R, fn(A, B, C) -> R 实现了最多12个参数.
#![allow(unused)]
fn main() {
/// Generates a [`Handler`] trait impl for N-ary functions where N is specified with a sequence of
/// space separated type parameters.
///
/// # Examples
/// ```ignore
/// factory_tuple! {} // implements Handler for types: fn() -> R
/// factory_tuple! { A B C } // implements Handler for types: fn(A, B, C) -> R
/// ```
macro_rules! factory_tuple ({ $($param:ident)* } => {
impl<Func, Fut, $($param,)*> Handler<($($param,)*)> for Func
where
Func: Fn($($param),*) -> Fut + Clone + 'static,
Fut: Future,
{
type Output = Fut::Output;
type Future = Fut;
#[inline]
#[allow(non_snake_case)]
fn call(&self, ($($param,)*): ($($param,)*)) -> Self::Future {
(self)($($param,)*)
}
}
});
factory_tuple! {}
factory_tuple! { A }
factory_tuple! { A B }
factory_tuple! { A B C }
factory_tuple! { A B C D }
factory_tuple! { A B C D E }
factory_tuple! { A B C D E F }
factory_tuple! { A B C D E F G }
factory_tuple! { A B C D E F G H }
factory_tuple! { A B C D E F G H I }
factory_tuple! { A B C D E F G H I J }
factory_tuple! { A B C D E F G H I J K }
factory_tuple! { A B C D E F G H I J K L }
}1.2 总结
rust日记
你应知道的crate
基础库
- overload Simplified operator overloading in Rust
- enum-iterator Tools to iterate over all values of a type
- cfg-if A if/elif-like macro for Rust #[cfg] statements
- arrayref Two macros for taking array references in rust.
- Educe This crate provides procedural macros to help you implement Rust-built-in traits quickly.
- rust-derivative A set of alternative
deriveattributes for Rust - tap Generic extensions for tapping values in Rust.
- strum A small rust library for adding custom derives to enums.
- derive_more Some more derive(Trait) options.
- rust-derive-builderderive builder implementation for rust structs.
- enum_dispatch Near drop-in replacement for dynamic-dispatched method calls with up to 10x the speed.
- paste Macros for all your token pasting needs.
- num A collection of numeric types and traits for Rust.
- either The enum Either with variants Left and Right is a general purpose sum type with two cases.
- thiserror derive(Error) for struct and enum error types.
- rayon A data parallelism library for Rust.
- Crossbeam About Tools for concurrent programming in Rust.
- async_trait Type erasure for async trait methods.
- fs-err A simple wrapper around filesystem operations to provide more helpful error messages.
- tempfile Temporary file library for rust.
- bincode A binary encoder / decoder implementation in Rust.
- maplit Rust container / collection literal macros for HashMap, HashSet, BTreeMap, BTreeSet.
- indexmap A hash table with consistent order and fast iteration; access items by key or sequence index.
不可变数据建议Rc<[T]>/Arc<[T]>替代Vec<[T]>
slice 对于不可变数据, Arc<[T]>可能是比 Vec<T> 更好的选择, 因此, 如果你在构建一个大数据序列, 并且
之后不会修改, 那么考虑 Rc<[T]>, 它非常适合存储的数据或数组或集合或只是传递一般引用.
看下内存模型就明白了:
#![allow(unused)]
fn main() {
stack
[ptr |meta]
+–––-+–––+
│ * │ │
+–│-–+--–│
|
heap |
+–V–+–––+–––+
│ │ │ T │
+–––+--–+–––+
/ │
ref count <–/ V
weak ref count
}(译)Rust临时生命周期和“Super Let“1
在Rust中, 临时变量生命周期是一个复杂但又经常被忽视的话题. 在一些简单的情况下, Rust会让临时变量存活足够长的时间, 这样我们就不必考虑它们了. 然而, 在很多情况下, 我们可能无法立即得到我们想要的东西.
在这篇文章中, 我们将(重新)发掘临时变量生命周期的规则, 介绍一些临时生命周期扩展的用例, 并探索一种新的语言理念–super let,, 为我们提供更多控制.
临时变量
下面是一条Rust语句, 没有上下文, 使用的是临时String:
#![allow(unused)]
fn main() {
f(&String::from('🦀'));
}这个临时String的存活时间多长?如果我们今天设计Rust, 基本上有两种选择:
- 在调用
f之前, 字符串会被立即丢弃. 或者 - 只有在调用
f后, 字符串才会被丢弃.
如果我们选择方案1, 那么上面的语句将始终导致借用检查错误, 因为我们不能让f借用已经消失的东西.
因此, Rust选择了方案2: 首先分配字符串, 然后将其引用传递给f, 只有在f返回后, 我们才会丢弃临时字符串.
在一个 let 语句中
现在是一个稍难的问题:
#![allow(unused)]
fn main() {
let a = f(&String::from('🦀'));
…
g(&a);
}再来: 这个临时String的存活时间多长?
- 字符串会在
let语句结束时丢弃: 即在f返回之后, 但在g被调用之前. 或者 - 字符串会在调用
g之后的同时a被丢弃.
如果f被定义为 fn f(s: &str) -> usize(如str::len), 那么在let语句后立即去掉String就完全没问题了.
但是, 如果f被定义为 fn f(s: &str) -> &[u8](就像 str::as_bytes), 那么 a 就会从临时变量 String 中借用, 因此如果我们将a保留较长时间, 就会出现借用检查错误.
如果采用方案2, 在这两种情况下都能正常编译, 但我们可能会在超出必要的存活时间内保留一个临时变量, 这可能会浪费资源或导致微妙的错误(例如, 当MutexGuard比预期时间晚丢弃时会造成死锁).
这听起来像是第3种选择: 让它取决于f的签名.
但是, Rust的借用检查器只执行检查, 并不影响代码的行为. 出于各种原因, 这是一个非常重要和有用的属性. 举例来说, 将 fn f(s:&str)->&[u8](返回值借用参数)改为 fn f(s:&str)->&'static[u8](返回值不借用参数)并不会改变调用位置的任何内容, 例如临时变量被丢弃的位置.
因此, 在方案1和方案2之间, Rust选择了方案1: 在let语句末尾删除临时变量. 很容易手动将String移到单独的let语句中, 让它保持更长的时间.
#![allow(unused)]
fn main() {
let s = String::from('🦀'); // Moved to its own `let` to give it a longer lifetime.
let a = f(&s);
…
g(&a);
}在嵌套调用中
好吧, 再来一个:
#![allow(unused)]
fn main() {
g(f(&String::from('🦀')));
}同样, 有两种选择:
- 在调用
f之后、调用g之前, 字符串被丢弃. 或者 - 字符串会在语句结束时丢弃, 所以是在调用
g之后.
该代码段与前一个代码段几乎完全相同: 临时String的引用被传递给f, f的返回值被传递给g.
不过, 方案1可能有效, 也可能无效, 这取决于f的签名, 而方案2可能会让临时变量存活更长的时间.
不过, 这次方案1会给程序员带来更多惊喜. 例如, 即使是简单的 String::from('🦀').as_bytes().contains(&0x80) 也无法编译, 因为字符串会在 as_bytes(f) 之后、contains (g) 之前被删除.
也可以说, 把临时变量多存活一段时间的坏处要小得多, 因为他们在声明结束时仍然会被丢弃.
因此, Rust选择了方案2: 无论f的签名如何, 字符串都会一直存在, 直到语句结束, 直到g被调用.
在一个 if 语句中
现在, 我们来看看简单的 if 语句:
#![allow(unused)]
fn main() {
if f(&String::from('🦀')) {
…
}
}同样的问题: String 何时丢弃?
- 在
if的条件求值之后, 但在if的主体执行之前(即在{处). 或者 - 在
if主体执行之后(即在}处).
在这种情况下, 就没有理由在if主体中保留临时值. 条件的结果是一个布尔值(只有true或false), 顾名思义, 这并不借用任何东西.
因此, Rust选择方案1.
例如, 在使用 Mutex::lock 时, 它就会返回一个临时MutexGuard, 当Mutex被丢弃时, 它就会解锁:
#![allow(unused)]
fn main() {
fn example(m: &Mutex<String>) {
if m.lock().unwrap().is_empty() {
println!("the string is empty!");
}
}
}在这里, m.lock().unwrap()中的临时MutexGuard会在.is_empty()之后丢弃, 这样Mutex就不会在println语句中被不必要地锁定.
在 if let 语句中
但 if let(和 match)的情况有所不同, 因为此时我们的表达式并不一定是评估布尔值:
#![allow(unused)]
fn main() {
if let … = f(&String::from('🦀')) {
…
}
}再次, 有两种选择:
- 在模式匹配之后、
if let的正文之前(即{处)删除字符串. 或者、 - 在
if let主体之后(即}处)删除字符串.
这一次, 我们有理由选择方案2而不是方案1, 在if let语句或match中借用模式是很常见的.
因此, 在这种情况下, Rust选择了方案2.
例如, 如果我们有一个Mutex<Vec<T>>类型的vec, 编译起来就很好:
#![allow(unused)]
fn main() {
if let Some(x) = vec.lock().unwrap().first() {
// The mutex is still locked here. :)
// This is necessary, because we're borrowing `x` from the `Vec`. (`x` is a `&T`)
println!("first item in vec: {x}");
}
}我们从m.lock().unwrap()获得一个临时的MutexGuard, 并使用.first()方法借用第一个元素. 由于MutexGuard只在最后一个 }才被丢弃, 因此借用将持续整个if let主体.
不过, 在有些情况下, 这并不是我们想要的. 例如, 如果我们使用pop代替first, 它返回的是值而不是引用:
#![allow(unused)]
fn main() {
if let Some(x) = vec.lock().unwrap().pop() {
// The mutex is still locked here. :(
// This is unnecessary, because we don't borrow anything from the `Vec`. (`x` is a `T`)
println!("popped item from the vec: {x}");
}
}这可能会令人惊讶, 并导致微妙的错误或性能降低.
也许这就是Rust选择错误方案的一个论据, 也许这就是在未来版本的Rust中改变这一规则的一个论据. 关于如何修改这些规则的想法, 请参阅 Niko’s blog post on this topic.
目前, 解决方法是使用一个单独的let 语句, 将临时生命周期限制在该语句中:
#![allow(unused)]
fn main() {
let x = vec.lock().unwrap().pop(); // The MutexGuard is dropped after this statement.
if let Some(x) = x {
…
}
}临时生命周期扩展
这种情况如何?
#![allow(unused)]
fn main() {
let a = &String::from('🦀');
…
f(&a);
}两种选择:
- 字符串会在
let语句的末尾被丢弃. 或者 - 在调用
f后, 字符串与a同时被删除.
方案1 总是会导致借用检查错误. 因此, 方案2可能更有意义. 如今Rust也确实是这样工作的: 临时生命周期被扩展了, 因此上面的代码段可以正常编译.
这种临时变量生命周期长于它在声明中出现的时间的现象被称为临时生命周期扩展.
临时生命周期扩展并不适用于所有出现在let语句中的临时字符串, 正如我们已经看到的那样: let a = f(&String::from('🦀')); 中的临时字符串不会超过 let语句的生命周期.
在let a = &f(&String::from('🦀'));(注意多出的 &)中, 临时生命周期扩展确实适用于最外层的&, 它借用了作为f 返回值的临时, 但不适用于内层的&, 它借用了String.
例如, 用str::len 代替f:
#![allow(unused)]
fn main() {
let a: &usize = &String::from('a').len();
}在这里, 字符串在 let 语句的末尾被删除, 但 .len()返回的usize和a活的一样长.
这不仅限于 let _ = &...; 语法. 例如
#![allow(unused)]
fn main() {
let a = Person {
name: &String::from('🦀'), // Extended!
address: &String::from('🦀'), // Extended!
};
}在上面的代码段中, 临时字符串的生命周期将被扩展, 因为即使我们对 Person 类型一无所知, 我们也可以肯定, 生命周期扩展对于生成对象之后的可用性是必要的.
关于 let 语句中哪些临时变量的生命周期会被延长, temporary lifetime extension in Rust Reference中有详细的说明, 但实际上只适用于那些从语法上就能看出有必要延长生命周期的表达式, 而与任何类型、函数签名或特质实现无关:
#![allow(unused)]
fn main() {
let a = &temporary().field; // Extended!
let a = MyStruct { field: &temporary() }; // Extended!
let a = &MyStruct { field: &temporary() }; // Both extended!
let a = [&temporary()]; // Extended!
let a = { …; &temporary() }; // Extended!
let a = f(&temporary()); // Not extended, because it might not be necessary.
let a = temporary().f(); // Not extended, because it might not be necessary.
let a = temporary() + temporary(); // Not extended, because it might not be necessary.
}虽然这看起来很合理, 但当我们考虑到构造元组结构或元组变体的语法只是一个函数调用时, 确实会感到意外: 从语法上讲, Some(123) 是对函数 Some 的函数调用.
例如:
#![allow(unused)]
fn main() {
let a = Some(&temporary()); // Not extended! (Because `Some` could have any signature...)
let a = Some { 0: &temporary() }; // Extended! (I bet you have never used this syntax.)
}这可能会让人相当困惑.
这也是值得考虑重新修订规则的原因之一.
持续推广
临时生命周期扩展很容易与另一种叫不断晋升的东西混淆, 后者是临时变量获得比预期生命周期长的另一种方式.
在&123和&None这样的表达式中, 值被认定为常量(without interior mutability and without desctructors), 因此会自动晋升为永生值. 这意味着这些引用将具有'static生命周期.
例如:
#![allow(unused)]
fn main() {
let x = f(&3); // The &3 here is 'static, regardless if that's necessary for `f()`.
}This even applies to simple expressions:
#![allow(unused)]
fn main() {
let x = f(&(1 + 2)); // The &3 here is 'static.
}在同时适用临时生命周期延长和恒定提升的情况下, 后者优先, 因为它延长的生命周期最长:
#![allow(unused)]
fn main() {
let x = &1; // constant promotion, not temporary lifetime extension.
}也就是说, 在上面的代码段中, x是一个'static引用. 值1的寿命甚至比x本身还长.
代码块中的临时生命周期扩展
想象一下, 我们有某种Writer类型, 它持有一个要写入的文件的引用:
#![allow(unused)]
fn main() {
pub struct Writer<'a> {
pub file: &'a File
}
}以下代码创建了Writer, 写入新创建的文件:
#![allow(unused)]
fn main() {
println!("opening file...");
let filename = "hello.txt";
let file = File::create(filename).unwrap();
let writer = Writer { file: &file };
}现在的作用域包含filename、file和writer. 然而, 后面的代码只能通过
Writer写入. 理想的情况是, 在作用域中已经看不到filename, 尤其是file.
由于临时生命周期扩展也适用于代码块的最终表达式, 因此我们可以通过以下方式来实现:
#![allow(unused)]
fn main() {
let writer = {
println!("opening file...");
let filename = "hello.txt";
Writer { file: &File::create(filename).unwrap() }
};
}现在, Writer的创建被整齐地封装在它自己的作用域中, 这样外层作用域只能看到 writer, 而看不到其他任何东西.得益于临时生命周期的扩展, 在内作用域中作为临时创建的file与 writer 一样的存活时间.
临时生命周期扩展的限制
试想一下, 如果我们将Writer结构中的file字段设置为私有, 会是怎样的结果?
#![allow(unused)]
fn main() {
pub struct Writer<'a> {
file: &'a File
}
impl<'a> Writer<'a> {
pub fn new(file: &'a File) -> Self {
Self { file }
}
}
}这样, 我们就不需要对原始用法片段做太多改动了:
#![allow(unused)]
fn main() {
println!("opening file...");
let filename = "hello.txt";
let file = File::create(filename).unwrap();
let writer = Writer::new(&file); // Only this line changed.
}我们只需调用Writer::new()而不是使用Writer {}语法来构建.
不过, 这对作用域版本无效:
#![allow(unused)]
fn main() {
let writer = {
println!("opening file...");
let filename = "hello.txt";
Writer::new(&File::create(filename).unwrap()) // Error: Does not live long enough!
};
writer.something(); // Error: File no longer alive here!
}正如我们之前看到的, 虽然临时生命周期扩展会通过Writer {}结构语法传播, 但不会通过Writer::new()函数调用语法传播. (例如, 签名可以是fn new(&File) -> Self<'static>或fn new(&File) -> i32, 这样就不需要扩展临时生命周期了).
遗憾的是, 我们无法明确选择临时生命周期扩展.我们必须在最外层作用域中设置一个let file.目前我们能做的最好的办法就是使用延迟初始化:
#![allow(unused)]
fn main() {
let file;
let writer = {
println!("opening file...");
let filename = "hello.txt";
file = File::create(filename).unwrap();
Writer::new(&file)
};
}但这会使file回到作用域中, 而这正是我们想要避免的.
虽然可以说把let file放在作用域外部并不是什么大问题, 但对于大多数Rust程序员来说, 这种变通方法并不明显.延迟初始化并不是一个常用的功能, 编译器目前在给出临时生命周期错误时也不会建议采用这种变通方法. 即使编译器可以这样做, 这也不是一个小改动.
如果能以某种方式解决这个问题就好了
Macros宏
如果有一个函数既能创建文件, 又能返回一个 Writer 文件, 可能会很有用.比如
#![allow(unused)]
fn main() {
let writer = Writer::new_file("hello.txt");
}但是, 由于 Writer 只借用file, 这就要求 new_file 将File存储在某个地方.它可以leak这个File或以某种方式将其存储在static中, 但(目前)它没有办法让file与返回的 Writer 一样长存.
因此, 我们可以使用宏来定义文件和写入器, 无论它在哪里被调用:
#![allow(unused)]
fn main() {
macro_rules! let_writer_to_file {
($writer:ident, $filename:expr) => {
let file = std::fs::File::create($filename).unwrap();
let $writer = Writer::new(&file);
};
}
}使用方法如下:
#![allow(unused)]
fn main() {
let_writer_to_file!(writer, "hello.txt");
writer.something();
}由于宏的卫生性, 在此范围内无法访问file.
这样做是可行的, 但如果它看起来更像一个普通的函数调用, 不是更好吗?
#![allow(unused)]
fn main() {
et writer = writer_to_file!("hello.txt");
writer.something();
}正如我们之前所见, 在 let writer = ...;语句中创建一个存活时间足够长的临时File的方法是使用临时生命周期扩展:
#![allow(unused)]
fn main() {
macro_rules! writer_to_file {
($filename:expr) => {
Writer { file: &File::create($filename).unwrap() }
};
}
let writer = writer_to_file!("hello.txt");
}这将扩展成:
#![allow(unused)]
fn main() {
let writer = Writer { file: &File::create("hello.txt").unwrap() };
}这将在必要时延长临时File的生命周期.
但如果file不是公开, 我们就不能这样做, 而需要使用 Writer::new() 代替.宏需要在调用它的 let writer = ...;语句之前插入 let file;.这是不可能的.
format_args!()
这个问题也是(现在)format_args!() 的结果不能存储在 let 语句中的原因:
#![allow(unused)]
fn main() {
let f = format_args!("{}", 1); // Error!
something.write_fmt(f);
}原因是 format_args!() 会扩展为类似 fmt::Arguments::new(&Argument::display(&arg), ...) 的内容, 其中一些参数是对临时变量的引用.
临时生命周期扩展不适用于函数调用的参数, 因此 fmt::Arguments 对象只能在同一语句中使用.
pin!()
另一种经常通过宏创建的类型是 Pin.粗略地说, 它表示对某个永远不会移动的东西的引用.(具体细节很复杂, 但现在不是很重要).
它是通过一个名为 Pin::new_unchecked 的unsafe函数创建的, 因为我们需要保证它所引用的值即使在 Pin 本身消失后也不会被移动.
使用该函数的最佳方法是使用shadowing:
#![allow(unused)]
fn main() {
let mut thing = Thing { … };
let thing = unsafe { Pin::new_unchecked(&mut thing) };
}因为第二个thing会对第一个thing产生shadow, 所以第一个thing(仍然存在)不能再被命名.因为它不能被命名, 所以我们可以确定它不能被移动(即使在放弃第二个thing后), 这正是我们在unsafe块中所承诺的.
因为这是一种常见的模式, 所以通常用宏来捕获这种模式.
例如, 我们可以定义一个 let_pin 宏如下:
#![allow(unused)]
fn main() {
macro_rules! let_pin {
($name:ident, $init:expr) => {
let mut $name = $init;
let $name = unsafe { Pin::new_unchecked(&mut $name) };
};
}
}使用方法与之前的 let_writer_to_file 宏类似:
#![allow(unused)]
fn main() {
let_pin!(thing, Thing { … });
thing.something();
}这样做可以很好地封装和隐藏不安全代码.
但是, 就像我们的 Writer 示例一样, 如果它能像下面这样工作, 不是更好吗?
#![allow(unused)]
fn main() {
let thing = pin!(Thing { … });
}我们都知道, 要做到这一点, 我们必须利用临时生命周期扩展功能, 使Thing的生命周期足够长.而要做到这一点, 我们必须使用 Pin {} 语法来构造 Pin:Pin { pinned: &mut Thing { ... }} 会调用临时生命周期扩展, 但 Pin::new_unchecked(&mut Thing { ... }) 不会.
这就意味着要将 Pin 的字段公开, 这就违背了 Pin 的初衷.只有在字段是私有的情况下, 它才能提供有意义的保证.
这意味着, 不幸的是, (如今)不可能自己编写这样一个 pin!() 宏.
标准库还是这么做了, 犯了一个可怕的罪行:Pin 的 “私有 “字段实际上被定义为 pub, 但也被标记为 “不稳定”, 如果你试图使用它, 编译器就会抱怨.
如果不需要这种黑客手段就好了.
super let
用户体验和诊断
可能的扩展
未来可能的扩展是允许在函数作用域中使用super let. 也就是说, “super“指的是函数的调用者.
正如@lorepozo@tech.lgbt在Mastodon上提到的, 这将使 pin!() 成为一个函数而不是宏. 同样, 它也能让 Writer::new_file(...) 成为可能, 而不必使用宏.
这样做的有效方式是允许某些函数将对象放入调用者的堆栈框架中, 然后可以从返回值中引用这些对象. 这在任何普通的旧函数中都是行不通的;通常情况下, 调用者不会为函数预留放置对象的空间. 这需要成为函数签名的一部分.
也许可以这样?
#![allow(unused)]
fn main() {
pub placing fn new_file(filename: &str) -> Writer {
super let mut file = File::create(filename).unwrap(); // Placed into caller's stack frame
Writer::new(&file) // So we can borrow it in the return value!
}
}这不是我现在提出的建议的一部分, 但想想也很有趣. )
临时生命周期 2024 RFC
几个月前, 我与Niko Matsakis和Ding Xiang Fei分享了我的想法–super let.他们一直在努力制定super let的确切定义和详细规则, 以及下一版Rust的临时生命周期的一些新规则.
这项名为 “temporary lifetimes 2024” effort的联合工作正在促成一项RFC, 该RFC主要建议尽可能减少临时生命周期, 以防止 if let 或匹配中的临时 MutexGuard 导致的死锁, 并添加 super let 作为选择更长生命周期的一种方式.
反馈
你是否有意识地使用过临时延长寿命的方法?或者你被它咬过吗?
你怎么看super let?你会使用它吗?或者你有更好的主意?
请在下面的评论或 GitHub 上告诉我, 或加入 Reddit``、Twitter 或 Mastodon 上的讨论.
引用
宏系统
声明宏
过程宏
| 类别 | 形式 | 函数名称 | 函数签名 |
|---|---|---|---|
| 函数式 | #[paoc_macro] | 函数名即宏名 | (TokenStream) -> TokenStream |
| 属性式 | #[proc_macro_attribute] | 函数名即宏名 | (TokenStream, TokenStream) -> TokenStream |
derive式 | #[proc_macro_derive(Name)]或者#[proc_macro_derive(Name, attributes(attr))] | 任意,因为宏名是Name | (TokenStream) -> TokenStream |
proc-macro crate
定义一个过程宏crate的方式是将在crate type设为proc-macro.
当使用Cargo时, 过程宏crate是将Cargo.toml中的lib.proc-macro设为true值.
[lib]
proc-macro = true
它只能导出过程宏, 正常的函数、类型、模块、macro_rules! 等内容都不能导出, 但可以仅在其内部定义和使用.
函数式过程宏
类型函数的过程宏, 像声明宏那样被调用, 即makro!(...). 它是唯一一个在单独看调用形式时, 无法与声明宏区分开的宏.
函数式过程宏的简单编写框架如下所示:
#![allow(unused)]
fn main() {
use proc_macro::TokenStream;
#[proc_macro]
pub fn fn_name_macro(input: TokenStream) -> TokenStream {
input
}
}可以看到, 这实际上只是从一个TokenStream到另一个TokenStream的映射, 其中 input 是调用分隔符内的标记.
属性式过程宏
属性式过程宏定义了可添加到条目的的新外部属性.这种宏通过 #[attr] 或 #[attr(…)] 方式调用, 其中 … 是任意标记树.
属性式过程宏的简单框架如下所示:
#![allow(unused)]
fn main() {
use proc_macro::TokenStream;
#[proc_macro_attribute]
pub fn attribute_name_macro(input: TokenStream, annotated_item: TokenStream) -> TokenStream {
annotated_item
}
}需要注意的是, 与其它两个过程宏不同, 这种宏有两个输入参数.
- 第一个参数是属性名称后面的带分隔符的标记树, 不包括它周围的分隔符.如果只有属性名称(其后不带标记树, 比如
#[attr]), 则这个参数的值为空. - 第二个参数是添加了该过程宏属性的条目, 但不包括该过程宏所定义的属性.因为这是一个
active属性, 在传递给过程宏之前, 该属性将从条目中剥离出来.
derive式过程宏
derive式过程宏为derive属性定义了新的输入.这种宏通过将其名称提供给derive属性的输入来调用, 例如 #[derive(derive_name)].
derive式过程宏的简单框架如下所示:
#![allow(unused)]
fn main() {
use proc_macro::TokenStream;
#[proc_macro_derive(derive_name)]
pub fn derive_name_macro(input: TokenStream) -> TokenStream {
TokenStream::new()
}
}proc_macro_derive稍微特殊一些, 因为它需要一个额外的标识符, 此标识符将成为 derive 宏的实际名称.
输入标记流是添加了 derive 属性的条目, 也就是说, 它将始终是 enum、struct 或者 union 类型, 因为这些是 derive 属性仅可以添加上去的条目.
输出的标记流将被追加到带注释的条目所处的块或模块, 所以要求标记流由一组有效条目组成.
属性宏与
derive宏的显著区别在于, 属性宏生成的标记是完全替换性质, 而derive宏生成的标记是追加性质.
derive式过程宏的辅助属性
derive 宏又有一点特殊, 因为它可以添加仅在条目定义范围内可见的附加属性.
这些属性被称为派生宏辅助属性(derive macro helper attributes), 并且是惰性的(inert).
辅助属性的目的是在每个结构体字段或枚举体成员的基础上为 derive 宏提供额外的可定制性.
辅助属性的定义方式是向 proc_macro_derive 属性增加 attributes(helper0, helper1, ..) 参数, 该参数可包含用逗号分隔的标识符列表(即辅助属性的名称).
编写带辅助属性的`derive``宏的简单框架如下所示:
#![allow(unused)]
fn main() {
use proc_macro::TokenStream;
#[proc_macro_derive(derive_name, attributes(helper0, helper1, ...))]
pub fn derive_name_macro(input: TokenStream) -> TokenStream {
TokenStream::new()
}
}这就是辅助属性的全部内容.在过程宏中使用(或者说消耗)辅助属性, 得检查字段和成员的属性, 来判断它们是否具有相应的辅助属性 如果条目使用了所有 derive 宏都未定义的辅助属性, 那么会出现错误, 因为编译器会尝试将这个辅助属性解析为普通属性(而且这个属性并不存在).
Reference
rust交叉编译
toolchain和target分别是, toolchain是交叉编译所需的“编译工具”, 而target则是编译到目标平台所需的“库文件“
什么是 Toolchain
toolchain 指一组Rust工具, 包括编译器(rustc), 构建工具(cargo), 文档生成工具(rustdoc)以及其他与 Rust 相关的实用程序. Toolchain用于管理和构建 Rust 代码, 并且可以包括一个特定版本的 Rust 编译器和标准库, 还包含一个默认是编译到本机平台的target. 工具链的版本可以是 “stable”(稳定版), “beta”(测试版)或 “nightly”(每日构建版), 每个版本都对应着不同的 Rust 编译器和特性. 工具链中的工具命令了, 它们通常存储在~/.cargo/bin这个目录下.
什么是 Rustc target
Rust 中的target概念主要是为了支持跨平台开发和交叉编译, 以确保 Rust 代码可以在不同的操作系统和架构上正确运行. Rustc target指的是编译和构建目标平台Rust代码时需要的组件. 不要混淆为Rust项目编译后产生的target文件夹. 它的格式表示为: <arch>-<vendor>-<os>-<abi>. 其中:
<arch>表示架构(例如, x86_64 表示64位的x86架构).<vendor>表示供应商(一般为空).<os>表示操作系统(例如, linux, windows, macos 等).<abi>表示二进制接口(例如, 默认的是 “gnu”, 也可以是 “musl”, “msvc” 等)
例如:
x86_64-unknown-linux-gnu: 64位 x86 架构, Linux 操作系统, 使用 gnu.x86_64-unknown-linux-musl64位 x86 架构, Linux 操作系统, 使用 musl.i686-pc-windows-msvc: 32位 x86 架构, Windows 操作系统, 使用 MSVC 编译器.
一般来说只需要rustup target add <target>命令安装某个目标平台组件即可, 但对于一些特殊平台, 可能需要手动安装相关的交叉编译工具链, 例如windows msvc或者android NDK.
常用命令:
# 列出可用的target
rustup target list
# 安装一个新的rustup target add <target>
rustup target add x86_64-unknown-linux-gnu
# 把代码编译到指定平台
cargo build --target x86_64-unknown-linux-gnu
Rust编译流程
Source code -> MIR -> LLVM IR -> 机器码 -> Target链接 -> 可执行文件或库
以Linux平台为例, Rust编译器就是rustc
- 首先会把源码编译为
MIR - 然后交给
LLVM处理,LLVM继续把MIR先编译成LLVM IR. - 进而编译为目标平台的机器码(此时还不是执行文件, 只是一堆机器码)
- 往后就是
target发挥作用了,target调用msvc或gnu来完成链接步骤, 主要是链接目标平台库文件并生成可执行文件.
这里整个编译过程几乎都是由rustc完成的, 因为它包含了llvm和调用target的代码, 跟目标平台相关的工作则是由msvc或gnu来完成. msvc和gnu是c/c++的编译工具链, 编译后的最终产物就是可执行文件或库, rustc在编译后期用到了它们提供的功能.
交叉编译
Ubuntu默认的target是gnu的, 依赖glibc, 但是其他Linux系统未必是glibc是基础库, 但是可以用同一套toolchain(编译器之类的), 因此只需要添加target即可.
而交叉编译到Windows, 则Linux的编译器是没有这个能力的, 因此需要添加Windows平台的toolchain(有部分toolchain官方没有实现还得添加第三方的toolchain), 然后再添加target.
注意, 如果Windows选择的是msvc而非gnu, 那么哪怕是最简单的hello world也必须要安装visual studio(主要是需要它携带的toolchain[linker等])
References
Golang
Golang AST
1. Token
Token是编程语言中最小的具有独立含义的词法单元.
Token不仅仅包含关键字,还包含用户自定义的标识符、运算符、分隔符和注释等.
每个Token对应的词法单元有三个属性是比较重要的:
- Token本身的值表示词法单元的类型
- Token在源代码中源代码文本形式
- Token出现的位置
- 在所有的Token中,注释和分号是两种比较特殊的Token:
- 普通的注释一般不影响程序的语义,因此很多时候可以忽略注释;
- Go语言中经常在行尾自动添加分号Token,而分号是分隔语句的词法单元,因此自动添加分号导致了Go语言左花括弧不能单独一行等细微的语法差异.
1.1 Token语法
Go语言中主要有标识符、关键字、运算符和分隔符等类型等Token组成.
- 标识符由字母和数字组成,开头第一个字符必须是字母,标识符的语法定义如下:
identifier = letter { letter | unicode_digit } .
letter = unicode_letter | "_" .
- 关键字用于引导特殊的语法结构,不能将关键字作为独立的标识符.下面是Go语言定义的25个关键字:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
- 运算符和分隔符,下面是Go语言定义的47个符号:
+ & += &= && == != ( )
- | -= |= || < <= [ ]
* ^ *= ^= <- > >= { }
/ << /= <<= ++ = := , ;
% >> %= >>= -- ! ... . :
&^ &^=
用户自定义的标识符、25个关键字、47个运算和分隔符号,程序中还有一些面值、注释和空白符组成
1.2 Token定义
在go/token包中,Token被定义为一种枚举值,不同值的Token表示不同类型的词法记号:
// Token is the set of lexical tokens of the Go programming language.
type Token int
// The list of tokens.
const (
// Special tokens
ILLEGAL Token = iota
EOF
COMMENT
literal_beg
// Identifiers and basic type literals
// (these tokens stand for classes of literals)
IDENT // main
INT // 12345
FLOAT // 123.45
IMAG // 123.45i
CHAR // 'a'
STRING // "abc"
literal_end
operator_beg
// Operators and delimiters
ADD // +
SUB // -
MUL // *
QUO // /
REM // %
AND // &
OR // |
XOR // ^
SHL // <<
SHR // >>
AND_NOT // &^
ADD_ASSIGN // +=
SUB_ASSIGN // -=
MUL_ASSIGN // *=
QUO_ASSIGN // /=
REM_ASSIGN // %=
AND_ASSIGN // &=
OR_ASSIGN // |=
XOR_ASSIGN // ^=
SHL_ASSIGN // <<=
SHR_ASSIGN // >>=
AND_NOT_ASSIGN // &^=
LAND // &&
LOR // ||
ARROW // <-
INC // ++
DEC // --
EQL // ==
LSS // <
GTR // >
ASSIGN // =
NOT // !
NEQ // !=
LEQ // <=
GEQ // >=
DEFINE // :=
ELLIPSIS // ...
LPAREN // (
LBRACK // [
LBRACE // {
COMMA // ,
PERIOD // .
RPAREN // )
RBRACK // ]
RBRACE // }
SEMICOLON // ;
COLON // :
operator_end
keyword_beg
// Keywords
BREAK
CASE
CHAN
CONST
CONTINUE
DEFAULT
DEFER
ELSE
FALLTHROUGH
FOR
FUNC
GO
GOTO
IF
IMPORT
INTERFACE
MAP
PACKAGE
RANGE
RETURN
SELECT
STRUCT
SWITCH
TYPE
VAR
keyword_end
)
所有的Token被分为四类:特殊类型、基础面值、运算符(分隔符)和关键字.

- 特殊类型的Token.
有错误、文件结束和注释三种,遇到不能识别的Token统一返回ILLEGAL,这样可以简化词法分析时的错误处理.
- 基础面值对应的Token
Go语言规范定义的基础面值主要有整数、浮点数和复数面值类型,此外还有字符和字符串面值类型.
需要注意的是,在Go语言规范中布尔类型的true和false并不在基础面值之类.但是为了方便词法解析,go/token包将true和false等对应的标识符也作为面值Token一类.其中literal_beg和literal_end是私有的类型,主要用于表示面值类型Token的值域范围
- **运算符(分隔符)**Token
运算符主要有普通的加减乘除等算术运算符号,此外还有逻辑运算、位运算符和比较运算等二元运算(其中二元运算还和赋值运算再次组合).
除了二元运算之外,还有少量的一元运算符号:比如正负号、取地址符号、管道的读取等.而分隔符主要是小括弧、中括弧、大括弧,以及逗号、点号、分号和冒号组成.
- 关键字Token
从词法分析角度看,关键字和普通的标识符并无差别.但是25个关键字一般都是不同语法结构的开头Token,通过将这些特殊的Token定义为关键字可以简化语法解析的工作
1.3 FileSet和File
go/token包还定义了FileSet和File对象,用于描述文件集和文件.
FileSet和File对象的对应关系如图所示:

每个
FileSet表示一个文件集合,底层抽象为一个一维数组,而Pos类型表示数组的下标位置.FileSet中的每个File元素对应底层数组的一个区间,不同的File之间没有交集,相邻的File之间可能存在填充空间.
每个File主要由文件名、base和size三个信息组成. 其中base对应File在FileSet中的Pos索引位置,因此base和base+size定义了File在FileSet数组中的开始和结束位置. 在每个File内部可以通过offset定位下标索引,通过offset+File.base可以将File内部的offset转换为Pos位置.因为Pos是FileSet的全局偏移量,反之也可以通过Pos查询对应的File,以及对应File内部的offset.
词法分析的每个Token位置信息就是由Pos定义,通过Pos和对应的FileSet可以轻松查询到对应的File.然后在通过File对应的源文件和offset计算出对应的行号和列号(实现中File只是保存了每行的开始位置,并没有包含原始的源代码数据). Pos底层是int类型,它和指针的语义类似,因此0也类似空指针被定义为NoPos,表示无效的Pos.
1.4 解析Token
Go语言标准库go/scanner包提供了Scanner实现Token扫描,它是在FileSet和File抽象文件集合基础上进行词法分析.
scanner.Scanner的公开接口定义如下
type Scanner struct {
// public state - ok to modify
ErrorCount int // number of errors encountered
// Has unexported fields.
}
func (s *Scanner) Init(file *token.File, src []byte,err ErrorHandler, mode Mode)
func (s *Scanner) Scan() (pos token.Pos, tok token.Token, lit string)
Init方法用于初始化扫描器:file参数表示当前的文件(不包含代码数据)src参数表示要分析的代码err是用户自定义的错误处理函数mode可以控制是否扫描注释部分
Scan方法扫描一个Token,三个返回值分别表示:
pos表示Token的位置tok表示Token值lit表示Token的源代码文本表示
package main
import (
"fmt"
"go/scanner"
"go/token"
)
// 要构造一个最简单的词法扫描器测试程序,首先要构造Init方法第一参数需要的File对象.但是File对象没有公开的构造函数,只能通过FileSet的AddFile方法间接构造File对象.
func main() {
var src = []byte(`println("你好,世界")`)
var fset = token.NewFileSet()
var file = fset.AddFile("hello.go", fset.Base(), len(src))
var s scanner.Scanner
s.Init(file, src, nil, scanner.ScanComments)
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
}
// output:
// hello.go:1:1 IDENT "println"
// hello.go:1:8 ( ""
// hello.go:1:9 STRING "\"你好,世界\""
// hello.go:1:26 ) ""
// hello.go:1:27 ; "\n"
1.5 Position位置信息
go/token包的Position表示更详细的位置信息,被定义为一个结构体:
type Position struct {
Filename string // filename, if any
Offset int // offset, starting at 0
Line int // line number, starting at 1
Column int // column number, starting at 1 (byte count)
}
Filename表示文件名Offset对应文件内的字节偏移量(从0开始)Line和Column对应行列号(从1开始).比较特殊的是Offset成员,它用于从文件数据定位代码,但是输出时会将偏移量转换为行列号输出.
打印位置信息时,根据文件名、行号和列号有6种组合:
func main() {
a := token.Position{Filename: "hello.go", Line: 1, Column: 2}
b := token.Position{Filename: "hello.go", Line: 1}
c := token.Position{Filename: "hello.go"}
d := token.Position{Line: 1, Column: 2}
e := token.Position{Line: 1}
f := token.Position{Column: 2}
fmt.Println(a.String())
fmt.Println(b.String())
fmt.Println(c.String())
fmt.Println(d.String())
fmt.Println(e.String())
fmt.Println(f.String())
}
// output:
// hello.go:1:2
// hello.go:1
// hello.go
// 1:2
// 1
// -
2. 基础面值
面值是在程序代码中直接表示的值,其它的非零初始值只能由面值常量或常量表达式生成.
比如表达式x+2*y的2就是面值,而x和y则不是面值而是标识符.
2.1 基础面值定义
Go语言规范明确定义了基础面值只有整数、浮点数、复数、符文和字符串几种类型.
需要特别注意的是布尔类型的true和false并不是普通的面值,而是内置的布尔类型标识符(可能被重新定义为其它变量).
在go/token包中,基础面值也被定义为独立的Token:
literal_beg
// Identifiers and basic type literals
// (these tokens stand for classes of literals)
IDENT // main
INT // 12345
FLOAT // 123.45
IMAG // 123.45i
CHAR // 'a'
STRING // "abc"
literal_end
在go/ast分别用两个结构体进行表示基础面值和标识符:
// 基础面值
type BasicLit struct {
ValuePos token.Pos // literal position
Kind token.Token // token.INT, token.FLOAT, token.IMAG, token.CHAR, or token.STRING
Value string // literal string; e.g. 42, 0x7f, 3.14, 1e-9, 2.4i, 'a', '\x7f', "foo" or `\m\n\o`
}
// 标识符
type Ident struct {
NamePos token.Pos // identifier position
Name string // identifier name
Obj *Object // denoted object; or nil
}
整数型面值定义如下:
// 整数型面值分为十进制面值、二进制面值、八进制面值和十六进制面值四种形式. int_lit = decimal_lit | binary_lit | octal_lit | hex_lit . decimal_lit = “0” | ( “1” … “9” ) [ [ “” ] decimal_digits ] . binary_lit = “0” ( “b” | “B” ) [ “” ] binary_digits . octal_lit = “0” [ “o” | “O” ] [ “” ] octal_digits . hex_lit = “0” ( “x” | “X” ) [ “” ] hex_digits .
需要注意的是整数型面值并不支持科学计数法形式,同时数字中间可以添加下划线分隔数字.
浮点数面值定义如下:
// 浮点数面值又分为十进制浮点数和十六进制浮点数. float_lit = decimal_float_lit | hex_float_lit .
// 十进制浮点数 decimal_float_lit = decimal_digits “.” [ decimal_digits ] [ decimal_exponent ] | decimal_digits decimal_exponent | “.” decimal_digits [ decimal_exponent ] . decimal_exponent = ( “e” | “E” ) [ “+” | “-” ] decimal_digits .
// 十六进制浮点数 hex_float_lit = “0” ( “x” | “X” ) hex_mantissa hex_exponent . hex_mantissa = [ “” ] hex_digits “.” [ hex_digits ] | [ “” ] hex_digits | “.” hex_digits . hex_exponent = ( “p” | “P” ) [ “+” | “-” ] decimal_digits .
复数面值定义如下:
imaginary_lit = (decimal_digits | int_lit | float_lit) “i” .
符文面值和字符串面值定义如下:
// 符文面值是一个只有一个字符的字符串,由一对单引号包含. rune_lit = “‘” ( unicode_value | byte_value ) “’” . unicode_value = unicode_char | little_u_value | big_u_value | escaped_char . byte_value = octal_byte_value | hex_byte_value .
// 字符串由一对双引号或反引号表示,其中可以包含多个字符,但是不能跨行. string_lit = raw_string_lit | interpreted_string_lit . raw_string_lit = “
" { unicode_char | newline } "” . interpreted_string_lit ="{ unicode_value | byte_value }"
- 普通的符文和字符串都可以通过转义字符包含特殊的符号,它们是通过一个特殊的
\斜杠开始.- 反引号表示的字符串表示原生字符串,原生字符串可以跨域多行但是不支持转义字符,因此其内部是无法表示反引号这个字符的.
2.2 基础面值语法树
go/ast包定义了基础面值结构体:
type BasicLit struct {
ValuePos token.Pos // literal position
Kind token.Token // token.INT, token.FLOAT, token.IMAG, token.CHAR, or token.STRING
Value string // literal string; e.g. 42, 0x7f, 3.14, 1e-9, 2.4i, 'a', '\x7f', "foo" or `\m\n\o`
}
ValuePos成员表示该词法元素开始的字节偏移量(并不包含文件名、行号和列号等信息)Kind表示面值的类型(只有数值类型、字符和字符串三类)Value是表示面值的原始代码
2.2.1构造基础面值
package main
import (
"go/ast"
"go/token"
)
func main() {
var lit9527 = &ast.BasicLit{
Kind: token.INT,
Value: "9527",
}
ast.Print(nil, lit9527)
}
// output:
// 0 *ast.BasicLit {
// 1 ValuePos: 1
// 2 Kind: INT
// 3 Value: "9527"
// 4 }
token.INT表示基础面值的类型是整数,值是整数的十进制字符串表示. 如果把token.INT改为token.FLOAT则变成浮点数的9527, 如果改成token.STRING则会变成“9527”字符串面值.
2.2.2 解析基础面值
func main() {
expr, _ := parser.ParseExpr(`9527`)
ast.Print(nil, expr)
}
// output:
// 0 *ast.BasicLit {
// 1 ValuePos: 1
// 2 Kind: INT
// 3 Value: "9527"
// 4 }
基础面值在语法树中是属于叶子结点的存在,在递归遍历语法树时遇到基础面值结点递归就会返回. 同时,通过基础面值、指针、结构体、数组和map等其它语法结构的相互嵌套和组合就可以构造出无穷无尽的复杂类型来.
2.3 标识符面值
go/ast包定义了标识面值结构体:
type Ident struct {
NamePos token.Pos // identifier position
Name string // identifier name
Obj *Object // denoted object; or nil
}
NamePos表示标识符的位置Name是标识符的名字Obj则表示标识符的类型获取其它的扩展信息.作为内置的标识符面值来说,我们主要关注标识符的名字即可.
2.3.1构造标识符面值
package main
import (
"go/ast"
)
func main() {
ast.Print(nil, ast.NewIdent(`x`))
}
// output:
// 0 *ast.Ident {
// 1 NamePos: 0
// 2 Name: "x"
// 3 }
2.2.2 解析基础面值
func main() {
expr, _ := parser.ParseExpr(`x`)
ast.Print(nil, expr)
}
// 从表达式解析标识符,则会通过Obj成员描述标识符额外的信息.
// output:
// 0 *ast.Ident {
// 1 . NamePos: 1
// 2 . Name: "x"
// 3 . Obj: *ast.Object {
// 4 . . Kind: bad
// 5 . . Name: ""
// 6 . }
// 7 }
ast.Object是一个相对复杂的结构,其中Kind用于描述标识符的类型:
const (
Bad ObjKind = iota // for error handling
Pkg // package
Con // constant
Typ // type
Var // variable
Fun // function or method
Lbl // label
)
Bad表示未知的类型,其它的分别对应Go语言中包、常量、类型、变量、函数和标号等语法结构. 而对于标识符中更具体的类型(比如是整数还是布尔类型)则是由
ast.Object的其它成员描述.
3.基础表达式
基础表达式是指完全由数值型面值和标识符组成的表达式.
3.1 基础表达式语法
基础表达式主要是指由一元和二元运算符组成的表达式,运算的主体是各种面值或标识符.
// Expression表示基础表达式的递归定义,可以是UnaryExpr类型的一元表达式,或者是binary_op生成的二元表达式.
// 基础表达式运算符两边的对象由Operand定义,主要是面值或表达式,也可以是由小括弧包含的表达式。
Expression = UnaryExpr | Expression binary_op Expression .
UnaryExpr = Operand | unary_op UnaryExpr .
Operand = Literal | identifier | "(" Expression ")" .
binary_op = "||" | "&&" | rel_op | add_op | mul_op .
rel_op = "==" | "!=" | "<" | "<=" | ">" | ">=" .
add_op = "+" | "-" | "|" | "^" .
mul_op = "*" | "/" | "%" | "<<" | ">>" | "&" | "&^" .
unary_op = "+" | "-" | "!" | "^" | "*" | "&" | "<-" .
3.2 解析表达式
parser.ParseExpr函数是解析的单个表达式(可以包含注释),因此返回的ast.Expr是一个表达式抽象接口:
type Expr interface {
Node
// contains filtered or unexported methods
}
st.Node接口更简单,只有两个方法表示了这个语法树结点的开始位置和结束位置:
type Node interface {
Pos() token.Pos // position of first character belonging to the node
End() token.Pos // position of first character immediately after the node
}
通过分析go/ast包的文档可以发现很多类型以Expr为后缀名:
$ go doc go/ast | grep Expr
type BadExpr struct{ ... }
type BinaryExpr struct{ ... }
type CallExpr struct{ ... }
type Expr interface{ ... }
type ExprStmt struct{ ... }
type IndexExpr struct{ ... }
type KeyValueExpr struct{ ... }
type ParenExpr struct{ ... }
type SelectorExpr struct{ ... }
type SliceExpr struct{ ... }
type StarExpr struct{ ... }
type TypeAssertExpr struct{ ... }
type UnaryExpr struct{ ... }
ast.BinaryExpr表达的二元算术表达式开始,因为加减乘除四则运算是我们最熟悉的表达式结构:
func main() {
expr, _ := parser.ParseExpr(`1+2*3`)
ast.Print(nil, expr)
}
// output:
// 0 *ast.BinaryExpr {
// 1 . X: *ast.BasicLit {
// 2 . . ValuePos: 1
// 3 . . Kind: INT
// 4 . . Value: "1"
// 5 . }
// 6 . OpPos: 2
// 7 . Op: +
// 8 . Y: *ast.BinaryExpr {
// 9 . . X: *ast.BasicLit {
// 10 . . . ValuePos: 3
// 11 . . . Kind: INT
// 12 . . . Value: "2"
// 13 . . }
// 14 . . OpPos: 4
// 15 . . Op: *
// 16 . . Y: *ast.BasicLit {
// 17 . . . ValuePos: 5
// 18 . . . Kind: INT
// 19 . . . Value: "3"
// 20 . . }
// 21 . }
// 22 }
下图是parser.ParseExpr("1+2*3")返回的树结构:

其中ast.BasicLit是基础面值类型,在前面章节已经讲过。而ast.BinaryExpr是表示二元表达式的结点,其定义如下:
type BinaryExpr struct {
X Expr // left operand
OpPos token.Pos // position of Op
Op token.Token // operator
Y Expr // right operand
}
3.3 求值表达式
在了解了ast.BinaryExpr语法树的结构之后,其实我们就可以手工对表达式求值了:
func main() {
expr, _ := parser.ParseExpr(`1+2*3`)
fmt.Println(Eval(expr))
}
func Eval(exp ast.Expr) float64 {
switch exp := exp.(type) {
case *ast.BinaryExpr:
return EvalBinaryExpr(exp)
case *ast.BasicLit:
f, _ := strconv.ParseFloat(exp.Value, 64)
return f
}
return 0
}
func EvalBinaryExpr(exp *ast.BinaryExpr) float64 {
switch exp.Op {
case token.ADD:
return Eval(exp.X) + Eval(exp.Y)
case token.MUL:
return Eval(exp.X) * Eval(exp.Y)
}
return 0
}
3.4 标识符: 为表达式中引入变量
func main() {
expr, _ := parser.ParseExpr(`1+2*3+x`)
fmt.Println(Eval(expr, map[string]float64{
"x": 100,
}))
}
func Eval(exp ast.Expr, vars map[string]float64) float64 {
switch exp := exp.(type) {
case *ast.BinaryExpr:
return EvalBinaryExpr(exp, vars)
case *ast.BasicLit:
f, _ := strconv.ParseFloat(exp.Value, 64)
return f
case *ast.Ident:
return vars[exp.Name]
}
return 0
}
func EvalBinaryExpr(exp *ast.BinaryExpr, vars map[string]float64) float64 {
switch exp.Op {
case token.ADD:
return Eval(exp.X, vars) + Eval(exp.Y, vars)
case token.MUL:
return Eval(exp.X, vars) * Eval(exp.Y, vars)
}
return 0
}
在Eval函数递归解析时,如果当前解析的表达式语法树结点是*ast.Ident类型,则直接从vars表格查询结果。
不过在Go语言的表达式要复杂很多,不仅仅有普通的局部变量,还有数组索引求值、管道取值、其它结构的成员求值等类型。但是标识符是引入变量最基础的方法,我们可以在此基础方法之上慢慢完善更复杂的求值函数。
4. 代码结构
Go语言的代码结构主要分为三个层面:目录结构、目录内部的包结构、文件内部的代码结构。
标准库的go/parser包只提供了目录和文件解析的函数
资料
0. book
- high-performance-go high performance coding with golang(Go 语言高性能编程,Go 语言陷阱,Gotchas,Traps)
- Go 语言设计与实现 深入理解语言设计以及实现原理
- golang修养之路 本书针对Golang专题性热门技术深入理解,修养在Golang领域深入话题,脱胎换骨
- Go语言实例教程从入门到进阶 Go语言实例教程从入门到进阶,包括基础库使用、设计模式、面试易错点、工具类、对接第三方等
- go-question, book 从问题切入,串连 Go 语言相关的所有知识,融会贯通.
quiz basic
1. defer 和 panic
问题: 代码输出什么?
package main
import "fmt"
// `defer` 和 `panic`
func main() {
defer_call()
}
func defer_call() {
defer func() { fmt.Println("打印前") }()
defer func() { fmt.Println("打印中") }()
defer func() { fmt.Println("打印后") }()
panic("触发异常")
}
解答:
打印后
打印中
打印前
panic: 触发异常
解析:
defer的执行顺序是先进后出,后进先出的顺序执行. 出现panic语句的时候,会先按照defer的后进先出顺序执行,最后才会执行panic.
2. array和slice
问题: 以下代码只注释掉 ② 输出什么?如果只注释 ① 又输出什么?
package main
import "fmt"
func main() {
a := [2]int{5, 6}
b := [2]int{5, 6}
// ①
if a == b {
fmt.Println("equal")
} else {
fmt.Println("not equal")
}
// ②
// if a[:] == b[:] {
// fmt.Println("equal")
// } else {
// fmt.Println("not equal")
// }
}
解答:
array是可以比较的,slice是不可以比较的.
所以:
①为equal
②为编译不通过
解析:
array是可以比较的,必须要求一样数组大小才可以比较,且len和cap是一样的.slice不可直接比较,只可以与nil比较.
3. nil的chan
问题: 代码输出什么?
package main
func main() {
var ch chan int
select {
case v, ok := <-ch:
println(v, ok)
default:
println("default")
}
}
解答:
输出:
default
解析:
一个nil的chan是永远不会被select到,
一个nil的chan发送和接收会永远的阻塞
关闭的chan永远能select到
4. 传值共享slice
问题: 代码输出什么?
package main
import "fmt"
type T struct {
ls []int
}
func foo(t T) {
t.ls[0] = 100
}
func main() {
var t = T{
ls: []int{1, 2, 3},
}
foo(t)
fmt.Println(t.ls[0])
}
- A. 1
- B. 100
- C. compilation error
解答: 输出B
解析:
调用
foo()函数时虽然是传值,但foo()函数中,字段ls依旧可以看成是指向底层数组的指针。
5. 不可寻址的临时变量
问题: 代码输出什么?
package main
type X struct{}
func (x *X) test() {
println(x)
}
func main() {
var a *X
a.test()
// X{}.test()
}
解答:
但是nil是可以调用方法的
X{} 是不可寻址的,不能直接调用方法
解析:
在方法中,指针类型的接收者必须是合法指针(包括 nil),或能获取实例地址。
6. 切片截取问题
问题: 代码输出什么?
package main
import "fmt"
func main() {
s := make([]int, 3, 9)
fmt.Println(len(s))
s2 := s[4:8]
fmt.Println(len(s2))
}
解答:
3
4
解析:
从一个基础切片派生出的子切片的长度可能大于基础切片的长度。
假设基础切片是 baseSlice,使用操作符 [low,high],有如下规则:0 <= low <= high <= cap(baseSlice),
只要上述满足这个关系,下标 low 和 high 都可以大于 len(baseSlice)。
7. 方法值传递
问题: 代码输出什么?
package main
import "fmt"
type N int
func (n N) test() {
fmt.Println(n)
}
func main() {
var n N = 10
p := &n
n++
f1 := n.test
n++
f2 := p.test
n++
fmt.Println(n)
f1()
f2()
}
解答:
13
11
12
解析:
知识点:方法值。
当指针值赋值给变量或者作为函数参数传递时,会立即计算并复制该方法执行所需的接收者对象,与其绑定,以便在稍后执行时,能隐式第传入接收者参数。
8. 方法指针传递
问题: 代码输出什么?
package main
import "fmt"
type N int
func (n *N) test() {
fmt.Println(*n)
}
func main() {
var n N = 10
n++
f1 := n.test
n++
f2 := n.test
n++
fmt.Println(n)
f1()
f2()
}
解答:
13
13
13
解析:
传入的为指针,所以值为最后的结果值
9. 切片截取问题
问题: 代码输出什么?
package main
func main() {
x := make([]int, 2, 10)
_ = x[6:10]
_ = x[2:]
_ = x[6:]
}
解答:
_ = x[6:] 将panic
解析:
_ = x[6:] 在截取符号 [i:j],如果 j 省略,默认是原切片或者数组的长度,即len(x),x 的长度是 2,小于起始下标 6 ,所以 panic。
10. 空struct内存对齐
问题: 代码输出什么?
package main
import (
"fmt"
"unsafe"
)
type demo0 struct {
b int32
c int32
a struct{}
}
type demo1 struct {
a struct{}
b int32
c int32
}
type demo2 struct {
b int32
a struct{}
c int32
}
func main() {
fmt.Println(unsafe.Sizeof(demo0{}), unsafe.Sizeof(demo1{}), unsafe.Sizeof(demo2{}))
}
解答:
12 8 8
解析:
空
struct{}大小为 0,作为其他 struct 的字段时,一般不需要内存对齐。
但是有一种情况除外:即当struct{}作为结构体最后一个字段时,需要内存对齐。 因为如果有指针指向该字段, 返回的地址将在结构体之外,如果此指针一直存活不释放对应的内存,就会有内存泄露的问题(该内存不因结构体释放而释放)。
11. len内置函数
问题: 代码输出什么?
package main
const s = "Go101.org"
// len(s) == 9
// 1 << 9 == 512
// 512 / 128 == 4
var a byte = 1 << len(s) / 128
var b byte = 1 << len(s[:]) / 128
func main() {
println(a, b)
}
解答:
4 0
解析:
a. 常量与求值
当参数是字符串字面量和简单 array 表达式,len 函数返回值是常量.内置函数 len 和 cap 获取各种类型的实参并返回一个 int 类型结果。实现会保证结果总是一个 int 值。
- 如果 s 是一个字符串常量,那么 len(s) 是一个常量 。
- 如果 s 类型是一个数组或到数组的指针且表达式 s 不包含 信道接收 或(非常量的) 函数调用的话, 那么表达式 len(s) 和 cap(s) 是常量;这种情况下, s 是不求值的。
- 否则的话, len 和 cap 的调用结果不是常量且 s 会被求值 所以
len(s)与len(s[:])前者返回是常量,后者是求值的值b. 位移
在位移表达式的右侧的操作数必须为整数类型,或者可以被 uint 类型的值所表示的无类型的常量。
如果一个
非常量位移表达式的左侧的操作数是一个无类型常量,那么它会先被隐式地转换为假如位移表达式被其左侧操作数单独替换后的类型。如果**
常量位移表达式 的左侧的操作数是一个无类型常量**,那么其结果是一个整数常量;否则就是和左侧操作数同一类型的常量因此对于
var a byte = 1 << len(s) / 128,因为1 << len(s)是一个常量位移表达式,因此它的结果也是一个整数常量,所以是 512,最后除以 128,最终结果就是 4。而对于
var b byte = 1 << len(s[:]) / 1281,因为1 << len(s[:])是一个非常量位移表达式,而做操作数是 1,一个无类型常量,根据规范定义它是 byte 类型(根据:如果一个非常量位移表达式的左侧的操作数是一个无类号常量,那么它会先被隐式地转换为假如位移表达式被其左侧操作数单独替换后的类型. 即1为byte型,右移溢出,所以为0
12. 补码
问题: 代码输出什么?
原文
package main
func main() {
// // 题1
var a int8 = -1
var b int8 = -128 / a
println(b)
// 题2
// const c int8 = -1
// var d int8 = -128 / c
// println(d)
}
解答:
题1: -128
题2: 编译错误
解析:
const隐式转换不允许溢出,所以编译错误
性能优化pprof
- 值得收藏深度解密系列: Go语言之 pprof
- 实战Go内存泄露
- wolfogre 非常精彩的实战文章
- FlameGraph: Stack trace visualizer
- google pprof
- 如何读懂pprof grap
- pprof暴露的风险
1. shell内置time指令
使用time ./test对执行程序做了性能分析, 得到3个指标.
real: 从程序开始到结束, 实际度过的时间;user: 程序在用户态度过的时间;sys: 程序在内核态度过的时间.
一般情况下 real >= user + sys, 因为系统还有其它进程(切换其他进程中间对于本进程会有空白期).
2 /usr/bin/time指令
这个指令比内置的time更加详细一些, 使用的时候需要用绝对路径, 而且要加上参数
-v
- CPU占用率;
- 内存使用情况;
- Page Fault 情况;
- 进程切换情况;
- 文件系统IO;
- Socket 使用情况
- …
$ /usr/bin/time -v ./test
Command being timed: "./test"
User time (seconds): 0.12
System time (seconds): 0.06
Percent of CPU this job got: 115%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.16
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 41172
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 1
Minor (reclaiming a frame) page faults: 15880
Voluntary context switches: 897
Involuntary context switches: 183
Swaps: 0
File system inputs: 256
File system outputs: 2664
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
3. pprof
pprof 支持四种类型的分析:
CPU:CPU分析, 采样消耗cpu的调用, 这个一般用来定位排查程序里耗费计算资源的地方;Memory: 内存分析, 在应用程序进行堆分配时记录堆栈跟踪, 用于监视当前和历史内存使用情况, 以及检查内存泄漏;Block: 阻塞分析, 记录 goroutine 阻塞等待同步 (包括定时器通道) 的位置Mutex: 互斥锁分析, 采样互斥锁的竞争情况;
明确几个重要的点:
- golang 内存
pprof是采样的, 每512KB采样一次; - golang 的内存采样的是堆栈路径, 而不是类型信息;
- golang 的内存采样入口一定是通过
mProf_Malloc,mProf_Free这两个函数.所以, 如果是 cgo 分配的内存, 那么是没有机会调用到这两个函数的, 所以如果是 cgo 导致的内存问题,go tool pprof是分析不出来的;
3.1. pprof的作用
pprof 是 Go 语言中可视化和分析程序运行性能的工具.
pprof 以 profile.proto 读取分析样本的集合, 并生成报告以可视化并帮助分析数据 (支持文本和图形报告).
profile.proto 是一个 Protocol Buffer v3 的描述文件, 它描述了一组 callstack 和 symbolization 信息, 作用是表示统计分析的一组采样的调用栈, 是很常见的 stacktrace 配置文件格式.
它能提供各种性能数据:
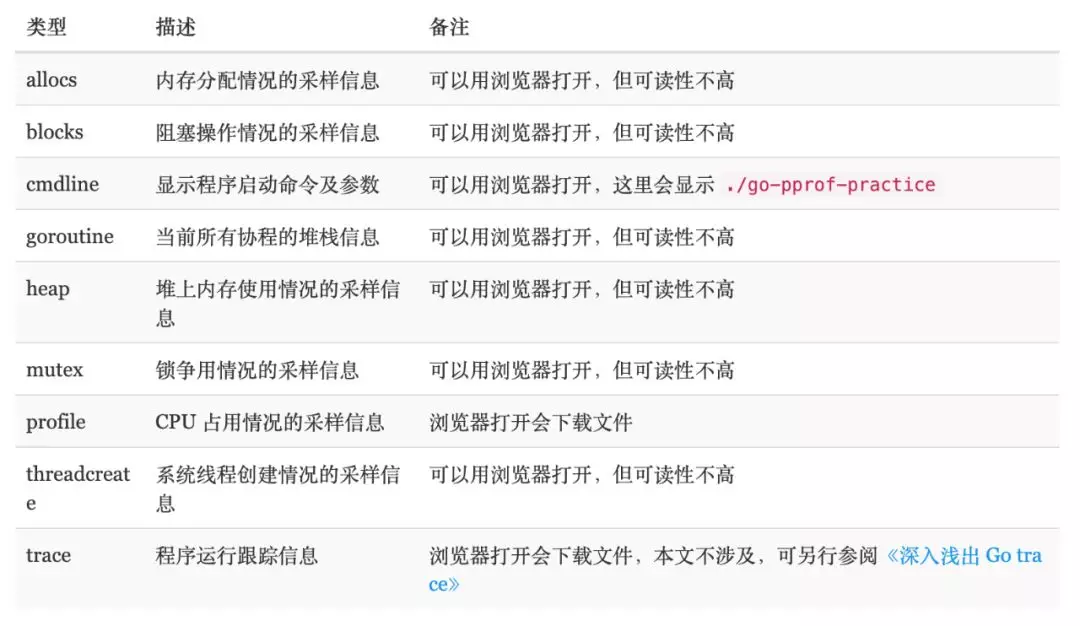
allocs和heap采样的信息一致, 不过前者是所有对象的内存分配, 而heap则是活跃对象的内存分配. 关于 goroutine 的信息有两个链接,
goroutine: 一个汇总的消息, 可以查看 goroutines 的总体情况full goroutine stackdump可以看到每一个 goroutine 的状态.
- CPU Profiling: 当 CPU 性能分析启用后, Go runtime 会每 10ms 就暂停一下, 记录当前运行的 goroutine 的调用堆栈及相关数据.当性能分析数据保存到硬盘后, 我们就可以分析代码中的热点了.
- Memory Profiling: 内存性能分析则是在堆 (Heap) 分配的时候, 记录一下调用堆栈.默认情况下, 是每 1000 次分配, 取样一次, 这个数值可以改变.栈(Stack)分配, 由于会随时释放, 因此不会被内存分析所记录. 由于内存分析是取样方式, 并且也因为其记录的是分配内存, 而不是使用内存. 因此使用内存性能分析工具来准确判断程序具体的内存使用是比较困难的.
- Block Profiling: 阻塞分析是一个很独特的分析, 它有点儿类似于 CPU 性能分析, 但是它所记录的是 goroutine 等待资源所花的时间.阻塞分析对分析程序并发瓶颈非常有帮助, 阻塞性能分析可以显示出什么时候出现了大批的 goroutine 被阻塞了.阻塞性能分析是特殊的分析工具, 在排除 CPU 和内存瓶颈前, 不应该用它来分析.
- Mutex Profiling: 互斥锁分析, 报告互斥锁的竞争情况
3.1.1 如何使用
-
runtime/pprof: 采集程序(非Server)的运行数据进行分析, 主要针对只跑一次的程序, 具体查看runtime/pprof相关api -
net/http/pprof: 采集程序(Server)的运行时数据进行分析, 可提供一个HTTP接口http://localhost:8080/debug/pprof/进入浏览器页面,查看相关的汇总信息
3.1.2 分析
example:
package main
import (
"fmt"
"math/rand"
"net/http"
"os"
"strconv"
"time"
_ "net/http/pprof"
)
func main() {
fmt.Println(os.Getpid())
fmt.Println("http://localhost:8080/debug/pprof")
go func() {
http.ListenAndServe(":8080", nil)
}()
// busy working....
// Force the GC to work to make the plots "move".
m := map[string][]byte{}
for {
b := make([]byte, 512+rand.Intn(16*1024))
m[strconv.Itoa(len(m)%(10*100))] = b
if len(m)%(10*100) == 0 {
m = make(map[string][]byte)
}
time.Sleep(10 * time.Millisecond)
}
}
通过命令交互分析
- 通过得到profile文件直接进入分析
go tool pprof ./profile
- 通过url地址直接进入分析
# 下载 cpu profile, 默认从当前开始收集 30s 的 cpu 使用情况, 需要等待 30s
go tool pprof http://localhost:8080/debug/pprof/profile
# wait 120s
go tool pprof http://localhost:8080/debug/pprof/profile?seconds=120
# 下载 heap profile
go tool pprof http://localhost:8080/debug/pprof/heap
# 切换内存分析的类型
go tool pprof -sample_index=alloc_space http://localhost:8080/debug/pprof/heap
# 下载 goroutine profile
go tool pprof http://localhost:8080/debug/pprof/goroutine
# 下载 block profile
go tool pprof http://localhost:8080/debug/pprof/block
# 下载 mutex profile
go tool pprof http://localhost:8080/debug/pprof/mutex
命令行支持命令:
callgrind:callgrind格式主要用于KCachegrind工具, 可视化分析函数调用和执行情况.comments: 输出所有的profile注释信息, 帮助开发者了解和记录性能分析的元数据.disasm: 输出带有采样注释的汇编代码列表.此功能对于需要深入了解程序在汇编级别的性能表现非常有用.dot: 生成DOT格式的图表. DOT格式是一种图形描述语言, 可以用于Graphviz工具, 进行复杂的图形可视化.eog: 通过eog工具可视化图表.此命令将生成的图表直接在eog中打开.evince: 通过evince工具可视化图表, 与eog类似, 但使用的是Evince文档查看器.gif: 生成GIF格式的图像, 便于在网页和报告中嵌入性能分析图表.gv: 通过gv工具可视化图表. gv是一个基于X11的PostScript和PDF查看器.kcachegrind: 在KCachegrind工具中可视化报告.KCachegrind是一个强大的性能分析工具, 特别适用于处理callgrind格式的文件.list: 输出与正则表达式匹配的函数的注释源代码, 帮助开发者直接在源代码级别查看性能瓶颈.pdf: 生成PDF格式的图表, 便于打印和分享peek: 输出与正则表达式匹配的函数的调用者和被调用者信息png: 生成PNG格式的图像, 与GIF类似, 但适用于需要高质量静态图像的场景.proto: 以压缩protobuf格式输出profile数据.这种格式适用于数据交换和存储.ps: 生成PostScript格式的图表, 便于高质量打印.raw: 输出原始profile数据的文本表示, 用于深入分析或自定义处理.svg: 生成SVG格式的图像, 适用于需要矢量图形的场景, 如网页嵌入和缩放显示tags: 输出profile中的所有标签信息, 帮助开发者了解和筛选性能数据text: 以文本形式输出主要的性能数据条目, 便于快速查看和分析.top: 以文本形式输出性能数据的主要条目, 类似于Linux中的top命令, 帮助开发者快速定位性能热点.topproto: 以压缩protobuf格式输出主要的性能数据条目, 结合了top和proto命令的功能.traces: 以文本形式输出所有的profile样本数据, 适用于详细的逐样本分析.tree: 以文本形式输出调用图, 帮助开发者以树形结构查看函数调用关系.web: 通过默认的网页浏览器可视化图表, 使得性能分析结果更易于共享和展示.weblist: 在网页浏览器中显示带注释的源代码, 与list命令类似, 但提供了更友好的界面.
通过可视化界面(需要graphviz支持)
go tool pprof -http=:8080 cpu.prof
或者
go tool pprof cpu.prof
(pprof) web
相关参数
- profile
flat: 本函数的执行耗时flat%: flat占CPU总时间的比例sum%: 本函数累积使用CPU总比例cum: 本函数加上调用的函数总耗时cum%: cum占CPU总时间的比例
- heap的flat, sum, cum与上面类似, 只不过计算的是内存大小
-inuse_space: 分析应用程序的常驻内存占用情况-alloc_objects: 分析应用程序的内存临时分配情况
在 cpu profile 中, 一个是方法运行的时间占比, 一个是它在采样的堆栈中出现的时间占比 (前者是 flat 时间, 后者则是 cum 时间占比); 框越大, 代表耗时越多或是内存分配越多.
解读调用图
- 节点颜色:
- 大的正
cum为红色. - 大的负
cum为绿色, 负值最有可能出现在剖面比较中 cum接近零为灰色
- 大的正
- 节点字体大小:
- 字体大小越大, 表示
flat绝对值越大. - 字体大小越小, 表示
flat绝对值越小.
- 字体大小越大, 表示
- 边权重:
- 边越厚, 表示在该路径上使用的资源越多.
- 边越细, 表示在该路径上使用的资源越少.
- 边颜色:
- 大的正值为红色
- 大的负值为绿色
- 接近于零为灰色
- 虚线边: 删除了两个相连位置之间的一些位置.
- 实线边, 两个相连位置是直接相关.
(inline)边标记: 调用已内联到调用程序中.
3.2 火焰图
可视化界面已经支持火焰图(Flame Graph),位于VIEW/Flame Graph下.更老版本pprof不支持-http参数的,可以下载其它库来支持火焰图github.com/google/pprof或者github.com/uber/go-torch
如何读懂火焰图可看: 阮一峰的如何读懂火焰图
4. 性能分析注意事项
4.1 性能分析必须在一个可重复的、稳定的环境中来进行
-
不要在共享硬件上进行性能分析;
-
不要在性能分析期间, 在同一个机器上去浏览网页
-
机器必须闲置
-
注意省电模式和过热保护, 如果突然进入这些模式, 会导致分析数据严重不准确
-
不要使用虚拟机、共享的云主机, 太多干扰因素, 分析数据会很不一致;
-
关闭电源管理、过热管理;
-
绝不要升级, 以保证测试的一致性, 以及具有可比性
如果承受得起, 购买专用的性能测试分析的硬件设备, 上架
golang跟踪剖析trace
该工具是Go 1.5版本加入的, 通过度量go语言特定事件的运行时, 例如:
- 创建, 启动和终止goroutines
- 阻塞/非阻塞goroutines(syscalls, channels, locks)
- 网络 I/O
- Syscalls
- 垃圾回收
1. Trace概览
package main
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
// create new channel of type int
ch := make(chan int)
// start new anonymous goroutine
go func() {
// send 42 to channel
ch <- 42
}()
// read from channel
<-ch
}
执行go run main.go 2> trace.out 运行这段代码会发送trace数据到trace.out, 之后可以用go tool trace trace.out读取trace.启动一个web,默认是127.0.0.1地址的一个随机端口, 可以修改host进行指定.
2. 选项
-
View trace: 最复杂、最强大和交互式的可视化显示了整个程序执行的时间轴.这个视图显示了在每个虚拟处理器上运行着什么, 以及什么是被阻塞等待运行的.稍后我们将在这篇文章中深入探讨这个视图.注意它只能在chrome上显示.
-
Goroutine analysis: 显示了在整个执行过程中, 每种类型的goroutines是如何创建的.在选择一种类型之后就可以看到关于这种类型的goroutine的信息.例如, 在试图从mutex获取锁、从网络读取、运行等等每个goroutine被阻塞的时间.
-
Network/Sync/Syscall blocking profile: 这些图表显示了goroutines在这些资源上所花费的时间.它们非常接近pprof上的内存/cpu分析.这是分析锁竞争的最佳选择.
-
Scheduler latency profiler: 为调度器级别的信息提供计时功能, 显示调度在哪里最耗费时间.
2.1 View trace
- Timeline: 显示执行的时间, 根据跟踪定位的不同, 时间单位可能会发生变化.你可以通过使用键盘快捷键(WASD键)来导航时间轴.
- Goroutines: 在每个时间点显示有多少goroutines在运行, 有多少是可运行的(等待被调度的).大量可运行的goroutines可能显示调度竞争, 例如, 当程序创建过多的goroutines, 会导致调度程序繁忙.
- Heap: 在执行期间显示内存分配, 这对于发现内存泄漏非常有用, 并检查垃圾回收在每次运行时能够释放多少内存.
- OS Threads: 显示有多少OS线程正在被使用, 有多少个被syscalls阻塞.
- Virtual Processors
每个虚拟处理器显示一行.虚拟处理器的数量由GOMAXPROCS环境变量控制(默认为内核数). - Goroutines and events
显示在每个虚拟处理器上有什么goroutine在运行.连接goroutines的连线代表事件.在示例图片中, 我们可以看到goroutine “G1.runtime.main“衍生出了两个不同的goroutines:G10和G7(前者是负责收集trace数据的goroutine, 后者是我们使用“go“关键字启动的那个).每个处理器的第二行可能显示额外的事件, 比如syscalls和运行时事件.这还包括goroutine代表运行时所做的一些工作(例如辅助垃圾回收).下图显示了当选择一个goroutine时得到的信息.
该信息包含:
- 它的“名称“(Title)
- 何时开始(Start)
- 持续时间(Wall Duration)
- 开始时的栈trace
- 结束时的栈trace
- 该goroutine产生的事件
c++
c++调试技巧-FailureHandler
c++来说, coredump总是无法避免, 如果服务很吃内存, 那么在写core dump的时候, 会占用很大的内存, 导致服务不可用. 所以可以引入FailureHandler机制来快速做一些事件.
FailureHandler机制思想比较简单, 其原理还是信号处理, 通过注册信号回调函数来解决上面问题. 在回调函数中, 我们可以
- 快速dump当前堆栈信息
- 主动发送close包给服务发现, 可保证服务稳定性.
实现
c++调试技巧-Sanitizers
- Sanitizers 目前该功能已合并入LLVM项目.
- LLVM compiler-rt
- AddressSanitizer 用于检测内存使用错误
- ThreadSanitizer 用于检测多线程间的数据竞争和死锁
- MemorySanitizer 用于检测使用未初始化内存的行为
- LeakSanitizer 用于检测内存泄露
mysql读书笔记
一. mysql基本操作
mysql -h $ip -P $port -u $user -p# 登录show processlist;# 查看连接状态show variables like 'transaction_isolation';# 查看所有变量select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60;查找持续时间超过 60s 的事务explain select * from t where between 10000 and 20000 limit 1000;# 解释这条语句执行行为.show index from t;# 显示表t索引alter table t add index idx_name(email);# 增加表t索引analyze table t;# 当索引的统计信息不正确时, 可重建统计索引信息.fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest# 设置innodb_io_capacity 这个参数了, 告诉 InnoDB 你的磁盘能力set log_query_time=0将慢查询日志的阈值设置为 0, 表示这个线程接下来的语句都会被记录入慢查询日志中;
二. mysql是如何执行的
1. MySQL 的逻辑架构图
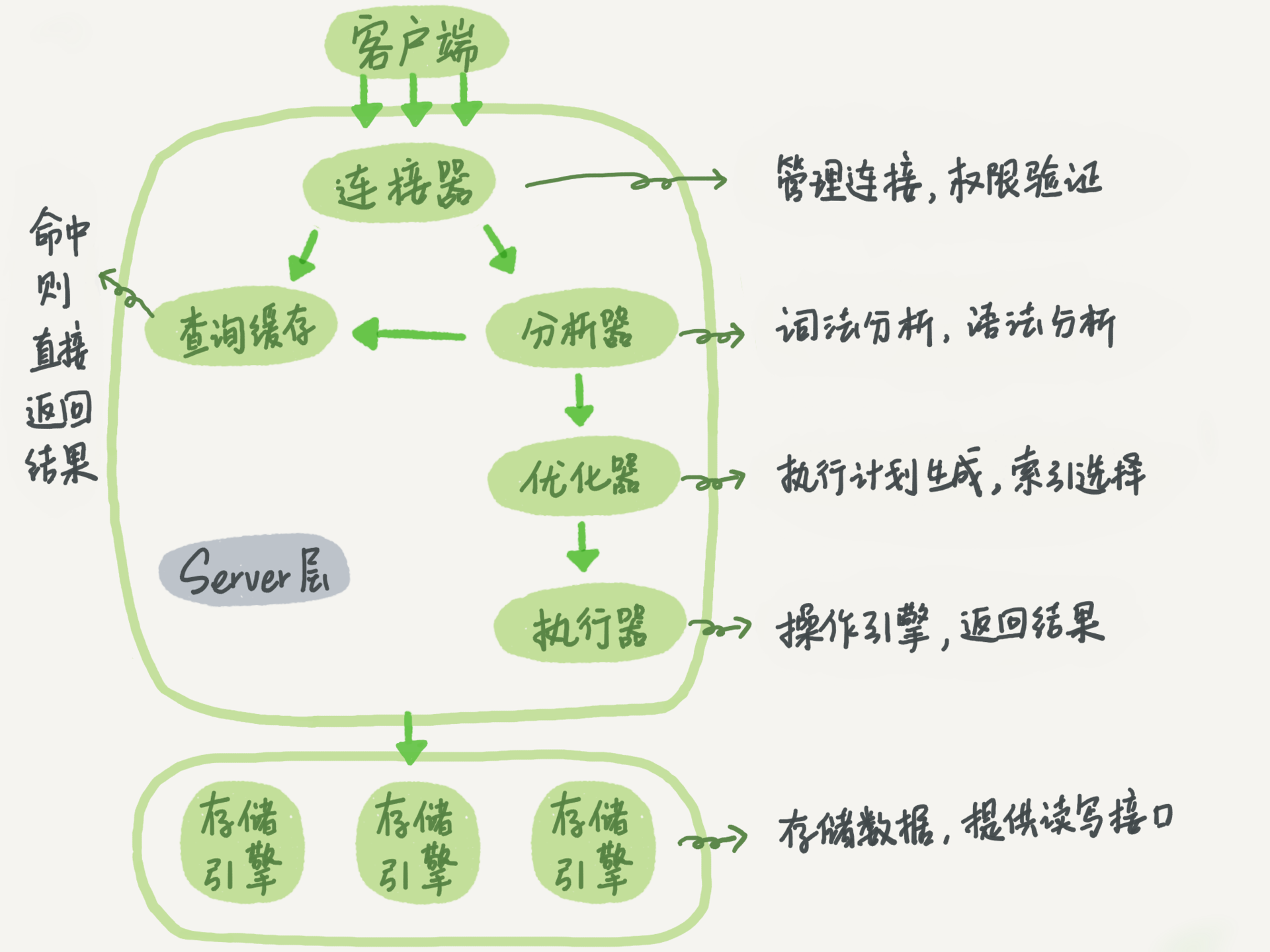
- Server层: 包括连接器、查询缓存、分析器、优化器、执行器等, 涵盖 MySQL 的大多数核心服务功能, 以及所有的内置函数(如日期、时间、数学和加密函数等), 所有跨存储引擎的功能都在这一层实现, 比如存储过程、触发器、视图等
- 存储引擎层: 负责数据的存储和提取。其架构模式是插件式的, 支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB, 它从 MySQL 5.5.5 版本开始成为了默认存储引擎.
大多数情况下我会建议你不要使用查询缓存, 因为查询缓存往往弊大于利 (注意: mysql8.0版本已没有查询缓存功能.)
2. 日志模块
- InnoDB引擎的
redo log: 物理日志,固定大小文件(一组4个文件,每个文件的大小是1GB),循环写的,可配置,当发生日志满时,将发生写盘事件. 保证服务器发生异常重启,还能保证记录不丢失,crash-safe能力 - Server层日志
binlog(归档日志): 逻辑日记,追加写入的.
redo log是 InnoDB 引擎特有的;binlog是 MySQL 的 Server 层实现的, 所有引擎都可以使用。redo log是物理日志, 记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志, 记录的是这个语句的原始逻辑, 比如“给 ID=2 这一行的 c 字段加 1 ”。redo log是循环写的, 空间固定会用完;binlog是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个, 并不会覆盖以前的日志。
日志的配置:
-
innodb_flush_log_at_trx_commit这个参数设置成 1 的时候, 表示每次事务的 redo log 都直接持久化到磁盘 -
sync_binlog这个参数设置成 1 的时候, 表示每次事务的 binlog 都持久化到磁盘
三. 深入索引全局锁表锁行锁
DML: Data Manipulation Language(数据操纵语言) 增删改数据DDL: Data Definition Language(数据定义语言) 加字段等 修改表结构的操作
1. 索引
-
数据库的底层存储的核心是基于数据模型,从理论上分析这个数据库的适用场景,这个数据库.用
N叉树的原因是减少访问磁盘数据块,树中的“N”取决于数据块的大小。 -
每一个索引在
InnoDB里面对应一棵B+树。-
主键索引的叶子节点存的是整行数据。在
InnoDB里, 主键索引也被称为聚簇索引(clustered index)。 -
非主键索引的叶子节点内容是主键的值。在
InnoDB里, 非主键索引也被称为二级索引(secondary index)。基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500, 即主键查询方式, 则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5, 即普通索引查询方式, 则需要先搜索 k 索引树, 得到 ID 的值为 500, 再到 ID 索引树搜索一次。这个过程称为回表。
-
覆盖索引: 索引 k 已经“覆盖了”我们的查询需求, 由于覆盖索引可以减少树的搜索次数, 显著提升查询性能, 所以使用覆盖索引是一个常用的性能优化手段
-
最左前缀原则,不只是索引的全部定义,只要满足最左前缀.
- 第一原则是, 如果通过调整顺序, 可以少维护一个索引, 那么这个顺序往往就是需要优先考虑采用的.(当已经有了 (a,b) 这个联合索引后, 一般就不需要单独在 a 上建立索引了)
- 考虑的原则就是空间.
-
索引下推优化: 可以在索引遍历过程中, 对索引中包含的字段先做判断, 直接过滤掉不满足条件的记录, 减少回表次数。
页分裂: 主要是插入一条新记录时, 所在的页数据已经满了, 需要新申请新的数据页,然后挪动部份数据过去. 不仅影响性能,还影响页的利用率.
页分裂逆过程: 当相邻两个页由于删除了数据, 利用率很低后, 会将数据页做合并.
NOTE: 主键顺序递增能有效的防止页分裂.
-
四. 数据库的锁
1. 全局锁,表锁,行锁
1.1. 全局锁
全局锁就是对整个数据库实例加锁,MySQL 提供了一个加全局读锁的方法, 命令是 Flush tables with read lock (FTWRL),整个库处于只读状态.
全局锁的典型使用场景是, 做全库逻辑备份。也就是把整库每个表都 select 出来存成文本.
官方自带的逻辑备份工具是
mysqldump。当mysqldump使用参数–single-transaction的时候, 导数据之前就会启动一个事务, 来确保拿到一致性视图.**一致性读是好, 但前提是引擎要支持这个隔离级别。**对于 MyISAM 这种不支持事务的引擎, 如果备份过程中有更新, 总是只能取到最新的数据, 那么就破坏了备份的一致性。这时, 我们就需要使用 FTWRL 命令了
–single-transaction 方法只适用于所有的表使用事务引擎的库。
既然要全库只读, 为什么不使用 set global readonly=true 的方式呢?
-
在有些系统中,
readonly的值会被用来做其他逻辑, 比如用来判断一个库是主库还是备库。因此, 修改 global 变量的方式影响面更大, 我不建议你使用. -
在异常处理机制上有差异。
如果执行 FTWRL 命令之后由于客户端发生异常断开, 那么 MySQL 会自动释放这个全局锁, 整个库回到可以正常更新的状态。而将整个库设置为 readonly 之后, 如果客户端发生异常, 则数据库就会一直保持 readonly 状态, 这样会导致整个库长时间处于不可写状态, 风险较高。
1.2. 表级锁
-
表锁: 表锁的语法是
lock tables t read/write。需要注意,lock tables语法除了会限制别的线程的读写外, 也限定了本线程接下来的操作对象.在还没有出现更细粒度的锁的时候, 表锁是最常用的处理并发的方式。
而对于 InnoDB 这种支持行锁的引擎, 一般不使用 lock tables 命令来控制并发, 毕竟锁住整个表的影响面还是太大 如何安全地给小表加字段?
MariaDB已支持mysql未知
ALTER TABLE tbl_name NOWAIT add column ... ALTER TABLE tbl_name WAIT N add column ... -
元数据锁(meta data lock, MDL):
MDL是server层的锁, 表级锁, 主要用于隔离DML和DDL操作之间的干扰MDL的作用是,保证读写的正确性,一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。- 读锁之间不互斥, 因此你可以有多个线程同时对一张表增删改查。
- 读写锁之间、写锁之间是互斥的, 用来保证变更表结构操作的安全性.
MDL会直到事务提交才释放, 在做表结构变更的时候, 你一定要小心不要导致锁住线上查询和更新。
表锁一般是在数据库引擎不支持行锁的时候才会被用到的。如果你发现你的应用程序里有
lock tables这样的语句, 你需要追查一下, 比较可能的情况是:
- 要么是你的系统现在还在用 MyISAM 这类不支持事务的引擎, 那要安排升级换引擎;
- 要么是你的引擎升级了, 但是代码还没升级。我见过这样的情况, 最后业务开发就是把
lock tables和unlock tables改成begin和commit, 问题就解决了
1.3. 行锁
MySQL 的行锁是在引擎层由各个引擎自己实现的。但并不是所有的引擎都支持行锁.比如 MyISAM 引擎就不支持行锁。
- 在 InnoDB 事务中, 行锁是在需要的时候才加上的, 但并不是不需要了就立刻释放, 而是要等到事务结束时才释放。这个就是两阶段锁协议
- 如果你的事务中需要锁多个行, 要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放.
2. 死锁和死锁检测
两种策略:
- 一种策略是, 直接进入等待, 直到超时。这个超时时间可以通过参数
innodb_lock_wait_timeout(默认50s) 来设置。 - 另一种策略是, 主动死锁检测, 发现死锁后, 主动回滚死锁链条中的某一个事务, 让其他事务得以继续执行。将参数
innodb_deadlock_detect(默认on) 设置为on, 表示开启这个逻辑。- 业务避免死锁
- 控制并发度,中间件或修改mysql源码来进行控制并发. 基本思路就是, 对于相同行的更新, 在进入引擎之前排队。这样在 InnoDB 内部就不会有大量的死锁检测工作了
`五. 事务到底是隔离的还是不隔离的
在 MySQL 中, 事务支持是在引擎层实现的.
1. 事务隔离
Atomicity原子性Consistency一致性Isolation隔离性Durability持久性
1.1. 隔离性与隔离级别(ACID)
问题: 当数据库上有多个事务同时执行的时候, 就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read的问题, 为了解决这些问题, 就有了“隔离级别”的概念.
SQL 标准的事务隔离级别包括:读未提交(read uncommitted) 、读提交(read committed)、可重复读(repeatable read)和串行化(serializable)
读未提交: 一个事务还没提交时, 它做的变更就能被别的事务看到.读提交: 一个事务提交之后, 它做的变更才会被其他事务看到.可重复读(mysql默认级别): 一个事务执行过程中看到的数据, 总是跟这个事务在启动时看到的数据是一致的. 当然在可重复读隔离级别下, 未提交变更对其他事务也是不可见的.- 在“可重复读”隔离级别下, 这个视图是在事务启动时创建的, 整个事务存在期间都用这个视图,
- 在“读提交”隔离级别下, 这个视图是在每个 SQL 语句开始执行的时候创建的
串行化: 顾名思义是对于同一行记录, “写”会加“写锁”, “读”会加“读锁”. 当出现读写锁冲突的时候, 后访问的事务必须等前一个事务执行完成, 才能继续执行.

- 若隔离级别是“读未提交”: 则 V1 的值就是 2. 这时候事务 B 虽然还没有提交, 但是结果已经被 A 看到了. 因此, V2、V3 也都是 2.
- 若隔离级别是“读提交”: 则 V1 是 1, V2 的值是 2. 事务 B 的更新在提交后才能被 A 看到. 所以, V3 的值也是 2.
- 若隔离级别是“可重复读”: 则 V1、V2 是 1, V3 是 2. 之所以 V2 还是 1, 遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的. (即视图)
- 若隔离级别是“串行化”: 则在事务 B 执行“将 1 改成 2”的时候, 会被锁住. 直到事务 A 提交后, 事务 B 才可以继续执行. 所以从 A 的角度看, V1、V2 值是 1, V3 的值是 2.
数据库里面会创建一个视图, 访问的时候以视图的逻辑结果为准.
- “读未提交”隔离级别下, 直接返回记录上的最新值, 没有视图概念;
- 在“读提交”隔离级别下, 这个视图是在每个 SQL 语句开始执行的时候创建的.
- 在“可重复读”隔离级别下, 这个视图是在事务启动时创建的, 整个事务存在期间都用这个视图.
- “串行化”隔离级别下直接用加锁的方式来避免并行访问.
# 查看事务的级别
show variables like 'transaction_isolation'
# 查看持续时间超过60s的事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
1.2. 事务的启动方式
- 显式启动事务语句,
begin或start transaction. 配套的提交语句是commit, 回滚语句是rollback.set autocommit=0, 这个命令会将这个线程的自动提交关掉. 意味着如果你只执行一个 select 语句, 这个事务就启动了, 而且并不会自动提交. 这个事务持续存在直到你主动执行commit或rollback语句, 或者断开连接.
1.3 事务启动的时机
begin/start transaction 命令并不是一个事务的起点, 在执行到它们之后的第一个操作 InnoDB 表的语句, 事务才真正启动。如果你想要马上启动一个事务, 可以使用 start transaction with consistent snapshot 这个命令。
在 MySQL 里, 有两个“视图”的概念:
- 一个是 view。它是一个用查询语句定义的虚拟表, 在调用的时候执行查询语句并生成结果。创建视图的语法是 create view … , 而它的查询方法与表一样。
- 另一个是 InnoDB 在实现 MVCC 时用到的一致性读视图, 即 consistent read view, 用于支持 RC(Read Committed, 读提交)和 RR(Repeatable Read, 可重复读)隔离级别的实现。
2. 如何避免长事务对业务的影响?
2.1从应用开发端来看
-
确认是否使用了
set autocommit=0. 这个确认工作可以在测试环境中开展, 把 MySQL 的 general_log 开起来, 然后随便跑一个业务逻辑, 通过 general_log 的日志来确认. 一般框架如果会设置这个值, 也就会提供参数来控制行为, 你的目标就是把它改成 1. -
确认是否有不必要的只读事务. 有些框架会习惯不管什么语句先用 begin/commit 框起来. 我见过有些是业务并没有这个需要, 但是也把好几个 select 语句放到了事务中. 这种只读事务可以去掉.
-
业务连接数据库的时候, 根据业务本身的预估, 通过
SET MAX_EXECUTION_TIME命令, 来控制每个语句执行的最长时间, 避免单个语句意外执行太长时间. (为什么会意外?在后续的文章中会提到这类案例)
2.2 从数据库端来看
- 监控
information_schema.Innodb_trx表, 设置长事务阈值, 超过就报警 / 或者 kill; Percona的 pt-kill 这个工具不错, 推荐使用;- 在业务功能测试阶段要求输出所有的 general_log, 分析日志行为提前发现问题;
- 如果使用的是 MySQL 5.6 或者更新版本, 把
innodb_undo_tablespaces设置成 2(或更大的值). 如果真的出现大事务导致回滚段过大, 这样设置后清理起来更方便.
五. 优化参数
| 参数 | 说明 |
|---|---|
innodb_file_per_table | OFF: 表的数据放在系统共享表空间, 也就是跟数据字典放在一起; ON: 表示的是, 每个 InnoDB 表数据存储在一个以 .ibd 为后缀的文件中. mysql 5.6.6后,该值默认为ON. ON: (建议设置)一个表单独存储为一个文件更容易管理, 而且在你不需要这个表的时候, 通过 drop table 命令, 系统就会直接删除这个文件.而如果是放在共享表空间中, 即使表删掉了, 空间也是不会回收的. 解决方法: 重建表 alter table A engine=InnoDB 推荐github开源项目gh-ost来做 online DDL. |
wait_timeout | 客户端连接超时时间. |
innodb_flush_log_at_trx_commit | 0: 表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ; 1: 表示每次事务的 redo log 都直接持久化到磁盘.(推荐 ) 2: 表示每次事务提交时都只是把 redo log 写到 page cache. |
sync_binlog | 0: 每次提交事务都只 write, 不 fsync; 1: 表示每次事务的 binlog 都持久化到磁盘(推荐) N: 表示每次提交事务都 write, 但累积 N 个事务后才 fsync. 建议100~1000 |
transaction-isolation | 隔离级别 |
autocommit | ON 显示的启动事务,提交和回滚, |
innodb_change_buffer_max_size | 这个参数设置为 50 的时候, 表示 change buffer 的大小最多只能占用 buffer pool 的 50%. |
long_query_time | 慢查询阀值 |
innodb_stats_persistent | 存储索引统计的方式: 设置为 on 的时候, 表示统计信息会持久化存储. 这时, 默认的 N 是 20, M 是 10. 设置为 off 的时候, 表示统计信息只存储在内存中. 这时, 默认的 N 是 8, M 是 16. |
innodb_io_capacity | 告诉 InnoDB 你的磁盘能力,建议你设置成磁盘的 IOPS. 可用此命令查询: fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest |
innodb_max_dirty_pages_pct | 脏页比例上限, 默认值是 75%,通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到. |
innodb_flush_neighbors | 1: 表示有上述的“连坐”机制, 0: 表示不找邻居, 自己刷自己的. |
sort_buffer_size | MySQL 为排序开辟的内存(sort_buffer)的大小 |
sql_log_bin | off: 不写binlog on: 不写binlog |
binlog_group_commit_sync_delay | 表示延迟多少微秒后才调用 fsync; |
binlog_group_commit_sync_no_delay_count | 表示累积多少次以后才调用 fsync. |
-
在 InnoDB 中, 每个数据页的大小默认是16KB.
-
如果内存够, 就要多利用内存, 尽量减少磁盘访问.
-
唯一索引的更新就不能使用
change buffer, 实际上也只有普通索引可以使用-
change buffer用的是buffer pool里的内存, 因此不能无限增大. -
change buffer的大小, 可以通过参数innodb_change_buffer_max_size来动态设置. (这个参数设置为 50 的时候, 表示change buffer的大小最多只能占用buffer pool的50%. )
-
-
优化器逻辑
- 扫描行数是影响执行代价的因素之一. 扫描的行数越少, 意味着访问磁盘数据的次数越少, 消耗的 CPU 资源越少.
- 扫描行数并不是唯一的判断标准, 优化器还会结合是否使用临时表、是否排序等因素进行综合判断.
MySQL 在真正开始执行语句之前, 并不能精确地知道满足这个条件的记录有多少条, 而只能根据统计信息来估算记录数.
这个统计信息就是索引的“区分度”. 显然, 一个索引上不同的值越多, 这个索引的区分度就越好. 而一个索引上不同的值的个数, 我们称之为**“基数”(cardinality)**. 也就是说, 这个基数越大, 索引的区分度越好.
在 MySQL 中, 有两种存储索引统计的方式, 可以通过设置参数
innodb_stats_persistent的值来选择:- 设置为
on的时候, 表示统计信息会持久化存储. 这时, 默认的 N 是 20, M 是 10. - 设置为
off的时候, 表示统计信息只存储在内存中. 这时, 默认的 N 是 8, M 是 16.
-
给字符串加索引
-
完整索引: 这样可能比较占用空间;
alter table SUser add index index1(email); -
前缀索引: 节省空间, 但会增加查询扫描次数, 并且不能使用覆盖索引, 因为必须回表查询确认一次;
前缀索引, 定义好长度, 就可以做到既节省空间, 又不用额外增加太多的查询成本.
alter table SUser add index index2(email(6));select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser; -
倒序存储: 再创建前缀索引, 用于绕过字符串本身前缀的区分度不够的问题;但是不支持范围查询.
-
hash字段: 查询性能稳定, 有额外的存储和计算消耗, 跟第三种方式一样, 都不支持范围扫描.
可以在表上再创建一个整数字段, 来保存身份证的校验码, 同时在这个字段上创建索引.
-
-
刷脏页逻辑, mysql抖动原因.
innodb_io_capacity这个参数了, 它会告诉 InnoDB 你的磁盘能力. 这个值我建议你设置成磁盘的IOPS. 通过fio工具获取磁盘IOPS能力fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytestinnodb_max_dirty_pages_pct是脏页比例上限, 默认值是 75%. InnoDB 会根据当前的脏页比例(假设为 M), 算出一个范围在 0 到 100 之间的数字. 脏页比例获取通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total具体使用select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty';select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total';select @a/@b;innodb_flush_neighbors用来控制刷脏页时是否刷邻居脏页.
-
如何删除数据并缩小表文件.
-
可以使用以下命令要重建表
alter table A engine=InnoDB -- 与下一句相同 alter table t engine=innodb,ALGORITHM=inplace; alter table t engine=innodb,ALGORITHM=copy; -
建议使用 gh-ost 来做.
optimize table、analyze table和alter table这三种方式重建表的区别.- 从 MySQL 5.6 版本开始,alter table t engine = InnoDB(也就是 recreate);
analyze table t其实不是重建表,只是对表的索引信息做重新统计,没有修改数据,这个过程中加了 MDL 读锁;optimize table t等于 recreate+analyze.
-
-
对索引字段做函数操作, 可能会破坏索引值的有序性, 因此优化器就决定放弃走树搜索功能. 比如隐式转换(字符转数字),字符集不一致(utf-8与uft8mb4)等都有可能产生函数操作,引起优化器放弃树搜索.
七. 性能提升
临时性能提升
- 第一种方法:先处理掉那些占着连接但是不工作的线程。有损处理,会Kill掉正在处理事务的连接,或导致客户端lost connection 错误.
避免大量使用短连接.
# 查看事务具体状态
select * from information_schema.innodb_trx\G
# 从服务器断开连接使用 kill connection + id 的命令
kill connection 5
- 第二种方法:减少连接过程的消耗。
如果你启用–skip-grant-tables 参数, MySQL 会默认把 –skip-networking 参数打开, 表示这时候数据库只能被本地的客户端连接。
- 慢查询性能问题
- 索引没有设计好;Online DDL
- SQL 语句没写好;使用query_rewrite 功能.
- MySQL 选错了索引。
- QPS突增问题, 新业务bug? 某个语句QPS暴涨?
IO性能瓶颈
- 设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数, 减少 binlog 的写盘次数。这个方法是基于“额外的故意等待”来实现的, 因此可能会增加语句的响应时间, 但没有丢失数据的风险。
- 将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000)。这样做的风险是, 主机掉电时会丢 binlog 日志。
- 将 innodb_flush_log_at_trx_commit 设置为 2。这样做的风险是, 主机掉电的时候会丢数据。
主备数据一致性
mysql数据储存
binlog 的写入机制
binlog 的写入逻辑比较简单:事务执行过程中, 先把日志写到 binlog cache, 事务提交的时候, 再把 binlog cache 写到 binlog 文件中
系统给 binlog cache 分配了一片内存, 每个线程一个, 参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小, 就要暂存到磁盘。
每个线程有自己
binlog cache, 但是共用同一份 binlog 文件。
- 图中的
write, 指的就是指把日志写入到文件系统的 page cache, 并没有把数据持久化到磁盘, 所以速度比较快。- 图中的
fsync, 才是将数据持久化到磁盘的操作。一般情况下, 我们认为fsync才占磁盘的 IOPS。
write和fsync的时机, 是由参数 sync_binlog 控制的:
sync_binlog=0的时候, 表示每次提交事务都只write, 不fsync;sync_binlog=1的时候, 表示每次提交事务都会执行fsync;sync_binlog=N(N>1)的时候, 表示每次提交事务都write, 但累积 N 个事务后才fsync。NOTE: 将
sync_binlog设置为 N, 对应的风险是:如果主机发生异常重启, 会丢失最近 N 个事务的binlog日志。
二. redo log 的写入机制
为了控制 redo log 的写入策略, InnoDB 提供了innodb_flush_log_at_trx_commit参数, 它有三种可能取值:
- 设置为 0 的时候, 表示每次事务提交时都只是把
redo log留在redo log buffer中 ; - 设置为 1 的时候, 表示每次事务提交时都将
redo log直接持久化到磁盘; - 设置为 2 的时候, 表示每次事务提交时都只是把
redo log写到 page cache。
InnoDB 有一个后台线程, 每隔 1 秒, 就会把 redo log buffer 中的日志, 调用 write 写到文件系统的page cache, 然后调用 fsync 持久化到磁盘。
除了后台线程每秒一次的轮询操作外, 还有两种场景会让一个没有提交的事务的 redo log 写入到磁盘中.
redo log buffer占用的空间即将达到innodb_log_buffer_size一半的时候, 后台线程会主动写盘- 并行的事务提交的时候, 顺带将这个事务的
redo log buffer持久化到磁盘
定位性能瓶颈
1. Performance Schema
MySQL的Performance Schema是一套内存表, 用于跟踪MySQL的性能指标。它实际上使用PERFORMANCE_SCHEMA存储引擎, 用户操作performance_schema数据库中的表, Performance Schema仅对本地服务器有效, 所有的更改不会复制到其它的服务器.
Performance Schema的表大致可以分为6个组, 配置、当前事件、历史、实例、摘要, 及其它.
用户可以通过修改setup_%表的内容配置Performance Schema:
- setup_actors: 检测有哪些前台线程
- setup_instruments: 收集哪些服务器度量指标, 生产者
- setup_consumers: 监控的事件存储在哪里, 消费者
- setup_objects: 检测有哪些对象
- setup_threads: 检测有哪些线程分类
Performance Schema中存在大量的检测项目, 检测项目对应MySQL服务器的源代码检测点, 检测项目名称由一系列部件组成采用“/”分割, 从左到右, 从通用到具体:
wait/io/file/myisam/log stage/sql/closing tables
- idle: 检测的空闲事件
- error: 检测的错误事件
- memory: 检测的内存事件
- stage: 检测的阶段事件
- statement: 检测的语句事件
- transaction: 检测的事务事件
- wait: 检测的等待事件
1.1 Performance Schema表的分类
1.1.1 语句事件记录表
记录语句事件信息的表,包括:
events_statements_current(当前语句事件表)events_statements_history(历史语句事件表)events_statements_history_long(长语句历史事件表)summary表(聚合后的摘要表)。其中,summary表还可以根据账号(account)、主机(host)、程序(program)、线程(thread)、用户(user)和全局(glo`bal) 再进行细分。
show tables like 'events_statement%';
1.1.2 等待事件记录表
与语句事件记录表类似。
show tables like 'events_wait%';
1.1.3 阶段事件记录表
记录语句执行阶段事件的表,与语句事件记录表类似。
show tables like 'events_stage%';
1.1.4 事务事件记录表
记录与事务相关的事件的表,与语句事件记录表类似。
show tables like 'events_transaction%';
1.1.5 监视文件系统层调用的表
show tables like '%file%';
1.1.6 监视内存使用的表
show tables like '%memory%';
1.1.7 动态对 performance_schema 进行配置的配置表
show tables like '%setup%';
1.2 启用 Performance Schema
确保在mysql.cnf配置文件中启用, 并重启mysql:
[mysqld]
performance_schema=ON
重启后查看是否已经启用:
SHOW VARIABLES LIKE 'performance_schema';
1.3 使用 Performance Schema
USE performance_schema;
-- 查询最近10分钟的SQL执行次数
SELECT DIGEST_TEXT, COUNT_STAR, SUM_TIMER_WAIT / 1000000000 AS total_exec_time_sec FROM events_statements_summary_by_digest WHERE LAST_SEEN >= (NOW() - INTERVAL 10 MINUTE) ORDER BY COUNT_STAR DESC LIMIT 20;
-- 哪类的SQL执行最多?
SELECT DIGEST_TEXT,COUNT_STAR,FIRST_SEEN,LAST_SEEN FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
-- 哪类SQL的平均响应时间最多?
SELECT DIGEST_TEXT,AVG_TIMER_WAIT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
-- 哪类SQL排序记录数最多?
SELECT DIGEST_TEXT,SUM_SORT_ROWS FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
-- 哪类SQL扫描记录数最多?
SELECT DIGEST_TEXT,SUM_ROWS_EXAMINED FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
-- 哪类SQL使用临时表最多?
SELECT DIGEST_TEXT,SUM_CREATED_TMP_TABLES,SUM_CREATED_TMP_DISK_TABLES FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
-- 哪类SQL返回结果集最多?
SELECT DIGEST_TEXT,SUM_ROWS_SENT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
-- 哪个表物理IO最多?
SELECT file_name,event_name,SUM_NUMBER_OF_BYTES_READ,SUM_NUMBER_OF_BYTES_WRITE FROM file_summary_by_instance ORDER BY SUM_NUMBER_OF_BYTES_READ + SUM_NUMBER_OF_BYTES_WRITE DESC
-- 哪个表逻辑IO最多?
SELECT object_name,COUNT_READ,COUNT_WRITE,COUNT_FETCH,SUM_TIMER_WAIT FROM table_io_waits_summary_by_table ORDER BY sum_timer_wait DESC
-- 哪个索引访问最多?
SELECT OBJECT_NAME,INDEX_NAME,COUNT_FETCH,COUNT_INSERT,COUNT_UPDATE,COUNT_DELETE FROM table_io_waits_summary_by_index_usage ORDER BY SUM_TIMER_WAIT DESC
-- 哪个索引从来没有用过?
SELECT OBJECT_SCHEMA,OBJECT_NAME,INDEX_NAME FROM table_io_waits_summary_by_index_usage WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA <> 'mysql' ORDER BY OBJECT_SCHEMA,OBJECT_NAME;
-- 哪个等待事件消耗时间最多?
SELECT EVENT_NAME,COUNT_STAR,SUM_TIMER_WAIT,AVG_TIMER_WAIT FROM events_waits_summary_global_by_event_name WHERE event_name != 'idle' ORDER BY SUM_TIMER_WAIT DESC
-- 剖析某条SQL的执行情况,包括statement信息,stege信息,wait信息
SELECT EVENT_ID,sql_text FROM events_statements_history WHERE sql_text LIKE '%count(*)%';
-- 查看每个阶段的时间消耗
SELECT event_id,EVENT_NAME,SOURCE,TIMER_END - TIMER_START FROM events_stages_history_long WHERE NESTING_EVENT_ID = 1553;
-- 查看每个阶段的锁等待情况
SELECT event_id,event_name,source,timer_wait,object_name,index_name,operation,nesting_event_id FROM events_waits_history_long WHERE nesting_event_id = 1553;
2. 慢查询日志
2.1 启用慢查询日志
确保在mysql.cnf配置文件中启用, 并重启mysql:
[mysqld]
slow_query_log = 1
slow_query_log_file = /var/log/mysql/mysql-slow.log
long_query_time = 0.5
log_queries_not_using_indexes = 1
查看是否已经启用慢查询日志功能:
SHOW VARIABLES LIKE 'slow_query_log';
SHOW VARIABLES LIKE 'slow_query_log_file';
SHOW VARIABLES LIKE 'long_query_time';
SHOW VARIABLES LIKE 'log_queries_not_using_indexes';
2.2 分析慢查询日志
使用 pt-query-digest 工具 (Percona Toolkit 提供) 来解析慢查询日志并生成统计报告:
pt-query-digest /var/log/mysql/mysql-slow.log > slow-query-report.txt
Pickup
LogQL: Log query language
1. Overview
LogQL 是 Grafana Loki 的受 promql 启发的查询语言. 查询的行为就好像它们是聚合日志源的分布式 grep. LogQL 使用标签和运算符进行过滤.
有两种类型的 LogQL 查询:
- [Log queries](#二. Log queries ) 返回日志行的内容.
- [Metric queries](#三. Metric queries) 基于扩展日志查询结果来计算值
二元操作符
算术操作符
+(addition)-(subtraction)*(multiplication)/(division)%(modulo)^(power/exponentiation)
逻辑和集合运算符
and(intersection)or(union)unless(complement)
比较运算符
==(equality)!=(inequality)>(greater than)>=(greater than or equal to)<(less than)<=(less than or equal to)
关键字 on 和 ignoring
注释
使用 # 注释
二. Log queries
_ optional log pipeline _
/ \
filter operator
|= \
!= | line filter expression
|~ |
!~ /
{ stream selector }
= \
!= |
=~ \ label filter
!~ / expression
> >= |
< <= /
parser expression
line format expressin
label format expression
日志流选择器(Log stream selector)
流选择器确定要在查询结果中包含哪些日志流. 日志流是日志内容的唯一来源, 例如文件.
日志流选择器由一个或多个逗号分隔的键值对指定, 大括号({ and })分隔流选择器.
支持以下标签匹配运算符:
=: exactly equal!=: not equal=~: regex matches!~: regex does not match
日志管道(Log pipeline)
日志管道可以附加到日志流选择器以进一步处理和过滤日志流. 它是由一组表达式组成的. 对于每个日志行, 每个表达式按从左到右的顺序执行. 如果表达式过滤掉一条日志行, 则管道将停止处理当前日志行, 并开始处理下一条日志行.
日志管道表达式可分为三类:
- 过滤表达式: [行过滤](#行过滤(Line filter expression))和[标签过滤](#标签过滤(Label filter expressions))
- 解析表达式
- 格式化表达式: line format expressions and label format expressions
行过滤(Line filter expression)
行过滤表达式支持以下匹配运算符:
|=: Log line contains string!=: Log line does not contain string|~: Log line contains a match to the regular expression!~: Log line does not contain a match to the regular expression
标签过滤(Label filter expressions)
标签过滤器表达式允许使用原始和提取的标签过滤日志行,它可以包含多个谓词.
谓词包含一个标签标识符、一个操作和一个要进行比较的标签值.
我们支持从查询输入自动推断的多个值类型
- String是用双引号或反引号
- Duration 有效的时间单位: “ns”, “us” (or “µs”), “ms”, “s”, “m”, “h”.
- Number
- Bytes有效的字节单位: “b”, “kib”, “kb”, “mib”, “mb”, “gib”, “gb”, “tib”, “tb”, “pib”, “pb”, “eib”, “eb”.
String类型与Prometheus的标签选择器一致, 可以使用相同的操作(=,!=,=~,!~)
The string type is the only one that can filter out a log line with a label
__error__.
使用 Duration, Number 和 Bytes 将在比较之前转换标签值, 并支持以下比较器:
==or=for equality.!=for inequality.>and>=for greater than and greater than or equal.<and<=for lesser than and lesser than or equal.
解析器
解析器表达式可以从日志内容中解析和提取标签. 然后可以使用提取的标签来使用标签筛选器表达式进, 或者用于度量聚合.
Loki 支持 JSON, logfmt, pattern, regexp and unpack parsers.
JSON
JSON解析器支持两种模式
- 无参数
如果日志行是有效的 json 文档, 那么向管道添加| json将提取所有 json 属性作为标签, NOTE: 数组将被忽略
- 有参数
如果日志行是有效的 json 文档, 那么向管道添加| json label="expression1", another="expression2"将提取指 json 属性作为标签.
logfmt
可以使用| logfmt 添加 logfmt 解析器, 并从 logfmt 格式化的日志行中提取所有键和值.
Pattern
模式分析器通过定义模式表达式(| pattern”< pattern-expression >”) , 允许从日志行显式提取字段. 表达式匹配日志行的结构.
考虑该NGINX的日志行
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""
<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>上面模式表达式将提取这些字段:
"ip" => "0.191.12.2" "method" => "GET" "uri" => "/api/plugins/versioncheck" "status" => "200" "size" => "2" "agent" => "Go-http-client/2.0"
模式表达式由捕获和文本组成.
捕获是由 < 和 > 字符分隔的字段名. 一位匿名的捕获显示为<_>.
Regular expression
与 logfmt 和 json (隐式地提取所有值并且不带参数)不同, regexp 解析器采用单个参数 | regexp“ < re >”
unpack
解析器解析 JSON 日志行, 解压打包阶段中的所有嵌入标签. 还将使用一个特殊属性 **_entry**来替换原始日志行.
行格式表达式(Line format expression)
行格式表达式可以使用 text/template格式重写日志行内容, 它只接受一个字符串参数| line_format "{{.label_name}}",所有标签都是注入到模板中的变量, 可以使用{{ . label _ name }}符号.
标签格式表达式(Labels format expression)
| label _ format 表达式可以重命名、修改或添加标签. 它接受一个逗号分隔的等式操作列表作为参数, 以便一次执行多个操作.
当两端都是标签标识符(例如 dst = src)时, 操作将把 src 标签重命名为 dst.
左边也可以是模板字符串(双引号或反勾号) , 例如 dst = “{{.status}} {{.query}}”, 在这种情况下, dst 标签值被文本/模板计算的结果替换. 这是与| line _ format表达式相同的模板引擎, 这意味着标签可以作为变量使用, 您可以使用相同的函数列表.
在这两种情况下, 如果目标标签不存在, 则创建一个新的目标标签.
重命名表单 dst = src 将在重新映射到 dst 标签后删除 src 标签. 但是, 模板将保留引用的标签, 例如 dst="{{.src}}",结果在 dst 和 src 具有相同的值
三. Metric queries
四. Template function
五. Matching IP addresses
六. Query Example
PromQL: prometheus query language
- PromQL: prometheus query language
1. Concepts
1.1 Data model
Prometheus 存储所有数据作为时间序列.
1.1.1 Metric names and labels
每个时间序列都由其Metric names和可选的键值称为label作为唯一识别。
Metric names满足[a-zA-Z_:][a-zA-Z0-9_:]*(NOTE::保留用于用户定义的记录规则. )label满足[a-zA-Z0-9_]*, 以__开头的标签名为内部使用
1.1.2 Samples
来自实际时间序列数据的示例。每个样本包括:
-
一个float64的值
-
一个毫秒的精确时间戳
1.1.3 Notation
给定Metric names和一组label, 经常使用此识别时间序列:
<metric name>{<label name>=<label value>, ...}
1.2 Metric types
Prometheus客户端库提供四种核心度量标准类型
1.2.1 Counter
Counter是一个累积度量标准, 代表单个单调增加的计数器, 其值只能增加或在重新启动时重置为零。例如, 您可以使用计数器来表示已服务的请求数量, 完成任务或错误.
1.2.2 Gauge
Gauge是代表可以任意上下改变的单个数值值的度量。通常用于测量值, 例如温度或当前内存使用情况, 但也可以“计数”, 例如同时的请求数量。
1.2.3 Histogram
Histogram样本观察(通常是请求持续时间或响应大小的内容), 并在可配置的存储桶中对其进行计数。它还提供了所有观察到的值的总和。
1.2.4 Summary
类似于Histogram, Summary样本观察(通常是请求持续时间和响应大小的东西)。虽然它还提供了总检测数量和所有观察到的值的总和, 但它通过滑动时间窗口计算可配置的定量
1.3 Jobs and instances
Job: 采集的工作目标
instances: 采集的目标实例
2. promQL
Prometheus提供了一个功能性查询语言, 这使用户可以实时选择和聚合时间序列数据。表达式的结果可以显示为图形, 将其视为Prometheus表达式浏览器中的图形数据, 也可以通过HTTP API被外部系统使用。
2.1 Expression language data types
在Prometheus的表达语言中, 表达式或子表达包括以下四种类型之一:
-
Instant vector- 瞬时向量集合: 一组时间序列, 每个时间序列的单个样本, 它们共享相同的时间戳 -
Range vector- 区间值集合: 一组时间序列, 其中每个时间序列都包含一系列数据点 -
Scalar- 标量: 一个简单的数字浮点值 -
String- 字符串: 简单的字符串值, 当前未使用
2.2 literals
2.2.1 String literals
字符串可以用单引号, 双引号或反引号。遵循和go一样的转义规则
2.2.2 Float literals
标量浮点值可以以格式写入文字整数或浮点数(仅包含用于更好可读性的空格):
[-+]?(
[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?
| 0[xX][0-9a-fA-F]+
| [nN][aA][nN]
| [iI][nN][fF]
)
2.3 Time series Selectors
2.3.1 Instant vector selectors
瞬时向量选择器(Instant vector selectors)允许使用简单指定Metric names获取在给定时间戳(瞬时)选择一组时间序列样本值. 结果包含一个时间序列的瞬时向量集合.
比如:
http_requests_total
你可以过滤这些集合, 通过labels进行选择,
http_requests_total{job="prometheus",group="canary"}
以下标签匹配操作:
=: Select labels that are exactly equal to the provided string.!=: Select labels that are not equal to the provided string.=~: Select labels that regex-match the provided string.!~: Select labels that do not regex-match the provided string.
NOTE: Metric names不能为关键值,如 bool, on, ignoring, group_left and group_right
2.3.2 Range Vector Selectors
区间向量选择器(Range vector)和瞬时向量集合选择器(Instant vector selectors)一样的工作系统,它从范围内选择一系列瞬时间做为集合的元素.
# 表示从过云5分钟内所有http_requests_total且label键值对为job,key的值
http_requests_total{job="prometheus"}[5m]
Time Durations
ms- millisecondss- secondsm- minutesh- hoursd- days - assuming a day has always 24hw- weeks - assuming a week has always 7dy- years - assuming a year has always 365d
Offset modifier
offset允许更改查询中各个瞬间和范围向量的时间偏移.
http_requests_total offset 5m
sum(http_requests_total{method="GET"} offset 5m)
rate(http_requests_total[5m] offset 1w)
rate(http_requests_total[5m] offset -1w)
@ modifier
@修改器允许更改查询中各个即时和范围向量的评估时间。提供给@修改器的时间是UNIX时间戳, 并用浮点文字描述。
http_requests_total @ 1609746000
2.3.3 Subquery
子查询允许您为给定范围和分辨率运行即时查询。子查询的结果是区间向量集合。
语法: <instant_query> '[' <range> ':' [<resolution>] ']' [ @ <float_literal> ] [ offset <duration> ]
<resolution>是可选的, 默认值是全局评估间隔
2.3.4 Operators
Prometheus支持许多二元和聚合操作。
2.3.5 Functions
Prometheus支持多个运行数据的功能.see Functions
2.3.6 Comments
PromQL supports line comments that start with #
# This is a comment
2.3.7 Gotchas
- Staleness
- Avoiding slow queries and overloads
2.4 Operators
2.4.1 Binary operators
Arithmetic binary operators
+(addition)-(subtraction)*(multiplication)/(division)%(modulo)^(power/exponentiation)
Comparison binary operators
==(equal)!=(not-equal)>(greater-than)<(less-than)>=(greater-or-equal)<=(less-or-equal)
Logical/set binary operators
and(intersection)or(union)unless(complement)
2.4.2 Vector matching
集合之间的操作试图在左侧的每个条目中在右侧矢量中找到匹配元素。匹配行为有两种基本类型:一对一, 一对一/一对一。
2.4.3 Aggregation operators
sum(calculate sum over dimensions)min(select minimum over dimensions)max(select maximum over dimensions)avg(calculate the average over dimensions)group(all values in the resulting vector are 1)stddev(calculate population standard deviation over dimensions)stdvar(calculate population standard variance over dimensions)count(count number of elements in the vector)count_values(count number of elements with the same value)bottomk(smallest k elements by sample value)topk(largest k elements by sample value)quantile(calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions)
2.4.4 Binary operator precedence
^*,/,%,atan2+,-==,!=,<=,<,>=,>and,unlessor
2.5 Functions
see Functions
XPath语法
XPath 是一门在XML文档中查找信息的语言.
一. 简介
1. XPath 路径表达式
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集.
这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似.
2. XPath 标准函数
XPath 含有超过 100 个内建的函数.这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等.
二. XPath节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点.
-
XML文档是被作为节点树来对待的.
-
树的根被称为文档节点或者根节点.
三. XPath语法
1. 选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或节点集, 节点是通过沿着路径(path)或者步(steps) 来选取的.
下面列出了最有用的路径表达式
| 表达式 | 描述 |
|---|---|
nodename | 选取此节点的所有子节点。 |
/ | 从根节点选取。 |
// | 从匹配选择的当前节点选择文档中的节点, 而不考虑它们的位置。 |
. | 选取当前节点。 |
.. | 选取当前节点的父节点。 |
@ | 选取属性。 |
实例:
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>实例选取:
路径表达式 结果 bookstore 选取 bookstore 元素的所有子节点. /bookstore 选取根元素 bookstore.
注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!bookstore/book 选取属于 bookstore 的子元素的所有 book 元素. //book 选取所有 book 子元素,而不管它们在文档中的位置. bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置. //@lang 选取名为 lang 的所有属性. //@lang/text() 选取名为 lang 的所有属性下的所有文本
2. 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点, 谓语被嵌在**方括号[]**中.
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang=‘eng’] 选取所有 title 元素, 且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素, 且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]//title 选取 bookstore 元素中的 book 元素的所有 title 元素, 且其中的 price 元素的值须大于 35.00。
3. 选取未知节点
XPath 通配符可用来选取未知的 XML 元素.
| 通配符 | 描述 |
|---|---|
* | 匹配任何元素节点. |
@* | 匹配任何属性节点. |
node() | 匹配任何类型的节点. |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 /bookstore/* 选取 bookstore 元素的所有子元素. //* 选取文档中的所有元素. //title[@*] 选取所有带有属性的 title 元素.
4. 选取若干路径
通过在路径表达式中使用"|"运算符选取多个路径.
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素. //title | //price 选取文档中的所有 title 和 price 元素. /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素.
四. XPath 轴(Axes)
轴可定义相对于当前节点的节点集.
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| following-sibling | 选取当前节点之后的所有兄弟节点 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点 |
五. XPath 运算符
XPath 表达式可返回节点集、字符串、逻辑值以及数字
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| ` | ` | 计算两个节点集 | //book | //cd |
+ | 加法 | 6 + 4 | 10 |
- | 减法 | 6 - 4 | 2 |
* | 乘法 | 6 * 4 | 24 |
div | 除法 | 8 div 4 | 2 |
= | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true.如果 price 是 9.90,则返回 false. |
!= | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true.如果 price 是 9.80,则返回 false. |
< | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true.如果 price 是 9.90,则返回 false. |
<= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true.如果 price 是 9.90,则返回 false. |
> | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true.如果 price 是 9.80,则返回 false. |
>= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true.如果 price 是 9.70,则返回 false. |
or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true.如果 price 是 9.50,则返回 false. |
and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true.如果 price 是 8.50,则返回 false. |
mod | 计算除法的余数 | 5 mod 2 | 1 |
六. 函数
css选择器
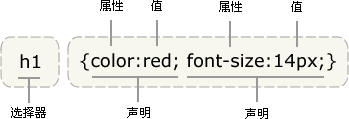
1. 基本选择器
1.1 通配选择器
/* 选中所有元素 */
* {
color: orange;
font-size: 40px;
}
1.2 元素选择器
文档的元素就是元素选择器,是最基本的选择器
html { color:black; }
h1 { color:blue; }
h2 { color:silver; }
1.3. 类选择器
类选择器允许以一种独立于文档元素的方式来指定样式.
<h1 class="important">
This heading is very important.
</h1>
.important {color:red;}
1.4. ID选择器
ID选择器允许以一种独立于文档元素的方式来指定样式
<p id="intro">This is a paragraph of introduction.</p>
#intro {font-weight:bold;}
2. 复合选择器
2.1 交集选择器
选中同时符合多个条件的元素
/* 选中:类名为beauty的p元素, 为此种写法用的非常多!!!! */
p.beauty {
color: blue;
}
/* 选中:类名包含rich和beauty的元素 */
.rich.beauty {
color: green;
}
2.2 并集选择器
选中多个选择器对应的元素(以','分隔), 被分组的选择器就可以分享相同的声明, 又称:分组选择器
h1,
h2,
h3,
h4,
h5,
h6 {
color: green;
}
2.3. 后代选择器
后代选择器可以选择作为某元素后代的元素(以空格分隔)
h1 em {color:red;}
2.4. 子代选择器
与后代选择器相比, 子元素选择器只能选择作为某元素子元素的元素(以>分隔).
h1 > strong {color:red;}
2.5. 相邻兄弟选择器
相邻兄弟选择器 (Adjacent sibling selector) 可选择紧接在另一元素后的元素, 且二者有相同父元素(以+分隔).
h1 + p {margin-top:50px;}
2.6. 属性选择器
属性选择器可以根据元素的属性及属性值来选择元素.
2.6.1. 简单属性选择
如果您希望把包含标题 (title) 的所有元素变为红色, 可以写作:
*[title] {color:red;} // 把包含标题 (title) 的所有元素变为红色
a[href] {color:red;} // 只对有 href 属性的锚 (a 元素) 应用样式
a[href][title] {color:red;} // 将同时有 href 和 title 属性的 HTML 超链接的文本设置为红色
img[alt] {border: 5px solid red;} // 所有带有 alt 属性的图像应用样式, 从而突出显示这些有效的图像
2.6.2. 根据具体属性值选择
a[href="http://www.w3school.com.cn/"][title="W3School"] {color: red;} // 把多个属性-值选择器链接在一起来选择一个文档
p[class="important warning"] {color: red;} // 根据具体属性值来选择该元素
| 选择器 | 描述 |
|---|---|
| [attribute] | 选取带有attribute属性的元素. |
| [attribute=value] | 选取attribute属性值为value的元素. |
| [attribute~=value] | 选取attribute属性值中包含value的元素. |
| [attribute|=value] | 选取attribute属性值等于value或value开头的元素, 该值必须是整个单词. |
| [attribute^=value] | 选取attribute属性值value开头的每个元素. |
| [attribute$=value] | 选取attribute属性值value结尾的每个元素. |
| [attribute*=value] | 选取attribute属性值包含value的每个元素. |
2.7. 伪类
伪类用于向某些选择器添加特殊的效果
selector : pseudo-class {property: value}
2.7.1. 锚伪类
a:link {color: #FF0000} /* 未访问的元素 */
a:visited {color: #00FF00} /* 已访问的元素 */
a:hover {color: #FF00FF} /* 鼠标悬停在元素上 */
a:active {color: #0000FF} /* 激活的元素 */
a:focus {color: #0000FF} /* 获取焦点的元素 */
2.7.2. 结构伪类
:first-child所有兄弟元素中的第一个.:last-child所有兄弟元素中的最后一个.:nth-child(n)所有兄弟元素中的第 n 个.:first-of-type所有同类型兄弟元素中的第一个.:last-of-type所有同类型兄弟元素中的最后一个.:nth-of-type(n)所有同类型兄弟元素中的第n个.:nth-last-child(n)所有兄弟元素中的倒数第n个.:nth-last-of-type(n)所有同类型兄弟元素中的倒数第n个.:only-child选择没有兄弟的元素 (独生子女).:only-of-type选择没有同类型兄弟的元素.:root根元素.:empty内容为空元素 (空格也算内容).:not(选择器)排除满足括号中条件的元素.:checked被选中的复选框或单选按钮.:enable可用的表单元素 (没有disabled属性).:disabled不可用的表单元素 (有disabled属性):target选中锚点指向的元素.:lang()根据指定的语言选择元素 (本质是看 lang 属性的值).
2.8. 伪元素
伪元素用于向某些选择器设置特殊效果
selector:pseudo-element {property:value;}
2.8.1. "first-line"伪元素
"first-line" 伪元素用于向文本的首行设置特殊样式.
p:first-line {
color:#ff0000;
font-variant:small-caps;
}
注释:“first-line” 伪元素只能用于块级元素.
**注释:**下面的属性可应用于 “first-line” 伪元素:
- font
- color
- background
- word-spacing
- letter-spacing
- text-decoration
- vertical-align
- text-transform
- line-height
- clear
2.8.2. :first-letter伪元素
first-letter 伪元素用于向文本的首字母设置特殊样式:
p:first-letter
{
color:#ff0000;
font-size:xx-large;
}
注释:“first-letter” 伪元素只能用于块级元素.
**注释:**下面的属性可应用于 “first-letter” 伪元素:
- font
- color
- background
- margin
- padding
- border
- text-decoration
- vertical-align (仅当 float 为 none 时)
- text-transform
- line-height
- float
- clear
2.8.3. :before伪元素
:before伪元素可以在元素的内容前面插入新内容
h1:before{
content:url(logo.gif);
}
2.8.4. after伪元素
:after 伪元素可以在元素的内容之后插入新内容.
h1:after{
content:url(logo.gif);
}
| 属性 | 描述 | CSS |
|---|---|---|
| :first-letter | 向文本的第一个字母添加特殊样式. | 1 |
| :first-line | 向文本的首行添加特殊样式. | 1 |
| :before | 在元素之前添加内容. | 2 |
| :after | 在元素之后添加内容. | 2 |
3. 选择器权重
行内样式 > ID选择器 > 类选择器 > 元素选择器 > 通配选择器.
4. CSS三大特性
4.1. 层叠性
如果发生了样式冲突, 那就会根据一定的规则 (选择器优先级), 进行样式的层叠 (覆 盖).
4.2 继承性
元素会自动拥有其父元素、或其祖先元素上所设置的某些样式. 优先继承离得近的.
4.3 优先级
!important> 行内样式 > ID选择器 > 类选择器 > 元素选择器 > * > 继承的样式
5. CSS常用属性
5.1 颜色
5.1.1 rgb/rgba
/* 使用 0~255 之间的数字表示一种颜色 */
color: rgb(255, 0, 0);/* 红色 */
color: rgb(0, 255, 0);/* 绿色 */
color: rgb(0, 0, 255);/* 蓝色 */
color: rgb(0, 0, 0);/* 黑色 */
color: rgb(255, 255, 255);/* 白色 */
/* 混合出任意一种颜色 */
color:rgb(138, 43, 226) /* 紫罗兰色 */
color:rgba(255, 0, 0, 0.5);/* 半透明的红色 */
/* 也可以使用百分比表示一种颜色 (用的少) */
color: rgb(100%, 0%, 0%);/* 红色 */
color: rgba(100%, 0%, 0%,50%);/* 半透明的红色 */
5.1.2 HEX/HEXA
color: #ff0000;/* 红色 */
color: #00ff00;/* 绿色 */
color: #0000ff;/* 蓝色 */
color: #000000;/* 黑色 */
color: #ffffff;/* 白色 */
/* 如果每种颜色的两位都是相同的, 就可以简写*/
color: #ff9988;/* 可简为:#f98 */
/* 但要注意前三位简写了, 那么透明度就也要简写 */
color: #ff998866;/* 可简为:#f986 */
5.1.3 HSL/HSLA
格式: hsl(色相,饱和度,亮度)/hsla(色相,饱和度,亮度,透明度)
5.2 字体属性
5.2.1 字体大小
font-size控制字体的大小
div {
font-size: 40px;
}
5.2.2 字体族
font-family控制字体类型
div {
font-family: "STCaiyun","Microsoft YaHei",sans-serif
}
5.2.3 字体风格
font-style控制字体是否为斜体
div {
font-style: italic;
}
5.2.4 字体粗细
font-weight控制字体的粗细
lighter:细normal: 正常bold:粗bolder:很粗
div {
font-weight: bold;
}
div {
font-weight: 600;
}
5.2.5 字体复合写法
字体大小、字体族必须都写上, 字体族必须是最后一位、字体大小必须是倒数第二位.各个属性间用空格隔开.
div {
font: 20px "STCaiyun","Microsoft YaHei",sans-serif;
}
5.3 文本属性
5.3.1 文本颜色
color控制文字的颜色
p {
color: rgb(112,45,78);
}
5.3.2 文本间距
- 字母间距:
letter-spacing - 单词间距:
word-spacing(通过空格识别词) - 属性值为像素 (
px) , 正值让间距增大, 负值让间距缩小
5.3.3 文本修饰
text-decoration控制文本的各种装饰线, 可选值:
none: 无装饰线 (常用)underline:下划线 (常用)overline: 上划线line-through: 删除线
5.3.4 文本缩进
text-indent控制文本首字母的缩进.
div {
text-indent:40px;
}
5.3.5 文本水平对齐
text-align控制文本的水平对齐方式:
left: 左对齐 (默认值)right: 右对齐center: 居中对齐
div {
text-align: center;
}
5.3.6 文本垂直对齐
顶部:无需任何属性, 在垂直方向上, 默认就是顶部对齐
居中:对于单行文字, 让 height = line-height 即可
5.3.7 行高
line-height控制一行文字的高度.
div {
line-height: 60px;
line-height: 1.5; /* 参考自身 font-size 的倍数 */
line-height: 150%; /* 参考自身 font-size 的百分比 */
}
5.3.7 vertical-align
vertical-align用于指定同一行元素之间, 或 表格单元格 内文字的 垂直对齐方式, 不能控制块元素.
baseline(默认值) :使元素的基线与父元素的基线对齐.top:使元素的顶部与其所在行的顶部对齐.middle:使元素的中部与父元素的基线加上父元素字母 x 的一半对齐.bottom:使元素的底部与其所在行的底部对齐.
5.4 列表属性
列表相关的属性, 可以作用在 ul 、 ol 、 li 元素上.
list-style-type设置列表符号
none:不显示前面的标识 (很常用!)square:实心方块disc:圆形decimal:数字lower-roman:小写罗马字upper-roman:大写罗马字lower-alpha:小写字母upper-alpha:大写字母
list-style-position设置列表符号的位置
inside:在li的里面outside:在li的外边
list-style-image自定义列表符号, url(图片地址)
list-style复合属性, 没有数量、顺序的要求
5.5 边框属性
border-width边框宽度CSS 中可用的长度值
border-color边框颜色CSS 中可用的颜色值
border-style边框风格
none默认值solid实线dashed虚线dotted点线double双实线
border边框复合属性, 没有数量、顺序的要求
5.6 表格属性
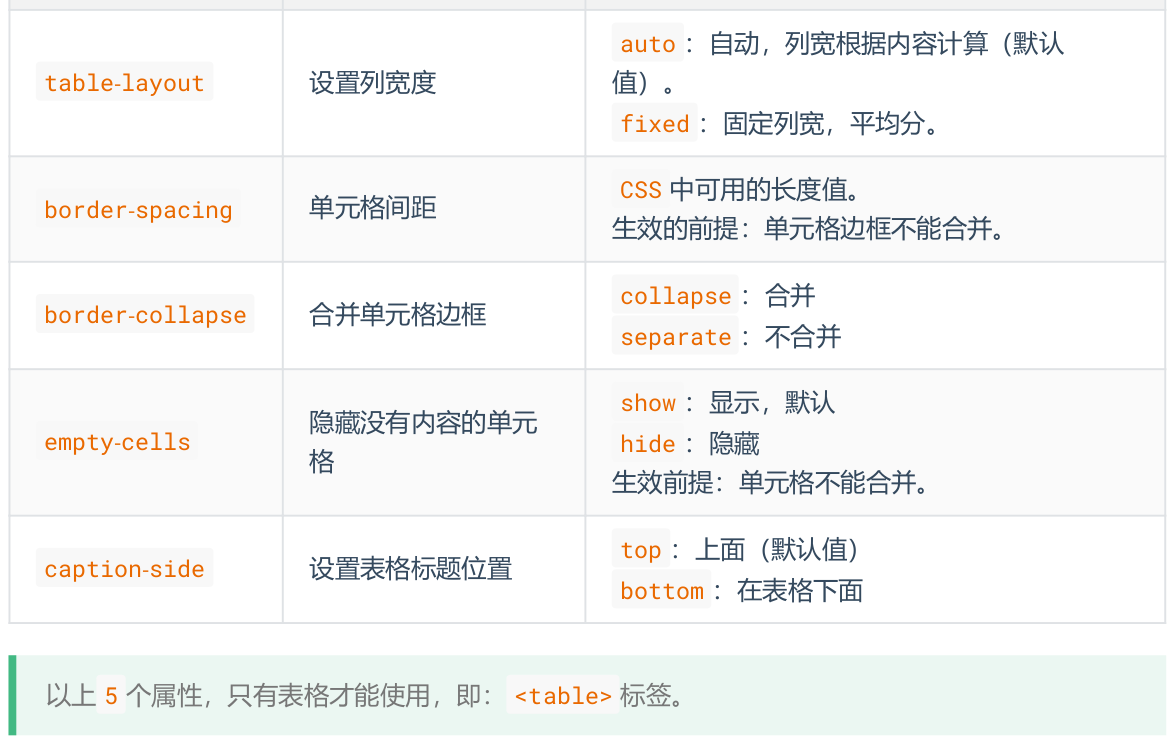
5.7 背景属性
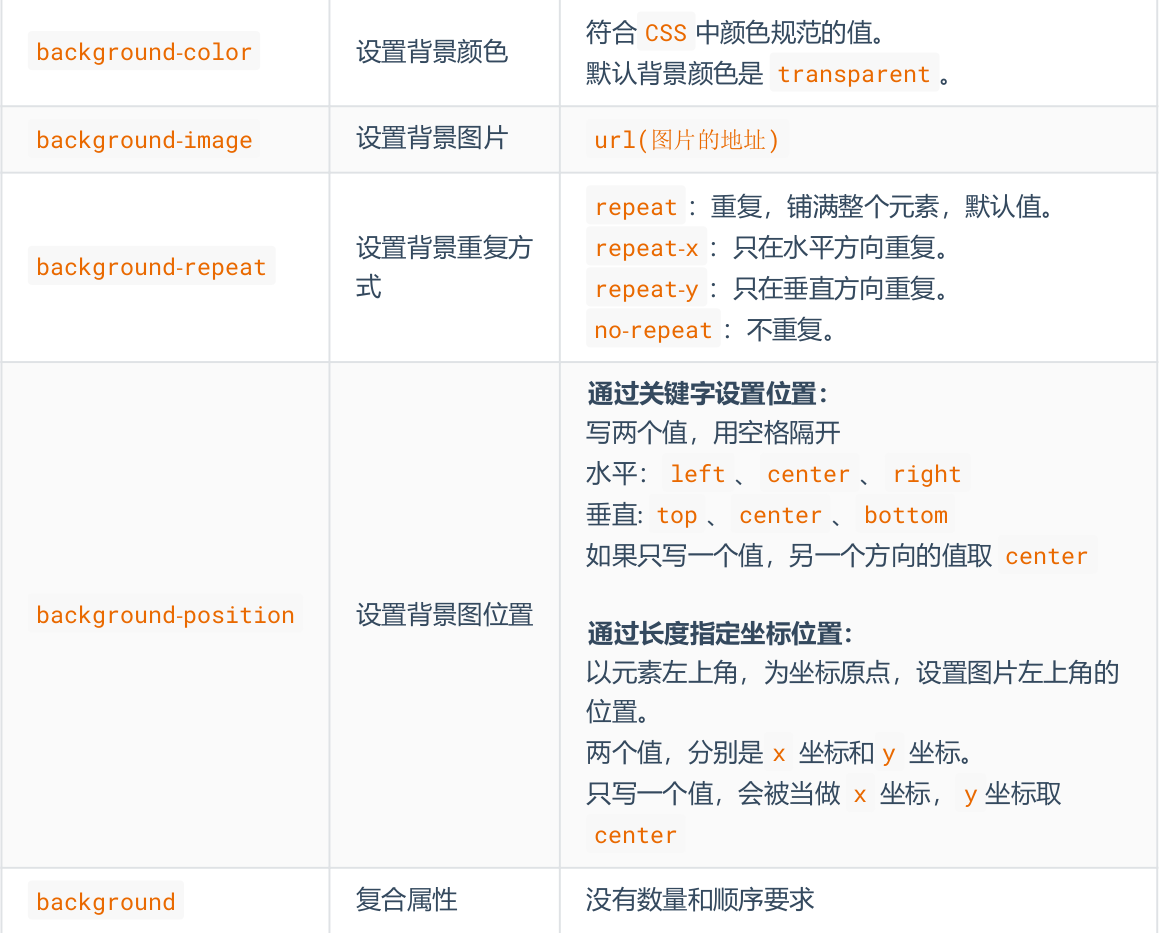
5.7鼠标属性
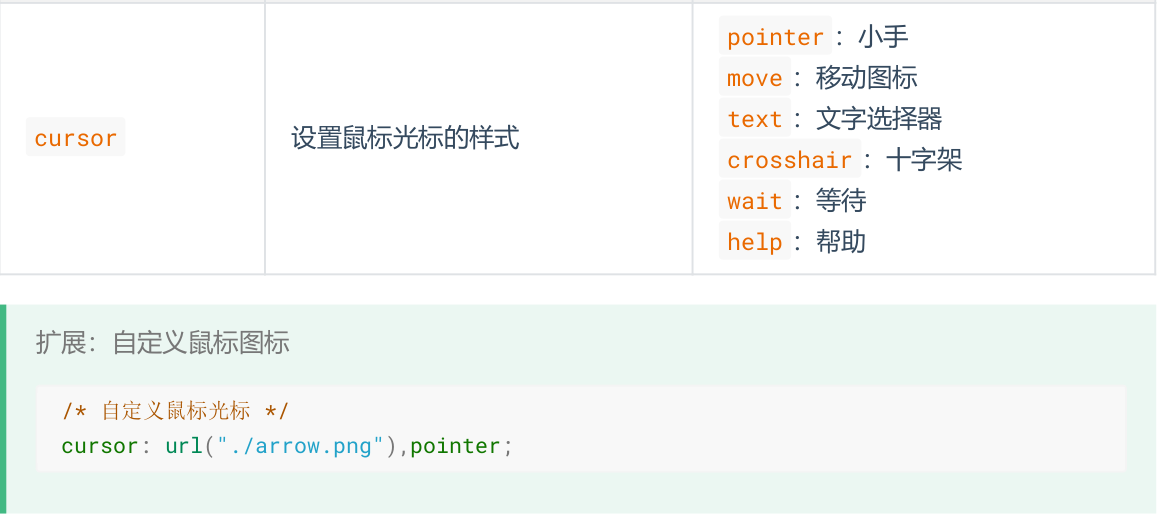
opentelemetry
grep sed awk
1. grep
作用: 文本搜索工具, 根据用户指定的“模式“(过滤条件)对目标文本逐行进行匹配检查, 打印匹配到行.
模式: 由正则表达式的元字符及文本字符所编写的过滤条件
grep [options] [pattern] file
| 参数选项 | 说明 |
|---|---|
-v | 排除匹配结果 |
-n | 显示匹配行与行号 |
-i | 不区分大小写 |
-c | 只统计匹配的行数 |
-E | 只统计匹配的行数 |
--color=auto | 为grep过滤结果添加颜色 |
-w | 只匹配过滤的单词 |
-o | 只输出匹配的内容 |
2. sed
sed [options] [sed内置命令字符] [file]
| 参数选项 | 说明 |
|---|---|
-n | 取消默认sed的输出, 常与sed内置命令p一起用 |
-i | 直接将修改结果写入文件, 不同-i, sed 修改的是内存数据 |
-e | 多次编辑,不需要管道符 |
-r | 支持正则扩展 |
sed的内置命令字符用于文件进行不同的操作功能, 如对文件增删改查
sed的内置命令字符 | 说明 |
|---|---|
a | append, 对文件追加, 在指定行后面添加一行/多行文件 |
d | delete, 删除匹配行 |
i | insert, 表式插入文本, 在指定行前添加一行/多行文本 |
p | print, 打印匹配行的内容, 通常p与-n一起使用 |
s/正则/替换内容/g | 匹配正则内容,然后替换内容(支持正则), 结尾g代表全局匹配 |
sed的匹配范围
| 范围 | 说明 |
|---|---|
| 空地址 | 全文处理 |
| 单地址 | 指定文件某一行 |
/pattern/ | 被模式匹配到的每一行 |
| 范围区间 | 10,20(10到20行), 10,+5(第10行向下5行), /pattern1/, /pattern2/ |
| 步长 | 1~2, 表示1,3,5,7,9行, 2~2两个步长, 表示2,4,6,8,10 偶数行 |
linux信号
| 信号 | 值 | 动作 | 说明 |
|---|---|---|---|
SIGHUP | 1 | Term | 终端控制进程结束(终端连接断开) |
SIGINT | 2 | Term | 用户发送INTR字符(Ctrl+C)触发 |
SIGQUIT | 3 | Core | 用户发送QUIT字符(Ctrl+/)触发 |
| SIGILL | 4 | Core | 非法指令(程序错误、试图执行数据段、栈溢出等) |
| SIGABRT | 6 | Core | 调用abort函数触发 |
| SIGFPE | 8 | Core | 算术运行错误(浮点运算错误、除数为零等) |
SIGKILL | 9 | Term | 无条件结束程序(不能被捕获、阻塞或忽略) |
| SIGSEGV | 11 | Core | 无效内存引用(试图访问不属于自己的内存空间、对只读内存空间进行写操作) |
| SIGPIPE | 13 | Term | 消息管道损坏(FIFO/Socket通信时, 管道未打开而进行写操作) |
| SIGALRM | 14 | Term | 时钟定时信号 |
SIGTERM | 15 | Term | 结束程序(可以被捕获、阻塞或忽略) |
SIGUSR1 | 30,10,16 | Term | 用户保留 |
SIGUSR2 | 31,12,17 | Term | 用户保留 |
| SIGCHLD | 20,17,18 | Ign | 子进程结束(由父进程接收) |
| SIGCONT | 19,18,25 | Cont | 继续执行已经停止的进程(不能被阻塞) |
| SIGSTOP | 17,19,23 | Stop | 停止进程(不能被捕获、阻塞或忽略) |
| SIGTSTP | 18,20,24 | Stop | 停止进程(可以被捕获、阻塞或忽略) |
| SIGTTIN | 21,21,26 | Stop | 后台程序从终端中读取数据时触发 |
| SIGTTOU | 22,22,27 | Stop | 后台程序向终端中写数据时触发 |
linux虚拟网络技术
在Linux虚拟化技术中, 网络层面, 通常重要的三个技术分别是Network Namespace、veth pair、以及网桥或虚拟交换机技术.
参考资料:
一. Network Namespace
Network Namespace, 它是由Linux内核提供, 是实现网络虚拟化的重要功能。
通过创建多个隔离的网络空间, 实现网络资源的隔离。
不同的Network Namespace的资源互相不可见, 彼此之间无法通信。
ip netns命令
ip命令管理的功能很多, 和Network Namespace有关的操作都在其子命令ip netns下进行的, 可以通过ip netns help查询命令帮助信息.
$ ip netns help
Usage: ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id
# ip netns add命令创建一个ns0的网络命名空间
$ ip netns add ns0
# 查看命名空间
$ ip netns list
# 命名空间所在的目录
# 新创建的 Network Namespace 会出现在/var/run/netns/目录下。如果需要管理其他不是 ip netns 创建的 network namespace, 只要在这个目录下创建一个指向对应 network namespace 文件的链接即可。
$ ls /var/run/netns/
对于每个 Network Namespace 来说, 它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。
ip命令提供了ip netns exec子命令可以在对应的 Network Namespace 中执行命令。
# 查看网络命名空间ns0的网卡信息
$ ip netns exec ns0 ip addr
# 默认loopback网卡是不启用的,下面是启用
$ ip netns exec ns0 ip link set lo up
# 在网络命名空间ns0打开shell
$ ip netns exec ns0 /bin/bash
二. veth pair
默认情况下, network namespace 是不能和主机网络或者其他 network namespace 通信的
可以使用 Linux 提供的veth pair来完成通信, veth pair你可以理解为使用网线连接好的两个接口, 把两个端口放到两个namespace中, 那么这两个namespace就能打通。
# 创建veth pair
$ ip link add type veth
# 查看veth pair
$ ip link
# 可以创建时指定两个端点的名称
$ ip link add veth001 type veth peer name veth002
# 再创建一个网络命名空间ns1
$ ip netns add ns1
# 将veth pair 分别加入ns0 ns1
$ ip link set veth0 netns ns0
$ ip link set veth1 netns ns01
# 分别为这对veth pair 配置ip地址并启用
$ ip netns exec ns0 ip addr add 192.168.1.98/24 dev veth0
$ ip netns exec ns0 ip link set veth0 up
$ ip netns exec ns1 ip addr add 192.168.1.99/24 dev veth1
$ ip netns exec ns1 ip link set veth1 up
# 查看这对veth pair的状态
$ sudo ip netns exec ns0 ip addr
$ sudo ip netns exec ns1 ip addr
# 验证互通
$ ip netns exec ns0 ping -c 10 192.168.1.99
$ ip netns exec ns1 ping -c 10 192.168.1.98
删除 Network Namespace
$ ip netns delete ns0
$ ip netns delete ns1
三. bridge
虽然veth pair可以实现两个 Network Namespace 之间的通信, 但 veth pair 有一个明显的缺陷, 就是只能实现两个网络接口之间的通信。
如果多个network namespace需要进行通信, 则需要借助bridge。
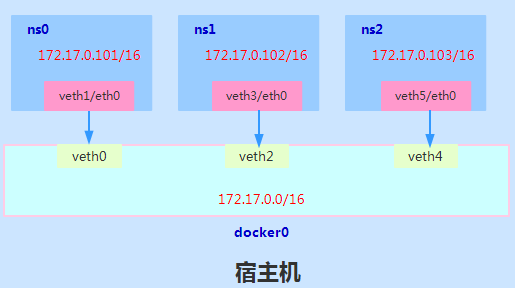
# 创建网桥
$ ip link add docker0 type bridge
# 配置网桥ip
$ ip addr add 172.17.0.1/16 dev docker0
# 启动网桥
$ ip link set dev docker0 up
# 查看网桥状态
$ ip addr docker0
# or
$ ip link show docker0
# or
$ ifconfig docker0
# 删除网桥
$ ip link delete docker0
其它操作同上,可以将所有veth pair加入网桥,形成多个Network Namespace互通
四. tap/tun
tap/tun设备文件就像一个管道, 一端连接着用户空间, 一端连接着内核空间。当用户程序向文件 /dev/net/tun 或 /dev/tap0 写数据时, 内核就可以从对应的 tunX 或 tapX 接口读到数据, 反之, 内核可以通过相反的方式向用户程序发送数据。
- TUN 是一个虚拟网络设备, 它模拟的是一个三层设备, 通过它可以处理来自网络层的数据包, 也就是 IP 数据包。由于它只模拟到了 IP 层, 所以它无法与物理网卡做 bridge, 也没有 MAC 地址, 但是可以通过三层交换的方式来与物理网卡相互通信。
- TAP 模拟的是一个二层设备, 它比 TUN 更加深入, 它可以处理数据链路层的数据包, 拥有 MAC 地址, 可以与物理网卡做 bridge, 支持 MAC 层广播, 也可以给它设置 IP 地址。
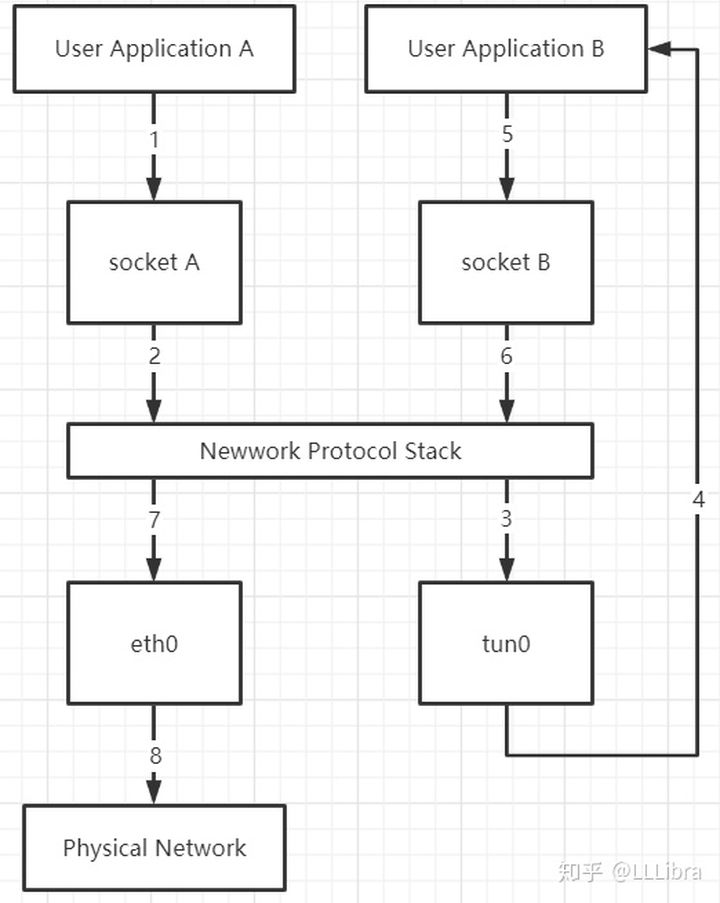
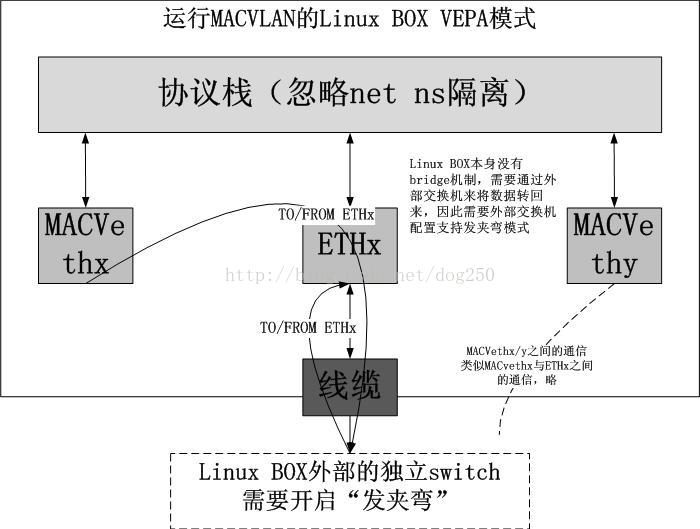
iptables
1. iptables
参考文章 iptables详解 备链
iptables其实不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过iptables这个代理,将用户的安全设定执行到对应的“安全框架“中,这个“安全框架“才是真正的防火墙,这个框架的名字叫netfilter.
netfilter才是防火墙真正的安全框架,netfilter位于内核空间.
iptables其实是一个命令行工具,位于用户空间,我们用这个工具操作真正的框架.
netfilter是Linux操作系统核心层内部的一个数据包处理模块,它具有如下功能:
-
网络地址转换(Network Address Translate)
-
数据包内容修改
-
以及数据包过滤的防火墙功能
1.1 iptables基础
iptables是按照规则来办事的,所谓规则一般的定义为:
“如果数据包头符合这样的条件,就这样处理这个数据包”.规则存储在内核空间的信息包过滤表中,这些规则分别指定了 源地址 、目的地址 、传输协议(如TCP、UDP、ICMP) 和 服务类型(如HTTP、FTP和SMTP) 等.
当数据包与规则匹配时,
iptables就根据规则所定义的方法来处理这些数据包,如 放行(accept) 、拒绝(reject) 和 丢弃(drop) 等.配置防火墙的主要工作就是添加、修改和删除这些规则.
iptables配置的通常就是所说的 四表五链 .
四表: (另外security表不常用,主要用于数据包上应用 SELinux )
raw: 关闭nat表上启用的连接追踪机制; iptable_rawmangle: 拆解报文, 做出修改, 并重新封装 的功能;iptable_manglenat: network address translation,网络地址转换功能;;iptable_natfilter: 负责过滤功能,防火墙;内核模块:iptables_filter
这5张表的优先级从高到低是:
raw->mangle->nat->filter[->security]需要注意的是,
iptables不支持用户自定义表,但支持自定义链.
五链 (标记表的执行优先级次序):
PREROUTING:raw–>mangle–>natINPUT:mangle–>filter(centos7中还有nat表,centos6中没有).FORWARD:mangle- ->filterOUPUT:raw–>mangle–>nat–>filterPOSTROUTING:mangle–>nat
以上看出各个链有对应的表,而且表和表上的规则是有优先级的, 在实际操作使用时,往往是通过操作iptables这些表,对规则进行定义的.
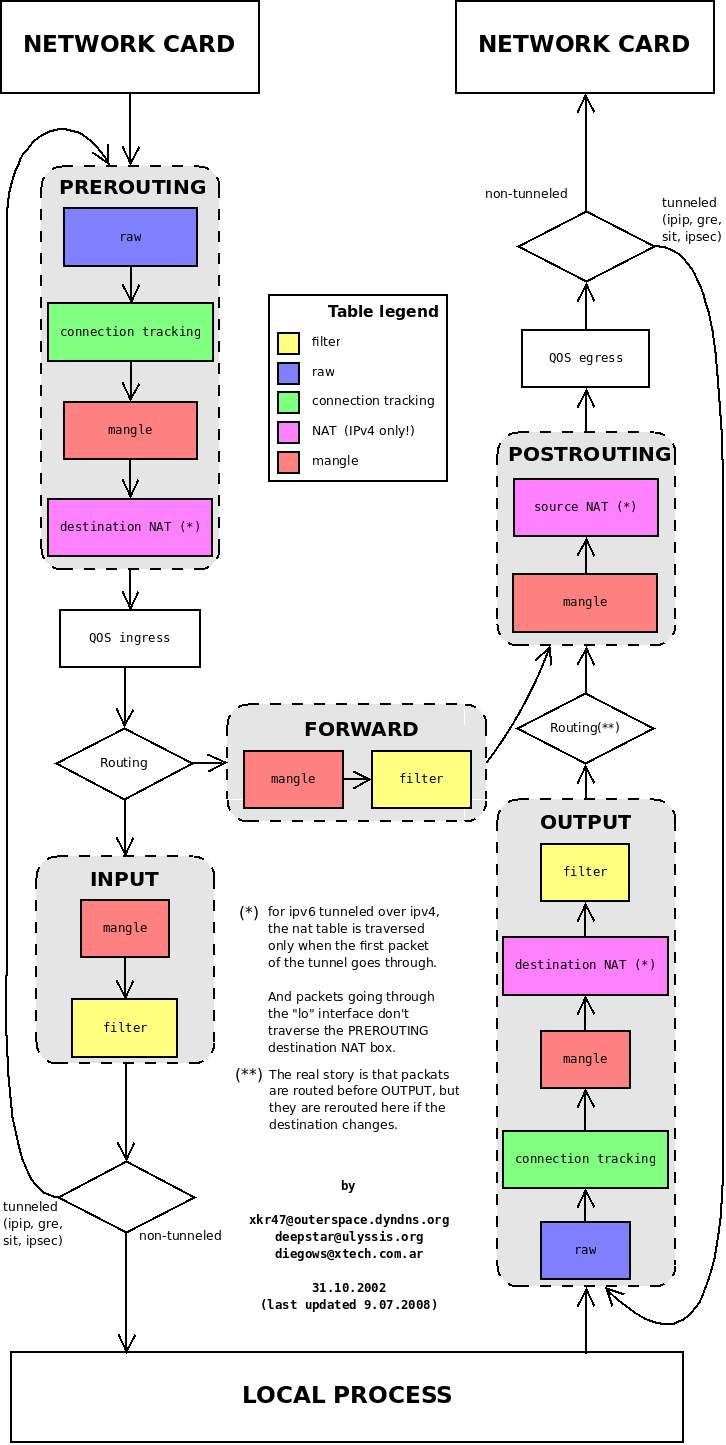
1.2 规则概念
根据指定的匹配条件来尝试匹配每个流经此处的报文,一旦匹配成功,则由规则后面指定的处理动作(target)进行处理.如果不匹配将顺延匹配下一条.
1.2.1 匹配条件
匹配条件分为 基本匹配条件 与 扩展匹配条件
基本匹配条件:
- 源地址: Source IP
- 目标地址: Destination IP
扩展匹配条件:
除了上述的条件可以用于匹配,还有很多其他的条件可以用于匹配,这些条件泛称为 扩展条件 ,这些扩展条件其实也是netfilter中的一部分,只是以模块的形式存在,如果想要使用这些条件,则需要依赖对应的扩展模块.
-
源端口:Source Port
-
目标端口:Destination Port
1.2.2 处理动作
处理动作在iptables中被称为target(这样说并不准确,我们暂且这样称呼),
动作也可以分为 基本动作 和 扩展动作.
此处列出一些常用的动作:
-
ACCEPT:允许数据包通过.
-
DROP:直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求泥牛入海了,过了超时时间才会有反应.
-
REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息.
-
SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题.
-
MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上.
-
DNAT:目标地址转换.
-
REDIRECT:在本机做端口映射.
-
LOG:在
/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配.
2. iptables规则
2.1 规则管理
2.1.1 规则查询
# 查看filter表的所有规则
# -t 指定表
# -L 列出链的规则,如果不指定链,则显示所有
$ iptables -t filter -L
# 查看filter表中INPUT链的规则
$ iptables -t filter -L INPUT
# -v选项,查看更多的,更详细的信息,
# -x选项表示显示计数器的精确值.
$ iptables -t filter -vxL
# 默认是对IP地址进行名称解析
# -n直接显示IP地址,不进行名称解析
$ iptables -t filter -nvL
# --line-numbers 显示行号,可用--line
$ iptables -t filter -nvL --line-numbers
Chain FORWARD (policy DROP 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 4 296 DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0
2 4 296 DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0
3 0 0 ACCEPT all -- * docker0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
链后面括号中的含义:
- policy表示当前链的默认策略,
policy ACCEPT表示上图中INPUT的链的默认动作为ACCEPT - packets表示当前链默认策略匹配到的包的数量,
0 packets表示默认策略匹配到0个包 - bytes表示当前链默认策略匹配到的所有包的大小总和.
规则条目参数:
- pkts: 对应规则匹配到的报文的个数.
- bytes: 对应匹配到的报文包的大小总和.
- target: 规则对应的target,往往表示规则对应的“动作“,即规则匹配成功后需要采取的措施.
- prot: 规则对应的协议,是否只针对某些协议应用此规则.
- opt: 规则对应的选项.
- in: 数据包由哪个接口(网卡)流入,我们可以设置通过哪块网卡流入的报文需要匹配当前规则.
- out: 数据包由哪个接口(网卡)流出,我们可以设置通过哪块网卡流出的报文需要匹配当前规则.
- source: 规则对应的源头地址,可以是一个IP,也可以是一个网段.
- destination: 规则对应的目标地址.可以是一个IP,也可以是一个网段
2.1.2 规则的增删改
# 添加一条规则,表示在filter表的INPUT链追加一条丢弃来自192.168.1.111的规则
# -A: 追加
# -I: 插入表头,可指定位置,在链名后面添加相应数字即可.
# -s: 源地址
# -j: 动作
$ iptables -t filter -A INPUT -s 192.168.1.111 -j DROP
# 根据规则的编号删除规则.
# -D: 删除
$ iptables -t filter -D INPUT 2
# 根据匹配条件去删除规则,NOTE: 有坑,建议选删除再增加.
$ iptables -t filter -D INPUT -s 192.168.1.111 -j DROP
# 清空filter 表的规则
# -F flush 冲刷清除之意.
$ iptables -t filter -F input
# 修改规则
# -R 修改指定条目序号的规则,注意: 必须指定匹配规则,虽然已指定的序号.
$ iptables -t filter -R INPUT 1 -s 192.168.1.111 -j REJECT
2.1.3 保存规则
在默认的情况下,我们对“防火墙“所做出的修改都是“临时的“,换句话说就是,当重启iptables服务或者重启服务器以后,我们平常添加的规则或者对规则所做出的修改都将消失,为了防止这种情况的发生,我们需要将规则“保存“
# 规则默认保存在 /etc/sysconfig/iptables
$ service iptalbes save
# 使用iptables-save并不能保存当前的iptables规则,但是可以将当前的iptables规则以"保存后的格式"输出到屏幕上
# 配合重定向可以自己保存.
$ iptables-save
# 重新载入为当前iptables规则
$ iptables-restore
# 或
$ iptables-restore < /etc/sysconfig/iptables
2.2 规则匹配条件
注意: 不指定源或目标地址,均默认为
0.0.0.0/0多个匹配条件,为“与“关系
2.2.1 源地址
# 单个源地址
$ iptables -t filter -I INPUT -s 192.168.1.111 -j DROP
# 多个源地址,采用','分开,且不能包含空格
$ iptables -t filter -I INPUT -s 192.168.1.111,192.168.1.112 -j DROP
# 指定具体IP地址,还能指定网段
$ iptables -t filter -I INPUT -s 192.168.0.0/16 -j DROP
# 还可以对匹配条件取反,加'!'号
$ iptables -t filter -I INPUT ! -s 192.168.1.111 -j DROP
2.2.2 目标地址
# -d 指定目标地址匹配条件
# 丢弃192.168.1.111发往 192.168.1.120的报文
# 同源地址,目标地址操作,也可以指定多个IP地址(用','分隔),也可以取反,也可以指定网段.
$ iptables -t filter -I INPUT -s 192.168.1.111 -d 192.168.1.120 -j DROP
2.2.3 协议类型
-p指定协议
默认是所有协议-p all)
支持的协议有: tcp, udp, udplite, icmp, icmpv6, esp, ah, sctp, mh等.
2.2.4 网卡接口
-i 指定匹配报文网卡流入,匹配报文是通过哪块网卡流入本机的,只能作用于PREROUTING、INPUT、FORWARD
-o指定匹配报文网卡流出,匹配报文将从哪个网卡流出,只能用于FORWARD、OUTPUT、POSTROUTING.
默认是所有网卡
2.2.5 扩展匹配条件
源端口和目标端口属于扩展匹配条件,如果想要使用扩展匹配条件,则需要依赖一些扩展模块.
2.2.5.1 匹配端口
在使用--dport,--sport之前,我们使用-m选项,指定了对应的扩展模块为tcp,也就是说,如果想要使用--dport,--sport这个扩展匹配条件,则必须依靠某个扩展模块完成.
当使用-p选项指定了报文的协议时,如果在没有使用-m指定对应的扩展模块名称的情况下,使用了扩展匹配条件, iptables默认会调用与-p选项对应的协议名称相同的模块
- 目标端口: 使用选项
--dport可以匹配报文的目标端口,--dport意为destination-port,即表示目标端口. - 源端口: 使用选项
--sport可以匹配报文的源端口,--sport表示source-port,即表示源端口.
扩展匹配条件是可以取反的,同样是使用“!“进行取反,比如 ! --dport 22,表示目标端口不是22的报文将会被匹配到.
--sport,--dsport,都能够指定一个端口范围,比如,--dport 22:25表示目标端口为22到25之间的所有端口.
同时指定多个离散的端口,需要借助另一个扩展模块,multiport模块
2.2.5.2 匹配多个离散的端口
- 使用
multiport模块的--sports扩展条件同时指定多个离散的源端口.iptables -t filter -I INPUT -s 192.168.1.111 -p tcp -m multiport --dports 22,36,80 -j DROP - 使用
multiport模块的--dports扩展条件同时指定多个离散的目标端口iptables -t filter -I INPUT -s 192.168.1.111 -p tcp -m multiport --sports 22,36,80 -j DROP
2.2.5.3 iprange扩展模块
使用-s选项或者-d选项即可匹配报文的源地址与目标地址,而且在指定IP地址时,可以同时指定多个IP地址,每个IP用“逗号“隔开,但是,-s选项与-d选项并不能一次性的指定一段连续的IP地址范围,
如果我们需要指定一段连续的IP地址范围,可以使用iprange扩展模块,扩展匹配条件可以使用--src-range,--dst-range
iptables -t filter -I INPUT -m iprange --src-range 192.168.1.111-192.168.1.120 -j DROP
iptables -t filter -I INPUT -m iprange --dst-range 192.168.1.111-192.168.1.120 -j DROP
2.2.5.4 string扩展模块
使用string扩展模块,可以指定要匹配的字符串,如果报文中包含对应的字符串,则符合匹配条件
--algo:用于指定匹配算法,可选的算法有bm与kmp,此选项为必须选项,我们不用纠结于选择哪个算法,但是我们必须指定一个.
--string:用于指定需要匹配的字符串.
2.2.5.5 time扩展模块
我们可以通过time扩展模块,根据时间段区匹配报文,如果报文到达的时间在指定的时间范围以内,则符合匹配条件.
--timestart指定起始时间. 格式 xx.xx.xx
--timestop指定结束时间.
--monthdays 指定月份的哪一号,多个用,隔开
--weekdays 指定星期几,多个用,隔开 Mon, Tue, Wed, Thu, Fri, Sat, Sun
--datestart 指定日期开始时间
--datestop指定日期结束时间
NOTE: --monthdays与--weekdays可以使用"!"取反,其他选项不能取反
2.2.5.6 connlimit扩展模块
使用connlimit扩展模块,可以限制每个IP地址同时链接到server端的链接数量
注意:我们不用指定IP,其默认就是针对“每个客户端IP“,即对单IP的并发连接数限制.
--connlimit-above 2表示限制每个IP的链接数量上限为2
--connlimit-upto含义与! --commlimit-above的含义相同,即链接数量未达到指定的连接数量之意“–
--connlimit-mask限制“某类网段“的链接数量.connlimit-mask 24表示某个C类网段,没错,mask为掩码之意,所以将24转换成点分十进制就表示255.255.255.0
2.2.5.7 limit扩展模块
limit模块是对“报文到达速率“进行限制的. 限制单位时间内流入的包的数量.
--limit可以以秒为单位进行限制,也可以以分钟、小时、天作为单位进行限制.
可以选择的时间单位/second,/minute,/hour,/day
--limit-burst可以指定“空闲时可放行的包的数量“
2.2.5.8 扩展条件之-tcp-flags
注:需要对tcp协议的基础知识有一定的了解,比如:tcp头的结构、tcp三次握手的过程.
见名知义,“–tcp-flags“指的就是tcp头中的标志位,看来,在使用iptables时,我们可以通过此扩展匹配条件,去匹配tcp报文的头部的标识位,然后根据标识位的实际情况实现访问控制的功能.
如下图,在使用iptables时,使用tcp扩展模块的”–tcp-flags“选项,即可对上图中的标志位进行匹配,判断指定的标志位的值是否为“1“.
--tcp-flags tcp头的标志有SYN,ACK,FIN,RST,URG,PSH,默认ALL表示全部.
iptables -t filter -I INPUT -p tcp -m tcp --dport 22 --tcp-flags ALL SYNC -j REJECT
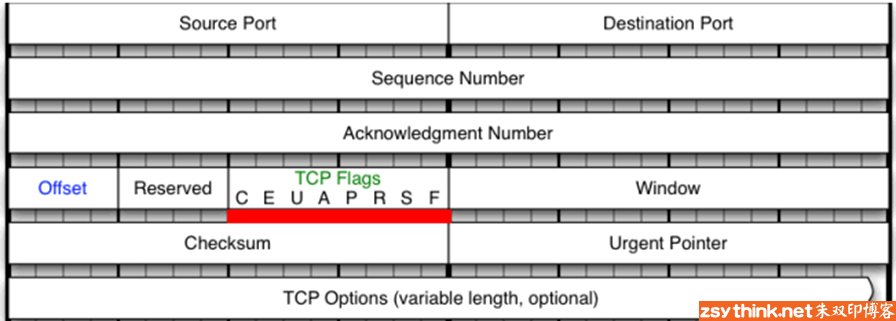
2.2.5.9 扩展模块之UDP扩展与ICMP扩展
-
UDP扩展
--sport与--dport,即匹配报文的源端口与目标端口.iptables -t filter -I INPUT -p udp -m udp --dport 136 0j ACCEPT -
ICMP扩展
--icmp-type选项表示根据具体的type与code去匹配对应的icmp报文.--icmp-type 8/0表示icmp报文的type为8,code为0才会被匹配到,也就是只有ping请求类型的报文才能被匹配到.iptables -t filter -I INPUT -p icmp -m icmp --icmp-type 8/0 -j REJECT iptables -t filter -I INPUT -p icmp --icmp-type 8 -j REJECT iptables -t filter -I OUTPUT -p icmp -m icmp --icmp-type 0/0 -j REJECT iptables -t filter -I OUTPUT -p icmp --icmp-type 0 -j REJECT iptables -t filter -I INPUT -p icmp --icmp-type "echo-request" -j REJECTsee icmp扩展
2.2.5.10 扩展模块之state扩展
state模块可以让iptables实现“连接追踪“机制.那么,既然是“连接追踪“,则必然要有“连接“.
state模块的连接而言,“连接“其中的报文可以分为5种状态:
- NEW:连接中的第一个包,状态就是NEW,我们可以理解为新连接的第一个包的状态为NEW.
- ESTABLISHED:我们可以把NEW状态包后面的包的状态理解为ESTABLISHED,表示连接已建立.
- RELATED:从字面上理解
RELATED译为关系,但是这样仍然不容易理解,我们举个例子. 比如FTP服务,FTP服务端会建立两个进程,一个命令进程,一个数据进程. 命令进程负责服务端与客户端之间的命令传输(我们可以把这个传输过程理解成state中所谓的一个“连接“,暂称为“命令连接“). 数据进程负责服务端与客户端之间的数据传输 ( 我们把这个过程暂称为“数据连接“ ). 但是具体传输哪些数据,是由命令去控制的,所以,“数据连接“中的报文与“命令连接“是有“关系“的. 那么,“数据连接“中的报文可能就是RELATED状态,因为这些报文与“命令连接“中的报文有关系. (注:如果想要对ftp进行连接追踪,需要单独加载对应的内核模块nf_conntrack_ftp,如果想要自动加载,可以配置/etc/sysconfig/iptables-config文件) - INVALID:如果一个包没有办法被识别,或者这个包没有任何状态,那么这个包的状态就是INVALID,我们可以主动屏蔽状态为INVALID的报文.
- UNTRACKED:报文的状态为untracked时,表示报文未被追踪,当报文的状态为Untracked时通常表示无法找到相关的连接.
iptables -t filter -I INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
2.3 黑白名单机制
白名单机制: 我们就要把所有人都当做坏人,只放行好人. 黑名单机制: 我们就要把所有人都当成好人,只拒绝坏人.
# 更改链的默认规则
# -P 选项
$ iptables -t filter -P INPUT DROP
2.4 自定义链
自定义链并不能直接使用,而是需要被默认链引用才能够使用
# 创建自定义链,
# -N
# 表示在filter表中增加一个NEW_CHAIN的链
# NOTE: 但是自定义链并未被引用
$ iptables -t filter -N NEW_CHAIN
# 引用
# NEW_CHAIN被INPUT链引用.
# 表明所有目的端口为80的报文由NEW_CHAIN去匹配
$ iptables -I INPUT -p tcp --dport 80 -j NEW_CHAIN
# 重命名自定义链
# -E 可以修改自定义链名
iptables -t filter -E NEW_CHAIN MY_CHAIN
# 删除自定义链
# -X 删除对应的自定义链
# 首先得删除引用,使自定义链引用为0,
# 其次清空自定义链规则
# 最后删除自定义链
$ iptables -t filter -D INPUT 1
$ iptables -t filter -F MY_CHAIN
$ iptables -t filter -X MY_CHAIN
2.5 网络防火墙
防火墙从逻辑上讲, 可以分为主机防火墙与网络防火墙。
主机防火墙:针对于单个主机进行防护。 网络防火墙: 往往处于网络入口或边缘, 针对于网络入口进行防护, 服务于防火墙背后的本地局域网。
#如果想要iptables作为网络防火墙,iptables所在主机开启核心转发功能,以便能够转发报文.
#使用如下命令查看当前主机是否已经开启了核心转发,0表示为开启,1表示已开启
cat /proc/sys/net/ipv4/ip_forward
#使用如下两种方法均可临时开启核心转发,立即生效,但是重启网络配置后会失效.
方法一:echo 1 > /proc/sys/net/ipv4/ip_forward
方法二:sysctl -w net.ipv4.ip_forward=1
#使用如下方法开启核心转发功能,重启网络服务后永久生效.
配置/etc/sysctl.conf文件(centos7中配置/usr/lib/sysctl.d/00-system.conf文件),在配置文件中将 net.ipv4.ip_forward设置为1
#由于iptables此时的角色为"网络防火墙",所以需要在filter表中的FORWARD链中设置规则.
#可以使用"白名单机制",先添加一条默认拒绝的规则,然后再为需要放行的报文设置规则.
#配置规则时需要考虑"方向问题",针对请求报文与回应报文,考虑报文的源地址与目标地址,源端口与目标端口等.
#示例为允许网络内主机访问网络外主机的web服务与sshd服务.
iptables -A FORWARD -j REJECT
iptables -I FORWARD -s 10.1.0.0/16 -p tcp --dport 80 -j ACCEPT
iptables -I FORWARD -d 10.1.0.0/16 -p tcp --sport 80 -j ACCEPT
iptables -I FORWARD -s 10.1.0.0/16 -p tcp --dport 22 -j ACCEPT
iptables -I FORWARD -d 10.1.0.0/16 -p tcp --sport 22 -j ACCEPT
#可以使用state扩展模块,对上述规则进行优化,使用如下配置可以省略许多"回应报文放行规则".
iptables -A FORWARD -j REJECT
iptables -I FORWARD -s 10.1.0.0/16 -p tcp --dport 80 -j ACCEPT
iptables -I FORWARD -s 10.1.0.0/16 -p tcp --dport 22 -j ACCEPT
iptables -I FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
2.6 动作
“动作“与“匹配条件“一样,也有“基础“与“扩展“之分,使用扩展动作也需要借助扩展模块,但是,扩展动作可以直接使用,不用像使用“扩展匹配条件“那样指定特定的模块.
ACCEPT与DROP都属于基础动作,而REJECT则属于扩展动作.
2.6.1 动作REJECT
动作也有自己的选项,以下以REJECT为例.
iptables -I INPUT 2 -j REJECT --reject-with icmp-host-unreachable
REJECT动作的常用选项为--reject-with,设置提示信息
- icmp-port-unreachable(不设置任何值时,默认此值)
- icmp-net-unreachable
- icmp-host-unreachable
- icmp-proto-unreachable
- icmp-net-prohibited
- icmp-host-pro-hibited
- icmp-admin-prohibited
2.6.2 动作LOG
使用LOG动作,可以将符合条件的报文的相关信息记录到日志中,但当前报文具体是被“接受“,还是被“拒绝“,都由后面的规则控制,
换句话说,LOG动作只负责记录匹配到的报文的相关信息,不负责对报文的其他处理,如果想要对报文进行进一步的处理,可以在之后设置具体规则,进行进一步的处理
iptables -I INPUT -p tcp --dport 22 -j LOG
可以查看/var/log/messages
也可以将相关信息记录在指定的文件中,以防止iptables的相关信息与其他日志信息相混淆,修改/etc/rsyslog.conf文件(或者/etc/syslog.conf),
在rsyslog配置文件中添加如下配置即可.
#报文相关信息会记录在 /var/log/iptables.log文
$ vim /etc/rsyslog.conf
kern.warning /var/log/iptables.log
# 服务重启生效
$ service rsyslog restart
LOG动作也有自己的选项,常用选项如下
--log-level选项可以指定记录日志的日志级别,可用级别有emerg,alert,crit,error,warning,notice,info,debug.
--log-prefix选项可以给记录到的相关信息添加“标签“之类的信息,以便区分各种记录到的报文信息,方便在分析时进行过滤.
注:--log-prefix对应的值不能超过29个字符.
2.6.3 动作SNAT
echo 1 > /proc/sys/net/ipv4/ip_forward开始核心转发
iptables -t nat -A POSTROUTING -s 10.1.0.0/16 -j SNAT --to-source 192.168.1.146
意思是将来自于10.1.0.0/16网段的报文的源地址改为公司的公网IP地址.
2.6.4 动作DNAT
iptables -t -I PREROUTING -d 192.168.1.146 -p tcp --dport 3389 -j DNAT --to-destination10.1.0.6:3389
意思是当外网主机访问公司公网IP的3389时,其报文的目标地址与端口将会被映射到10.1.0.6:3389上.
2.6.5 动作MASQUERADE
MASQUERADE会动态的将源地址转换为可用的IP地址,其实与SNAT实现的功能完全一致,都是修改源地址,只不过SNAT需要指明将报文的源地址改为哪个IP,而MASQUERADE则不用指定明确的IP,会动态的将报文的源地址修改为指定网卡上可用的IP地址.
iptables -t nat - POSTROUTING -s 10.1.0.0/16 -o eno50332184 -j MQSQUERADE
表示通过外网网卡出去的报文在经过POSTROUTING链时,会自动将报文的源地址修改为外网网卡上可用的IP地址,这时,即使外网网卡中的公网IP地址发生了改变,也能够正常的、动态的将内部主机的报文的源IP映射为对应的公网IP.
2.6.6 动作REDIRECT
使用REDIRECT动作可以在本机上进行端口映射 比如,将本机的80端口映射到本机的8080端口上
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
经过上述规则映射后,当别的机器访问本机的80端口时,报文会被重定向到本机的8080端口上.
NOTE: REDIRECT规则只能定义在PREROUTING链或者OUTPUT链中.
2.7 总结
1. 规则的顺序非常重要.
如果报文已经被前面的规则匹配到,IPTABLES则会对报文执行对应的动作,通常是ACCEPT或者REJECT,报文被放行或拒绝以后,即使后面的规则也能匹配到刚才放行或拒绝的报文,也没有机会再对报文执行相应的动作了(前面规则的动作为LOG时除外),所以,针对相同服务的规则,更严格的规则应该放在前面.
2. 当规则中有多个匹配条件时,条件之间默认存在“与“的关系.
如果一条规则中包含了多个匹配条件,那么报文必须同时满足这个规则中的所有匹配条件,报文才能被这条规则匹配到.
3. 在不考虑1的情况下,应该将更容易且经常被匹配到的规则放置在前面.
比如,你写了两条规则,一条针对sshd服务,一条针对web服务. 假设,一天之内,有20000个请求访问web服务,有200个请求访问sshd服务, 那么,应该将针对web服务的规则放在前面,针对sshd的规则放在后面,因为访问web服务的请求频率更高. 如果将sshd的规则放在前面,当报文是访问web服务时,sshd的规则也要白白的验证一遍,由于访问web服务的频率更高,白白耗费的资源就更多. 如果web服务的规则放在前面,由于访问web服务的频率更高,所以无用功会比较少. 换句话说就是,在没有顺序要求的情况下,不同类别的规则,被匹配次数多的、匹配频率高的规则应该放在前面.
4. 当IPTABLES所在主机作为网络防火 墙时,在配置规则时,应着重考虑方向性,双向都要考虑,从外到内,从内到外.
5. 在配置IPTABLES白名单时,往往会将链的默认策略设置为ACCEPT,通过在链的最后设置REJECT规则实现白名单机制,而不是将链的默认策略设置为DROP,如果将链的默认策略设置为DROP,当链中的规则被清空时,管理员的请求也将会被DROP掉.
netcat
nc全名叫 netcat, 它可以用来完成很多的网络功能, 譬如端口扫描、建立TCP/UDP连接, 数据传输、网络调试等等, 因此, 它也常被称为网络工具的 瑞士军刀 .
使用方式
$ nc -h
OpenBSD netcat (Debian patchlevel 1.187-1ubuntu0.1)
usage: nc [-46CDdFhklNnrStUuvZz] [-I length] [-i interval] [-M ttl]
[-m minttl] [-O length] [-P proxy_username] [-p source_port]
[-q seconds] [-s source] [-T keyword] [-V rtable] [-W recvlimit] [-w timeout]
[-X proxy_protocol] [-x proxy_address[:port]] [destination] [port]
- -4:只使用 IPv4 地址
- -6:只使用 IPv6 地址
- -l:启动本地监听
- -n:不使用 DNS 解析
- -p:指定源端口
- -s:指定源 IP 地址
- -u:使用 UDP, 默认是 TCP
- -v:显示详细信息
- -w:设定超时时间(只适合用在 Client 端)
- -d:禁止从标准输入读取数据, 也就是客户端输入数据不会发送到服务端
- -k:让服务端保持连接, 不断开
建立本地会话
# 模拟server端
# -v :输出详细信息
# -l :指定监听地址和端口
$ nc -v -l 127.0.0.1 6000
# 模拟client端
# -p : 指定源端口
$ nc -v -p 5000 localhost 6000
发送文件
假设服务端有一个 out.txt 的空文件, 而客户端有一个in.txt 文件, 含有数据:hello server.
# Server 端接收文件
$ nc localhost 6000 > out.txt
# Client 端发送文件
nc localhost 6000 < in.txt
支持UDP和IPv6连接
# server端
$ nc -u -6 -l localhost 6000
# client 端
$ nc -u -6 localhost 6000
端口扫描
# 扫描 192.168.1.3 上 1-100 端口区间, 有哪些端口是开放的
$ nc -vz 192.168.0.117 1-100
如果我们想扫描多个服务器上的多个端口是否开放, 可以写一个脚本来完成
netstat
Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具, 它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据, 一般用于检验本机各端口的网络连接情况。
1. 输出信息描述
$ netstat
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 k8sdev.sui:sun-sr-https k8sdev.suiyi.com.:34880 SYN_RECV
tcp 0 0 k8sdev.suiyi.com.c:2379 10.1.62.21:47910 ESTABLISHED
tcp 0 0 k8sdev.suiyi.com.c:2379 k8sdev.suiyi.com.:37790 ESTABLISH
...
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 3 [ ] DGRAM 18442 /run/systemd/notify
unix 2 [ ] DGRAM 18444 /run/systemd/cgroups-agen
1、Active Internet connections 有源TCP连接, 其中“Recv-Q“和“Send-Q“指接收队列和发送队列。
这些数字一般都应该是0。如果不是则表示软件包正在队列中堆积。这种情况只能在非常少的情况见到。
2、Active UNIX domain sockets 有源Unix域套接口(和网络套接字一样, 但是只能用于本机通信, 性能可以提高一倍)。
列名解释:
Proto:显示连接使用的协议。RefCnt:表示连接到本套接口上的进程号。Types:显示套接口的类型。State:显示套接口当前的状态。Path:表示连接到套接口的其它进程使用的路径名。
2. 常见参数
-a(all) 显示所有选项, 默认不显示LISTEN相关。-t(tcp) 仅显示tcp相关选项。-u(udp) 仅显示udp相关选项。-n拒绝显示别名, 能显示数字的全部转化成数字。-l仅列出有在 Listen (监听) 的服务状态。
-p显示建立相关链接的程序名-r显示路由信息, 路由表-e显示扩展信息, 例如uid等-s按各个协议进行统计-c每隔一个固定时间, 执行该netstat命令。NOTE: LISTEN和LISTENING的状态只有用
-a或者-l才能看到.
tcpdump
参考:
tcpdump 是一款 Linux 平台的抓包工具。它可以抓取涵盖整个 TCP/IP 协议族的数据包, 支持针对网络层、协议、主机、端口的过滤, 并提供 and、or、not 等逻辑语句来过滤无用的信息。
1. tcpdump命令选项
root@swift:~# tcpdump -h
tcpdump version 4.9.3
libpcap version 1.8.1
OpenSSL 1.1.1 11 Sep 2018
Usage: tcpdump [-aAbdDefhHIJKlLnNOpqStuUvxX#] [ -B size ] [ -c count ]
[ -C file_size ] [ -E algo:secret ] [ -F file ] [ -G seconds ]
[ -i interface ] [ -j tstamptype ] [ -M secret ] [ --number ]
[ -Q in|out|inout ]
[ -r file ] [ -s snaplen ] [ --time-stamp-precision precision ]
[ --immediate-mode ] [ -T type ] [ --version ] [ -V file ]
[ -w file ] [ -W filecount ] [ -y datalinktype ] [ -z postrotate-command ]
[ -Z user ] [ expression ]
-A只使用 ASCII 打印报文的全部数据, 不要和-X一起使用, 获取 http 可以用tcpdump -nSA port 80-b在数据链路层上选择协议, 包括 ip, arp, rarp, ipx 等-c指定要抓取包的数量-D列出操作系统所有可以用于抓包的接口-e输出链路层报头-i指定监听的网卡,-i any显示所有网卡-n表示不解析主机名, 直接用 IP 显示, 默认是用 hostname 显示-nn表示不解析主机名和端口, 直接用端口号显示, 默认显示是端口号对应的服务名-p关闭接口的混杂模式-P指定抓取的包是流入的包还是流出的, 可以指定参数in,out,inout等, 默认是inout-q快速打印输出, 即只输出少量的协议相关信息-s len设置要抓取数据包长度为 len, 默认只会截取前 96bytes 的内容,-s 0的话, 会截取全部内容。-S将 TCP 的序列号以绝对值形式输出, 而不是相对值-t不要打印时间戳-vv输出详细信息(比如 tos、ttl、checksum等)-X同时用hex 和 ascii 显示报文内容-XX同 -X, 但同时显示以太网头部
2. 过滤器
tcpdump 提供了灵活的语法可以精确获取我们关心的数据, 这些语法说得专业点就是过滤器。
过滤器简单可分为三类:协议(proto),传输方向(dir)和类型(type)。

proto:可选有 **ip, arp, rarp, tcp, udp, icmp, ether **等, 默认是所有协议的包dir:可选有 src, dst, src or dst, src and dst, 默认为 src or dsttype:可选有 host, net, port, portrange(端口范围, 比如 21-42), 默认为 host
3.tcpdump输出保存成文件
tcpdump 提供了将抓取的数据保存到文件的功能, 查看文件就方便分析多了, 而且还能与其他图形工具一起配合分析, 比如 wireshark、Snort 等。.pcap 格式的文件需要用 wireshark、Snort 等工具查看, 使用 vim 或 cat 会出现乱码。
-w选项表示把数据报文输出到文件
$ tcpdump -w capture_file.pcap port 80 # 把所有 80 端口的数据导出到文件
-r选项表示读取文件里的数据报文, 显示到屏幕上
$ tcpdump -nXr capture_file.pcap host host1
tcpdump的输出格式
系统时间 源主机.端口 > 目标主机.端口 数据包参数
jq详解
官方文档: jq
1. 基本过滤
-
Identity:
.这是个标识符, -
Object Identifier-Index:
.foo,.foo.bar, 如果key包含特殊字符,要用双引号包裹 -
Optional Object Identifier-Index:
.foo?, 同.foo,当不是数组或对象时忽略错误 -
Generic Object Index:
.[<string>], 查找字段.["foo"],(.foo是简写版) -
Array Index:
.[<value>] -
Array/String Slice:
.[10:15], 索引10~15的切片 -
Array/Object Value Iterator:
.[], 返回整个数组 -
.[]?同.[],当不是数组或对象时忽略错误 -
Comma:
,, 两个同时过滤用逗号分隔,将按顺序获得输出 -
Pipe:
|, 结合两个过滤. -
Parenthesis:
()
2. 类型和值
shell 语法
1. 注释
# 这是一个单行注释
:<<EOF
这是多行注释
这是多行注释
这是多行注释
EOF
:<<'
这是多行注释
这是多行注释
这是多行注释
'
:<<!
这是多行注释
这是多行注释
这是多行注释
!
2. 变量
定义变量时,变量名不加美元符号,**NOTE: 变量名和等号之间不能有空格.**使用时变量前加美元符号.可加{}分离边界
your_name="tom"
echo $your_name
myUrl="https://www.google.com"
readonly myUrl # 只读变量
unset variable_name # 删除变量
3. 字符串
字符串可用单引号或双引号,也可不用引号.
单引号限制:
- 单引号里的任何字符都会原样输出, 单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行), 但可成对出现, 作为字符串拼接使用。
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
str='this is a string'
str="Hello, I know you are \"$your_name\"! \n"
echo ${#str} # 获取字符串长度
echo ${str:1:4} 提取子字符串
echo `expr index $str io` # 查找子字符串
4. 数组
bash支持一维数组(不支持多维数组), 并且没有限定数组的大小。
array_name=(value0 value1 value2 value3)
echo array_name[0]
echo array_name[@] #获取所有元素
length=${#array_name[@]} # 取得数组元素的个数
length=${#array_name[*]} # 取得数组元素的个数
lengthn=${#array_name[n]} # 取得数组单个元素的长度
5. 传递参数
执行 Shell 脚本时, 向脚本传递参数, 脚本内获取参数的格式为:$n。n 代表一个数字
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数。 如“$*“用「”」括起来的情况、以“$1 $2 … $n“的形式输出所有参数。 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
| $@ | 与$*相同, 但是使用时加引号, 并在引号中返回每个参数。 如“$@“用「”」括起来的情况、以“$1“ “$2” … “$n” 的形式输出所有参数。 |
| $- | 显示Shell使用的当前选项, 与set命令功能相同。 |
| $? | 显示最后命令的退出状态。0表示没有错误, 其他任何值表明有错误。 |
$* 与 $@ 区别:
- 相同点:都是引用所有参数。
- 不同点:只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3, , 则 “ * “ 等价于 “1 2 3”(传递了一个参数), 而 “@” 等价于 “1” “2” “3”(传递了三个参数)。
6. 运算符
Shell 和其他编程语言一样, 支持多种运算符, 包括:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
a. 算术运算符
原生bash不支持简单的数学运算, 但是可以通过其他命令来实现, 例如 awk 和 expr, expr 最常用。
两点注意:
- 表达式和运算符之间要有空格, 例如 2+2 是不对的, 必须写成 2 + 2, 这与我们熟悉的大多数编程语言不一样。
- 完整的表达式要被 **`` ** 包含, 注意这个字符不是常用的单引号, 在 Esc 键下边。
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为 30。 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 将把变量 b 的值赋给 a。 |
| == | 相等。用于比较两个数字, 相同则返回 true。 | [ $a == $b ] 返回 false。 |
| != | 不相等。用于比较两个数字, 不相同则返回 true。 | [ $a != $b ] 返回 true。 |
**注意:**条件表达式要放在方括号之间, 并且要有空格, 例如: [$a==$b] 是错误的, 必须写成 [ $a == $b ]。
b. 关系运算符
关系运算符只支持数字, 不支持字符串, 除非字符串的值是数字。
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等, 相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等, 不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的, 如果是, 则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的, 如果是, 则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的, 如果是, 则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的, 如果是, 则返回 true。 | [ $a -le $b ] 返回 true。 |
c. 布尔运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算, 表达式为 true 则返回 false, 否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算, 有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算, 两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
d. 逻辑运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
e. 字符串运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等, 相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等, 不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0, 为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否不为 0, 不为 0 返回 true。 | [ -n “$a” ] 返回 true。 |
| $ | 检测字符串是否为空, 不为空返回 true。 | [ $a ] 返回 true。 |
f. 文件测试运算符
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件, 如果是, 则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件, 如果是, 则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录, 如果是, 则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录, 也不是设备文件), 如果是, 则返回 true。 | [ -f $file ] 返回 true。 |
| -g file | 检测文件是否设置了 SGID 位, 如果是, 则返回 true。 | [ -g $file ] 返回 false。 |
| -k file | 检测文件是否设置了粘着位(Sticky Bit), 如果是, 则返回 true。 | [ -k $file ] 返回 false。 |
| -p file | 检测文件是否是有名管道, 如果是, 则返回 true。 | [ -p $file ] 返回 false。 |
| -u file | 检测文件是否设置了 SUID 位, 如果是, 则返回 true。 | [ -u $file ] 返回 false。 |
| -r file | 检测文件是否可读, 如果是, 则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写, 如果是, 则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行, 如果是, 则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于0), 不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在, 如果是, 则返回 true。 | [ -e $file ] 返回 true。 |
其他检查符:
- -S: 判断某文件是否 socket。
- -L: 检测文件是否存在并且是一个符号链接。
7. 流程控制
流程控制可用break和continue 控制循环
# if 语句
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
# for 循环
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
# 或
for var in item1 item2 ... itemN; do command1; command2… done;
# while 循环
while condition
do
command
done
# 无限循环
while :
do
command
done
# 或
while true
do
command
done
# 或
for (( ; ; ))
# until 循环
until condition
do
command
done
# case 多选择语句
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
8. 函数
-
函数返回值在调用该函数后通过
$?来获得 -
调用函数时可以向其传递参数。在函数体内部, 通过 $n 的形式来获取参数的值, 例如, $1表示第一个参数, $2表示第二个参数
| 参数处理 | 说明 |
|---|---|
| $# | 传递到脚本或函数的参数个数 |
| $* | 以一个单字符串显示所有向脚本传递的参数 |
| $$ | 脚本运行的当前进程ID号 |
| $! | 后台运行的最后一个进程的ID号 |
| $@ | 与$*相同, 但是使用时加引号, 并在引号中返回每个参数。 |
| $- | 显示Shell使用的当前选项, 与set命令功能相同。 |
| $? | 显示最后命令的退出状态。0表示没有错误, 其他任何值表明有错误 |
[ function ] funname [()] {
action;
[return int;]
}
9. 输入输出重定向
如果希望执行某个命令, 但又不希望在屏幕上显示输出结果, 那么可以将输出重定向到 /dev/null
如果希望屏蔽 stdout 和 stderr,可以这么写command > /dev/null 2>&1.
**注意:**0 是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR.)这里的 2 和 > 之间不可以有空格, 2> 是一体的时候才表示错误输出。
| 命令 | 说明 |
|---|---|
| command > file | 将输出重定向到 file。 |
| command < file | 将输入重定向到 file。 |
| command >> file | 将输出以追加的方式重定向到 file。 |
| n > file | 将文件描述符为 n 的文件重定向到 file。 |
| n >> file | 将文件描述符为 n 的文件以追加的方式重定向到 file。 |
| n >& m | 将输出文件 m 和 n 合并。 |
| n <& m | 将输入文件 m 和 n 合并。 |
| << tag | 将开始标记 tag 和结束标记 tag 之间的内容作为输入。 |
需要注意的是文件描述符 0 通常是标准输入(STDIN), 1 是标准输出(STDOUT), 2 是标准错误输出(STDERR)。
10. 文件包含
. filename # 注意点号(.)和文件名中间有一空格
或
source filename
# 例
#使用 . 号来引用test1.sh 文件
. ./test1.sh
# 或者使用以下包含文件代码
# source ./test1.sh
cron语法
一. linux下的表达式
|───────────── minute (0 - 59)
| |──────────── hour (0 - 23)
| | |─────────── day of month (1 - 31)
| | | |────────── month (1 - 12)
| | | | |──────── day of week (0 - 6) (Sunday to Saturday; 7 is also Sunday)
| | | | |
| | | | |
* * * * * command to execute
二. 表达式详解
| Field | Required | Allowed values | Allowed special characters | Remarks |
|---|---|---|---|---|
| Seconds | Optional | 0-59 | * , - / | - |
| Minutes | Yes | 0-59 | * , - / | - |
| Hours | Yes | 0-23 | * , - / | - |
| Day of month | Yes | 1-31 | * , - / ? L W | - |
| Month | Yes | 1-12 or JAN-DEC | * , - / | - |
| Day of week | Yes | 0-6 or SUN-SAT | * , - / ? L # | - |
| Year | Optional | 1970–2099 | * , - / | This field is not supported in standard |
Cron表达式在标准中,有5个字段, Year字段在不是标准支持,在Cron格式的某些使用中, 模式的开头还有一个秒字段。 在这种情况下, CRON表达式是一个包含6或7个字段的字符串。
-
Asterisk(
*): 星号表示cron表达式将匹配该字段的所有值. 在Month域中使用星号将表示每个月。 -
Comma(
,): 逗号用于分隔列表中的项. “MON,WED,FRI“在第(day of week)域中表示Mondays,Wednesdays and Fridays. -
Hyphen(
-): 连字符定义范围。例如,2000-2010表示2000年至2010年(包括2010年)的每一年。 -
Percent(
%) : 除非使用反斜杠(\)进行转义, 否则命令中的百分号(%)会更改为新行字符, 并且将第一个%之后的所有数据作为标准输入发送至命令。[10] -
非标准的字符
-
L: 代表“最后”,在
Day-of-week字段中使用时,它允许您指定诸如给定月份的“最后一个星期五”(“5L”)这样的结构。在“
Day-of-month”字段中, 它指定该月的最后一天。 -
W: 只在Day-of-month字段中允许使用W字符,此字符用于指定最接近给定日期的有效工作日(星期一至星期五)。例如, 如果您要指定“ 15W”作为
Day-of-month字段的值, 则含义是:“离月15日最近的工作日”。如果15号是星期六, 那么触发器将在14号星期五触发。
如果15日是星期日, 则触发器将在16日星期一触发。
如果15号是星期二, 那么它将在15号星期二触发。
但是, 如果您指定“ 1W”作为月份的值, 并且第一个是星期六, 则触发器将在第3个星期一触发, 因为它不会“跳过”一个月日的边界。 仅当月份中的某天是一天, 而不是范围或天数列表时, 才可以指定“ W”字符
-
Hash(
#): 只能在Day-of-week字段中允许使用#, 并且后面必须跟一个1到5之间的数字,它允许您指定诸如给定月份的“第二个星期五”这样的结构. 例如, 在Day-of-week字段中输入6#3表示每月的第三个星期五。 -
Question(
?): 在某些实现中,代替*来保留Day-of-month或Day-of-week域为空白. 其它某些的Cron实现用来匹配当时Cron的启动的时间, 例如,如果cron在上午8:25启动, 则? ? * * * *将更新为25 8 * * * *, 并且cron在每天的这个时间运行这个命令. -
Slash(
/): 可以将斜线与范围组合以指定步长值. 例如:Minutes字段中的*/5表示每5分钟显示一次.
-
三. 非标准的预定义调度定义
| Entry | Description | Equivalent to |
|---|---|---|
@yearly (or @annually) | Run once a year at midnight of 1 January | 0 0 1 1 * |
@monthly | Run once a month at midnight of the first day of the month | 0 0 1 * * |
@weekly | Run once a week at midnight on Sunday morning | 0 0 * * 0 |
@daily | Run once a day at midnight | 0 0 * * * |
@hourly | Run once an hour at the beginning of the hour | 0 * * * * |
@reboot | Run at startup | N/A |
yaml语法
格式数据类型
常量,对象,数据
格式要求
#表示注释- 大小写敏感
- 缩进表示层级关系
- 缩进只能使用空格,不能使用TAB,不要求空格个数,只需要相同层级左对齐,(2个或4个空格)
语法
对象
- 键值对:
key:value - 层级关系
key:
child-key: value
child-key2: value2
- 流式(flow)语法,上面可表示
key:{child-key: value, child-key2: value2}
- 复杂对象格式, 可使用问号加一个空格代表一个复杂的key, 配合一个冒号加一个空格代表一个值
?
- complexkey1
- complexkey2
:
- complexvalue1
- complexvalue2
数组
- 短横线加一个空格代表一个数组项
hobby:
- java
- go
-
- java
- go
# 理解为[[java,go]]
- 复杂
companies:
-
id: 1
name: company1
price: 200W
-
id: 2
name: company2
常量
- boolean
- TRUE,true,True均可以
- FALSE,false,False均可以
- float
- 3.14
- 6.8523015e+5 #可以使用科学计数法
- 整数
- 123
- 0b1010_0111_0100_1010_1110 #二进制表
- string
- 哈哈
- ‘Hello world’ #可以使用双引号或者单引号包裹特殊字符
- 字符串可以拆成多行, 每一行会被转化成一个空格
newline
newline2
- date
- 2018-07-17 #日期必须使用ISO 8601格式, 即yyyy-MM-dd
- datetime
- 2018-07-17T19:02:31+08:00 #时间使用ISO 8601格式, 时间和日期之间使用T连接, 最后使用+代表时区
Protobuf语法
一. 定义消息类型
.proto文件定义消息类型
syntax = "proto3";
// option go_package = ".;pb";
/* 查询请求*/
message SearchRequest {
reserved 4, 15, 9 to 11;
string query = 1; // 查询
int32 page_number = 2;
int32 result_per_page = 3;
}
message SearchResponse {
repeated Result results = 1;
}
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
-
第一行定义了使用的
protobuf的协议的版本,如果不设置,则为proto2版本. 文件第一行必须非空,非注释行 -
可选定义go的包名
-
采用C/C++风格的注释,即使
//和/**/. -
SearchRequest定义了三个域(名称/值对),每个字段都有一个名称和一个类型-
每个字段都有对应的标量类型( [scalar types](#二. 标量类型(scalar types)))
-
每一个字段都定有唯一数值编号. 这些字段用于标识二进制编码的域位置,一旦定义并使用后,不应该再修改.
-
字段数值编号1-15只使用一个字节进行编码,包括字段数值编号和字段类型.
-
字段数值编号16-2047将使用两个字节进行编码
-
最小的字段编号为1,最大2^29 - 1, or 536,870,911.
-
19000-19999 (FieldDescriptor::kFirstReservedNumber-FieldDescriptor::kLastReservedNumber)为
protobuf保留字段,不可使用.对于频繁出现的消息最好使用1-15,切记为将来可能添加的频繁出现的元素留出一些空间
-
-
字段规则
singular: 字段为0或1个,这是默认规则.repeated: 该字段可以在格式良好的消息中重复任意次数(包括0),重复值的顺序将保留. 在proto3中, 默认情况下, 标量数字类型的repeated字段使用打包编码
-
-
保留字段
reserved, 可以采用保留编号或保留字段名的方式,进行保留, 当删除一些旧的编号或字段时,可以防止后续使用,引起不必要的bug. -
可以使用其它消息类型作为字段. 如
Result在SearchResponse里使用 -
使用 protocol buffer compiler 编译将产生对应的代码
二. 标量类型(scalar types)
| .proto | Notes | C++ | Go | Dart |
|---|---|---|---|---|
double | double | float64 | double | |
float | float | float32 | double | |
int32 | 使用变长编码,负数编码效率低下,如果字段可能有负数,使用sint32 | int32 | int32 | int |
int64 | 使用变长编码,负数编码效率低下,如果字段可能有负数,使用sint64 | int64 | int64 | Int64 |
uint32 | 使用变长编码 | uint32 | uint32 | int |
uint64 | 使用变长编码 | uint64 | uint64 | Int64 |
sint32 | 使用变长编码。有符号的整型。它们比int32编码负数效率更高 | int32 | int32 | int |
sint64 | 使用变长编码。有符号的整型。它们比int64编码负数效率更高 | int64 | int64 | Int64 |
fixed32 | 固定4字节编码,如果值大于2^28比uint32编码效率更高 | uint32 | uint32 | int |
fixed64 | 固定8字节编码,如果值大于2^68比uint32编码效率更高 | uint64 | uint64 | Int64 |
sfixed32 | 固定4字节 | int32 | int32 | int |
sfixed64 | 固定8字节 | int64 | int64 | Int64 |
bool | bool | bool | bool | |
string | utf-8或ASCII编码,长度不应超过2^32 | string | string | String |
bytes | 包含任意的字节,长度不应超过2^32 | string | []byte | List |
三. 默认值
解析消息时, 如果编码的消息不包含特定的单数元素, 则已解析对象中的相应字段将设置为该字段的默认值。 这些默认值是特定于类型的:
- string: 空字符串
- bytes: 空字节流.
- bools: false.
- numeric types: 0
- enums: 枚举的第一个值,且必须为0.
- message fields: 取决于所用的语言(See generated code guide)
四. 枚举
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
option allow_alias = true;
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
AliasLocal = 3,
}
Corpus corpus = 4;
}
如您所见, Corpus枚举的第一个常量映射为零:每个枚举定义必须包含一个映射为零的常量作为其第一个元素。 这是因为:
- 必须有一个零值, 以便我们可以使用0作为数字默认值。
- 零值必须是第一个元素, 以便与
proto2语义兼容, 其中第一个枚举值始终是默认值。 - 您可以通过将相同的值分配给不同的枚举常量来定义别名. 首先你得设置
allow_alias为true - 枚举值的范围为32位整型,采用 varint encoding 编码,不建议采用负数.
五. 导入定义
import "myproject/other_protos.proto";
默认情况下, 您只能使用直接导入的.proto文件中的定义。 但是, 有时您可能需要将.proto文件移动到新位置。
现在, 您可以直接在原始位置放置一个虚拟的.proto文件, 而不是直接移动.proto文件并一次更改所有呼叫站点, 而是使用导入import public将所有导入转发到新位置。
任何导入包含导入import public的原型的人都可以可传递地依赖导入import public依赖项。 例如
// new.proto
// All definitions are moved here
// old.proto
// This is the proto that all clients are importing.
import public "new.proto";
import "other.proto";
// client.proto
import "old.proto";
// You use definitions from old.proto and new.proto, but not other.proto
协议编译器使用-I /-proto_path标志在协议编译器命令行中指定的一组目录中搜索导入的文件。
如果未给出任何标志, 它将在调用编译器的目录中查找。 通常, 应将--proto_path标志设置为项目的根目录, 并对所有导入使用完全限定的名称。
六. 其它内置类型定义
1. Any
Any消息类型使您可以将消息用作嵌入式类型, 而无需定义它们的.proto。
Any包含任意序列化消息(以字节为单位)以及URL, URL作为该消息的类型并解析为该消息的类型的全局唯一标识符。
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}
2. Oneof
如果您有一则消息包含许多字段, 并且最多可以同时设置一个字段, 则可以使用oneof功能强制执行此行为并节省内存。
可以添加任何字段到oneof,除了map和repeated
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}
3. Maps
如果要在数据定义中创建关联映射, 则协议缓冲区提供了方便的快捷方式语法:
map<key_type, value_type> map_field = N;
key_type可以是任何integral或string类型(除了float和bytes之外),enum不是有效的key_typevalue_type可以是除Maps以外的任何类型。
map<string, Project> projects = 3;
-
映射字段不能重复。
-
map值的编码顺序和迭代顺序是未定义的, 因此您不能依赖于map处于特定的顺序。
-
当为
.proto生成文本格式时, 地图将按键排序。 数字键按数字排序。 -
从数据解析或合并时, 如果存在重复的映射键, 则使用最后看到的键。 从文本格式解析时, 如果键重复, 则解析可能会失败。
-
如果为映射字段提供键但没有值, 则序列化字段时的行为取决于语言。 在C ++, Java和Python中, 类型的默认值是序列化的, 而在其他语言中, 则没有序列化的值。
七. 包定义
可以在.proto文件中添加可选的包说明符, 以防止协议消息类型之间的名称冲突。
package foo.bar;
message Open { ... }
在Go中, 除非您在.proto文件中明确提供了go_package选项, 否则该包将用作Go包名称
八. 定义服务
如果要将消息类型与RPC(远程过程调用)系统一起使用, 则可以在.proto文件中定义RPC服务接口, 并且协议protocolbuf编译器将以您选择的语言生成服务接口代码和存根。
例如, 如果要使用接收SearchRequest并返回SearchResponse的方法来定义RPC服务, 则可以在.proto文件中定义它, 如下所示:
service SearchService {
rpc Search(SearchRequest) returns (SearchResponse);
}
ansible 基本使用
ansible <host-pattern> [-m module_name] [-a args]
一. 架构和原理
二. 常用模块
1. command 默认
ansible <host-pattern> -a 'ls /'
2. shell
ansible <host-pattern> -m shell -a 'ls /'
3. script 在远程主机执行脚本
ansible <host-pattern> -m script -a 'path/xx.sh'
4. copy 复制文件到远程主机
ansible <host-pattern> -m copy -a 'src=path/srcfile dest=path/destfile backup=yes'
5. fetch 从远程主机取文件到本机
不支持,可以考虑目录可以先进行tar压缩
ansible <host-pattern> -m fetch -a 'src=path/srcfile dest=path/destfile'
6. file 设置文件/目录的属性
ansible <host-pattern> -m file -a 'name=path/file state=touch'
7. hostname 修改主机名
ansible <host-pattern> -m hostname -a 'name=newhostname'
8. cron 计划任务
ansible <host-pattern> -m cron -a 'minute=* job=""/usr/bin/wall fbi warn" name=warning'
9. apt ubuntu/debian包管理
ansible <host-pattern> -m apt -a 'name=dstat update_cache=yes upgrade=yes'
10. service 服务管理
ansible <host-pattern> -m service -a 'name=httpd enabled=yes state=[stated|stopped|reloaded|restarted]'
11. user 用户管理
ansible <host-pattern> -m user -a 'name=user1 comment="test user" uid=2048 home=/home/user1 group=root'
12. group 组管理
ansible <host-pattern> -m group -a "name=testgroup system=yes"
glob 匹配规则
- glob wiki
1. 语法
最常用的通配符是*, ?,和[...]
| Wildcard | Description | Example | Matches | Does not match |
|---|---|---|---|---|
* | 匹配任意数量的字符, 包括空 | Law* | Law, Laws, or Lawyer | GrokLaw, La, or aw |
*Law* | Law, GrokLaw, or Lawyer. | La, or aw | ||
? | 匹配单个字符 | ?at | Cat, cat, Bat or bat | at |
[abc] | 匹配括号内的字符 | [CB]at | Cat or Bat | cat, bat or CBat |
[a-z] | 匹配括号内给的字符范围 | Letter[0-9] | Letter0, Letter1, Letter2 up to Letter9 | Letters, Letter or Letter10 |
一般情况下, 路径分隔符(Linux/Unix, MacOS上的/或Windows的\)是从不匹配的,但是一些shell,比如Bash是允许用户规避此问题.
Unix-like
在 Unix-like 系统, 在[...]上有两个附加含义.
| Wildcard | Description | Example | Matches | Does not match |
|---|---|---|---|---|
[!abc] | 匹配不在括号内的字符 | [!C]at | Bat, bat, or cat | Cat |
[!a-z] | 匹配不在括号内给的字符范围 | Letter[!3-5] | Letter1, Letter2, Letter6 up to Letter9 and Letterx etc. | Letter3, Letter4, Letter5 or Letterxx |
Bash支持以下扩展:
**: 递归匹配
NATS
特性:
- Core NATS
- JetStream
优势:
- 边缘与云原生消息系统,
CNCF毕业项目, 社区活跃度高, 文档完善. golang编写, 服务端程序极小, 不到20M.- 支持客户端的语言非常多, 主流语言基本都支持.
- 支持内存级的
Core NATS, 有发布-订阅, 请求-回复(类似RPC), 队列组等功能 - 支持持久化的
JetStream, 在Core NATS之上提供消息持久化, 消息确认, 消息重试, 消息保序等机制, 另外还提供Key-Value存储, 对象存储功能.- 每一个
Stream独立提供丰富的配置 - 每一个
Stream的每一个Consumer独立提供丰富配置
- 每一个
- 支持安全的身份验证和授权访问机制, 支持TLS, JWT-based zero trust security
- 支持集群, 可以水平扩展, 提供高可用, 高并发的消息系统
- 协议层面支持 TCP, MQTT, WebSockets
1. Core NATS
1.1 Publish-Subscribe(发布-订阅)

1.2 Request-Reply(请求-回复)

1.3 QueueGroup(队列组)

2. JetStream
JetStream在Core NATS基本功能的基础上实现新的功能和更高的服务质量.
2.1 Streams
2.1.1 Replay policies(重放策略)
JetStream 消费者支持多种重放策略, 具体取决于消费应用程序是否希望接收策略:
- 存储在
stream中的所有消息, 可以完整重放, 也可以选择重放策略(即重放速度):instant: (以最快的速度向消费者发送消息).original: (这意味着消息将以发布到流中的速度传送给消费者, 这对于暂存生产流量非常有用. )
- 存储在
stream中的最后一条消息, 或每个主题的最后一条消息 (因为流可以捕获多个主题). - 从特定序列号开始.
- 从特定的开始时间开始.
2.1.2 Retention policies and limits(保留政策和限制)
2.1.2.1 Limits(限制)
你可以对stream施加以下限制:
- 最大消息年龄
stream的最大总大小(字节)stream的消息最大总数量- 单条消息的最大大小
- 还可以设置在任何给定时间点为
stream定义的消费者数量限制
您还必须选择一个丢弃策略, 该策略规定了一旦stream达到其限制之一并有新消息发布时应该发生的情况:
discard old: 表示stream将自动删除stream中最旧的消息, 为新消息腾出空间.discard new: 表示丢弃新消息 (JetStream 发布调用会返回错误消息, 表明已达到限制).
2.1.2.2 Retention policy(保留策略)
您可以为每个stream选择所需的保留策略:
limits: (默认)是提供流中消息的重播.work queue: 来提供stream中消息的只有一次的消费(消息流被用作共享队列, 消息被消费时会从队列中移除).interest: 是工作队列的一种变体, 它只保留对消息主题有兴趣 (流上当前定义的消费者)的消息. (只要有消费者尚未发送消息, 消息流中就会一直保留消息)
请注意, 无论选择哪种保留策略, Limits (和丢弃策略)始终生效.
2.1.3 Persistent and Consistent distributed storage(持久且一致的分布式存储)
您可以根据自己的需要选择消息存储的持久化和弹性.
Memory storage.File storage.Replication(1 (none), 2, 3) between nats servers for Fault Tolerance.
2.2 Consumers(消费者)
Core NATS提供最多一次的交付保证, 而JetStream的消费者则不同, 它可以提供至少一次的交付保证.
2.2.1 Dispatch type - Pull/Push(分发类型 - 拉模式/推模式)
push: 基于推送模式的, 即向指定主题发送消息pull: 基于拉模式的, 即允许客户按需请求批量消息
2.2.2 Ordered Consumers(有序消费者)
有序消费者是推/拉消费者的默认类型, 专为希望有效消费数据流以进行数据检查或分析的应用程序而设计.
- 总是短暂的
- 无确认(如果检测到间隙, 则重新创建消费者)
- 自动流量控制/拉动处理
- 单线程调度
- 无负载平衡
2.2.3 Persistence - Durable/Ephemeral(持久性 - 持久/短暂)
除了可以选择推式或拉式外, 消费者还可以是短暂的或持久的.
2.2.4 AckPolicy(应答策略)
策略选择包括:
AckExplicit: 默认策略. 每条报文都必须确认. 建议使用该策略以获得最高的可靠性和功能性.AckNone: 不需要确认;服务器假定在发送时确认.AckAll: 只确认系列中收到的最后一条信息;之前的所有信息都会自动确认. 将确认 Pull Consumer 所有订阅者的所有待确认信息.
如果需要确认, 但在AckWait窗口内未收到, 则会重新发送报文.
2.2.5 DeliverPolicy(分发策略)
策略选择包括:
DeliverAll: 默认策略. 从信息流中最早可用的信息开始接收.DeliverLast: 从流中添加的最后一条信息开始接收, 或从符合消费者筛选主题(如果已定义)的最后一条信息开始接收.DeliverLastPerSubject: 从当前信息流中每个过滤主题的最新信息开始接收.DeliverNew: 开始接收消费者创建后创建的信息.DeliverByStartSequence: 从具有指定序列号的第一条信息开始. 消费者必须指定定义序列号的OptStartSeq.DeliverByStartTime: 从指定时间或之后的信息开始接收. 消费者必须指定定义开始时间的OptStartTime.
2.2.6 MaxAckPending
MaxAckPending功能提供流量控制, 同时适用于推式和拉式消费者.
对于推送消费者, MaxAckPending是唯一的流量控制形式.
对于拉式消费者, 客户端驱动的消息传递会与订阅者建立隐式一对一流量控制.
为获得高吞吐量, 请将 MaxAckPending设置为较高值.对于因外部服务导致延迟较高的应用, 可使用较低的值并调整 AckWait 以避免重新交付.
2.2.7 FilterSubjects
过滤主题可在向客户端发送信息前对信息进行服务器端过滤.
3. JetStream例子
创建一个stream
nats stream add \
com_msg \ <-- stream名称
--subjects "com.msg.*" \ <-- 订阅的主题
--storage file \ <-- 存储类型, file/memory
--retention "work" \ <-- 保留策略, limits/interest/work
--discard old \ <-- 丢弃策略, old/new, 当消息达到限制数据后, 如何处理消息
--max-msgs -1 \ <-- 最大消息数量, -1 表示无限制
--max-msgs-per-subject -1 \ <-- 每个主题的最大消息数量, -1 表示无限制, 超过限制按丢弃策略处理
--max-bytes -1 \ <-- 所有消息总的最大大小, -1 表示无限制
--max-msg-size -1 \ <-- 单条消息的最大大小, -1 表示无限制
--max-ages 1y \ <-- 最大消息年龄, 超过限制按丢弃策略处理
--dupe-window 2m0s \ <-- 重复消息窗口, 根据Msg-Id的header头信息判断唯一消息的时间
--no-allow-rollup \ <-- 是否允许通过header卷起消息, --allow-rollup为允许
--deny-delete \ <-- 是否允许通过API删除消息, --no-deny-delete为允许
--deny-purge \ <-- 是否允许通过API清除消息, --no-deny-purge为允许
--replicas <-- 消息副本数, 集群使用
创建一个Consumer
nats consumer add \
com_msg \ <-- stream名称
com_msg_consumer \ <-- consumer名称
--filter-subject "com.msg.*" \ <-- 过滤stream中的主题
--deliver all \ <-- 如何处理stream中的消息, 见下表
--ack explicit \ <-- 消息确认方式, none/all/explicit
--replay instant \ <-- 消息重放机制, instant/original
--max-deliver -1 \ <-- 最大交付次数, -1 表示没有正确的ack就不停的投递消息
--max-pending 0 \ <-- 最多允许存在多少条未投递成功, 正在重新投递的消息, 如果达到这个数, 将不再投递新消息
--headers-only \ <-- 是否只投递header信息
--target "" <-- 推模式目标, 拉模式为空
Git
私有仓库访问
git config --global url."https://${username}:${token}@github.com".insteadof "https://github.com"
1. 配置
git config --global user.name "Your Name"
git config --global user.email "email@example.com"
[core]
# autocrlf
# windows 和linux 换行符差异,需要配置换行符
# windows 是CRLF
# linux/mac是LF
# 保存仓库永远为LF,在Windows工作空间都是CRLF, 在Mac/Linux工作空间都是LF.
# windows配置`autocrlf = true`, 提交时自动CRLF转LF, 检出时自动将LF转CRLF
# linux/mac配置`autocrlf = input`,提交时自动CRLF转LF, 检出时自动将保持LF.
# safecrlf
#拒绝提交包含混合换行符的文件
safecrlf=true
#允许提交包含混合换行符的文件
safecrlf=false
#提交包含混合换行符的文件时给出警告
safecrlf= warn
2. 暂存,提交,日志,状态
git add . # 提交所有到本地暂存区
git commit -m "消息" # 提交到本地仓库
git status # 查看当前仓库状态
git log # 查看提交日志
git diff #查看差异化
3. 版本回退,前进,指定到相关版本
git reset --hard HEAD^ # 回退到上一个版本
git reset --hard hash值 # 回退到指定版本
git reflog # 查看最近回退的版本
4. 远程仓库
git remote add origin https://github.com/thinkgos/learngit.git
git push -u origin master
5. 分支,代码冲突,合并,变基.
git branch # 列出分支
git checkout dev # 检出分支
git checkout -b 分支 # 加上-b表示检出分支
git merge dev # 合并dev分支到当前分支
6. 打标签
git tag # 列出所有标签
git tag v1.0.0 # 给当前分支打标签
git show v1.0.0 # 查看标签信息
git tag -d v0.9.0 # 删除某个标签
git push origin v1.0.0 #推送某个标签到远程
# 如果标签已经推到远程
# 先删除本地
git tag -d v0.9.0
# 再删除远程
git push origin :refs/tags/v0.9.0
- 子模块
# 增加子模块
git submodule add https://github.com/thinkgos/submodule.git libs/yoursubmodule
# 克隆含有子模块的项目,可通过增加 --recurse-submodules 来嵌入克隆子模块
git clone https://github.com/thinkgos/learngit.git
# 将子模块的项目克隆下来
git submodule update --init
# 拉取子模块最新的推送
git submodule update --remote yoursubmodule
# 可以设置指定的分支并更新所有子模块
git config -f .gitmodules submodule.DbConnector.branch stable
git submodule update --remote
# NOTE: git pull 命令会递归抓取子模块的更改,但不会更新子模块. 可以增加 --recurse-submodules
# 为了完成所有更新,需要运行
git submodule update --init --recursive
RSA密钥
DER和PEM编码
- DER: 基于二进制的编码。可以用CER或者CRT作为扩展名的的整数。比较合适的说法是“我有一个DER编码的证书”, 而不是“我有一个DER证书”
- PEM: 基于ASCII(Base64)的编码。OpenSSL 使用 PEM 文件格式存储证书和密钥。
PEM 实质上是 base64 编码的二进制内容, 再进行增加或裁剪特殊字符-、n、r、begin信息、end信息,如:
-----BEGIN CERTIFICATE-----
内容
-----END CERTIFICATE-----
PCKS(The Public-Key Cryptography Standards)
PKCS由美国RSA公司及其合作伙伴制定的一组公钥密码学标准, 其中包括证书申请、证书更新、证书作废表发布、扩展证书内容以及数字签名、数字信封的格式等方面的一系列相关协议。
版本:现有PCKS1, PCKS3, PCKS5, PKCS6, PKCS7, PKCS8, PKCS9, PKCS10, PKCS11, PKCS12, PKCS13, PKCS14, PKCS15 等13个版本
常用:PCKS1 和 PCKS8, 本文使用 PCKS8 标准
注:由于PKCS内容规范设计二进制, 不方便使用, 所以一般转成base64 后, 用 pem 格式规范显示
- pcks1的pem格式头
//公钥
-----BEGIN RSA PUBLIC KEY-----
内容
-----END RSA PUBLIC KEY-----
//私钥
-----BEGIN RSA PRIVATE KEY-----
内容
-----END RSA PRIVATE KEY-----
- pcks8的pem格式头
//公钥
-----BEGIN PUBLIC KEY-----
内容
-----END PUBLIC KEY-----
//私钥
-----BEGIN PRIVATE KEY-----
内容
-----END PRIVATE KEY-----
install ubuntu
修改软件源
图形修改
系统设置 -> 软件和更新 选择下载服务器 -> “mirrors.aliyun.com”
手动修改
/etc/apt/sources.list
替换默认的http://archive.ubuntu.com/为http://mirrors.aliyun.com/
ubuntu22.04为以下配置
deb https://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
# deb https://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe multiverse
# deb-src https://mirrors.aliyun.com/ubuntu/ jammy-proposed main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
安装基础软件
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install vim zsh git curl jq gcc make cmake tmux gcc12
配置git
git config --global user.name ""
git config --global user.email ""
.gitconfig
[user]
name = example
email = example@example.com
[core]
# autocrlf
# windows 和linux 换行符差异,需要配置换行符
# windows 是CRLF
# linux/mac是LF
# 保存仓库永远为LF,在Windows工作空间都是CRLF, 在Mac/Linux工作空间都是LF.
# windows配置`autocrlf = true`, 提交时自动CRLF转LF, 检出时自动将LF转CRLF
# linux/mac配置`autocrlf = input`,提交时自动CRLF转LF, 检出时自动将保持LF.
# safecrlf
#拒绝提交包含混合换行符的文件
safecrlf=true
#允许提交包含混合换行符的文件
safecrlf=false
#提交包含混合换行符的文件时给出警告
safecrlf= warn
autocrlf = input
pager = delta
editor = vim
[interactive]
diffFilter = delta --color-only
[add.interactive]
useBuiltin = false # required for git 2.37.0
[delta]
navigate = true # use n and N to move between diff sections
light = false # set to true if you're in a terminal w/ a light background color (e.g. the default macOS terminal)
side-by-side = true
[merge]
conflictstyle = diff3
[diff]
colorMoved = default
.gitmessage
# head: <type>(<scope>): <subject>
# - type: feat, fix, doc, perf, style, refactor, test, chore, security, revert
# - scope: can be empty (eg. if the change is a global or difficult to assign to a single component)
# - subject: start with verb (such as 'change'), 50-character line
#
# body: 72-character wrapped. This should answer:
# * Why was this change necessary?
# * How does it address the problem?
# * Are there any side effects?
#
# footer:
# - Include a link to the ticket, if any.
# - BREAKING CHANGE
安装输入法
sudo apt update
sudo apt install fcitx5 fcitx5-chinese-addons fcitx-config-gtk
配置/etc/environment中增加以下配置, 解决浏览器等软件无法使用的问题.
GTK_IM_MODULE=fcitx
QT_IM_MODULE=fcitx
XMODIFIERS=@im=fcitx
SDL_IM_MODULE=fcitx
GLFW_IM_MODULE=ibus
配置 语言支持 为 fcitx5
安装gnome-tweaks
sudo apt install gnome-tweaks
安装gnome-shell-extensions
sudo apt install gnome-shell-extensions
zsh配置
设置zsh为默认
# 设置默认shell, 需要重启
chsh -s $(which zsh)
安装ohmyzsh
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
配置zsh
# zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting
# zsh-autosuggestions
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
#
git clone https://github.com/thinkgos/minority.git .minority
# 软链接
ln -s ~/.minority/zshrc/.zshrc ~/.zshrc
ln -s ~/.minority/vim/.vimrc ~/.vimrc
ln -s ~/.minority/zshrc/starship.toml ~/.config/starship.toml
ln -s ~/.minority/minority/zellij ~/.config/zellij
安装rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
[source.crates-io]
registry = "https://github.com/rust-lang/crates.io-index"
replace-with = "ustc"
[source.ustc]
registry = "git://mirrors.ustc.edu.cn/crates.io-index"
[registries.ustc]
index = "https://mirrors.ustc.edu.cn/crates.io-index"
[build]
rustc-wrapper = ".cargo/bin/sccache"
[target.x86_64-unknown-linux-gnu]
linker = "clang"
rustflags = ["-C", "link-arg=-fuse-ld=/usr/local/bin/mold"]
安装go
使用goup安装
配置 .zshenv
# goup
. "$HOME/.goup/env"
# go
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin
配置代理
go env -w GOPROXY=https://goproxy.cn,direct
Link
1. tcp 三次握手, tcp头部
2. micro services
3. algorithm
音视频
SIP
RTMP
RTSP
SRT
RTP
SDP
session description protocol, 会话描述协议, 媒体协商
STUN
session traversal utilities for NAT, NAT会话穿越应用程序, 网络信息交换, RFC5839
TURN
traversal using relays around NAT, RFC5839扩展, 主要添加relay功能, 如果nat后, 与对等无法建立通信, 则需要公网服务器做中继
ICE
STUN+TURN的一个信令服务器
SSDP
Simple Service Discovery Protocol, 简单服务发现协议
ONVIF
GB28181
SDP
SDP协议是会话描述协议(Session Description Protocol)的缩写, 是一种会话描述格式, 一种描述流媒体初始化参数的格式, 为描述多媒体数据而设计.SDP协议完全是一种会话描述格式. SDP协议是文本形式, 采用UTF-8编码的ISO 10646字符集
SDP协议不支持会话内容或媒体编码的协商(SDP协议只是描述信息而不能协商的去更改信息), 所以在流媒体中只用来描述媒体信息, 媒体协商需要其它协议来完成.
SDP协议描述符
①会话名和目的 ②会话激活的时间区段 ③构成会话的媒体信息(主叫和被叫的信息) ④接收这些媒体所需要的信息(地址, 端口, 格式) ⑤会话所用的宽带信息 ⑥会话负责人的联系信息 ⑦媒体信息(包括:媒体类型(视频, 音频等)、传送协议(RTP/UDP/IP H.320等)、媒体格式(H,264视频, MPEG视频等)、媒体地址和端口).
SDP格式
一个SDP会话描述包括若干行type=value形式的文本.
type: 该字节为单字节(如: v, o, m等)且区分大小写value: 为结构化文本的文本, 格式由type而定, 通常由若干分割符隔开的字段组成或者是一个字符串, 整个协议文本区分大小写.=: 等号两侧不允许有空格.
# <类型>=<值>
<type>=<value> [CRLF] # (CRLF表示换行)
SDP整体结构
SDP由一个会话级描述(session level description)和多个媒体级描述(media level description)组成.
- 会话级描述的作用域是整个会话, 在
SDP中, 从 “v=” 行开始到第一个 “m=” 行之前都是属于会话级描述的内容. - 媒体级描述对某个媒体流的内容进行描述, 例如某个音频流或者某个视频流, 从某个 “m=” 行开始到下个 “m=” 行之前是属于一个媒体级描述的内容.
[下面带*号的是可选的, 其余的是必须的. 一般顺序也按照下面的顺序来排列. a=*是sdp协议扩展属性定义, 除上面以外的, 分解时其它的都可以扔掉. a=charset属性指定协议使用的字符集. 一般的是ISO-10646.]
Session description # 会话描述
v= (protocol version) # 协议版本
o= (originator and session identifier) # 发起者和会话标识符
s= (session name) # 会话名称
i=* (session information) # 会话信息
u=* (URI of description) # URI描述
e=* (email address) # email地址
p=* (phone number) # 电话号码
c=* (connection information - not required if included in all media) # 连接信息 ― 如果包含在所有媒体中, 则不需要该字段
b=* (zero or more bandwidth information lines) # 零或多个带宽信息行
One or more time descriptions ("t=" and "r=" lines, see below) # 零或多个时间描述行
z=* (time zone adjustments) # 时区调整
k=* (encryption key) # 加密密钥
a=* (zero or more session attribute lines) # 零或多个会话属性行
Zero or more media descriptions # 零或多个媒体描述
Time description # 时间描述
t= (time the session is active) # 会话活动时间
r=* (zero or more repeat times) # 零或多个重复时间
Media description, if present # 媒体描述, 如果有
m= (media name and transport address) # 媒体名称和传输地址
i=* (media title) # 媒体标题
c=* (connection information - optional if included at session-level) # 连接信息 — 如果包含在会话层则该字段可选
b=* (zero or more bandwidth information lines) # 带宽信息
k=* (encryption key) # 加密密钥
a=* (zero or more media attribute lines) # 零或多个会话属性行
v: protocol version(必选)
v的含义是SDP协议的版本号,目前v都是0。
o: originator and session identifier(必选)
会话所有者有关的参数
username: 会话发起者的名称。如果不提供则用“-“表示,用户名不能包含空格;session-id: 主叫方的会话标识符, 在整个会话中同必须唯一.session-version: 会话版本号,一般为 0;nettype: 网络类型,目前仅使用IN来表示Internet网络类型;addrtype: 地址类型,可以是IPV4和IPV6两种地址类型;unicast-address:会话发起者的IP地址;
s: session name(必选)
本次会话的标题或会话的名称, 没有的话使用-代替.
i: session information(可选)
会话信息, 建议包括进来用于描述相应会话文字性说明.
u: URI of description(可选)
url的描述信息.
e: email address(可选)
邮件地址.
p: phone number(可选)
电话号码.
c: connection information - not required if included in all media(可选)
媒体连接信息
c=<networktype> <address type> <connection address>
<network type>: 网络类型,一般为IN, 表示”internet”<address type>: 地址类型,一般为IP4。<connection address>: 应用程序必须处理域名和ip地址两种情形。单播时,为域名或IP地址,推荐使用域名;多播,为IP地址,且IP后面必须有TTL(取值范围是0-255),地址和TTL决定了多播包被传播的范围。
b: zero or more bandwidth information lines(可选)
One or more time descriptions
一或多个时间描述, 描述了会话的开始时间和结束时间。这个可以有行,指定多个不规则时间段,如果是规则的时间段,则r=属性可以使用
t: time the session is active(必选)
会话的起始时间和结束时间(Time session starts and stops),如果没有规定这两个时间的话,都写为 0 即可。
r: zero or more repeat times(可选)
重复次数, r=<repeat-interval> <active duration> <offsets from start-time>
z: time zone adjustments
k: encryption key
a: zero or more session attribute lines
Zero or more media descriptions
媒体描述, 如果有
m: media name and transport address(必选)
媒体名称和传输地址, m=<media> <port>[/<number of ports>] <transport> <fmt list>
i: media title(可选)
媒体标题
c: connection information - optional if included at session-level(可选)
连接信息
b: zero or more bandwidth information lines(可选)
带宽信息, b=<bwtype>:<bandwidth-value>
k: encryption key(可选)
加密密钥
a: zero or more media attribute lines(可选)
零或多个会话属性行